




Pagesource에 명시적으로 드러나지 않은 정보의 크롤링
318
작성한 질문수 1
안녕하세요. 강의를 듣다가 제가 원하는 내용을 정확히 찾지 못해 문의드립니다.
현재 제가 크롤링하고싶은 데이터가 pagesource에 명시적으로 나오지 않는데요, 이러한 데이터입니다.
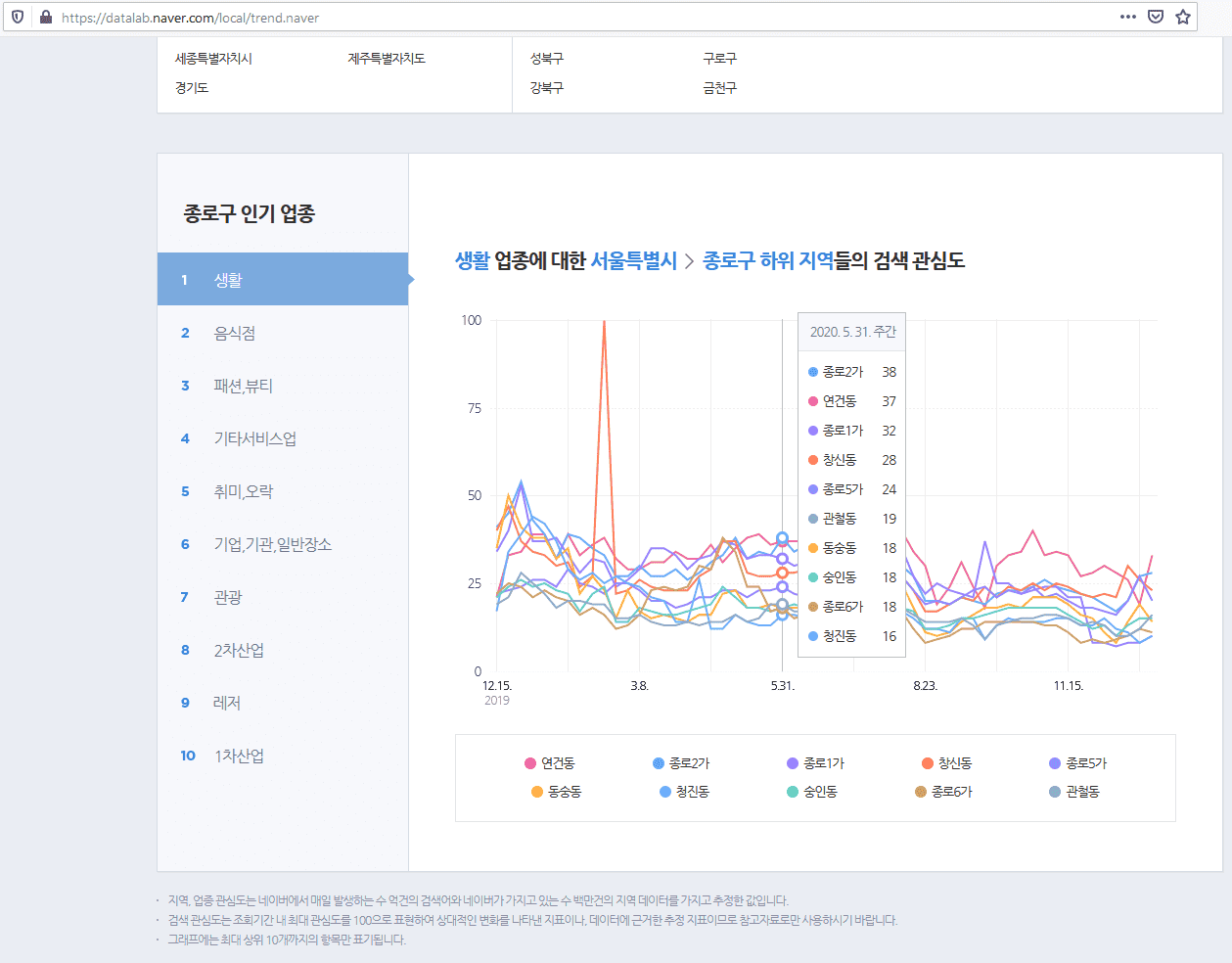
url은 https://datalab.naver.com/local/trend.naver 인데요, 저렇게 마우스를 가져다대면 나오는 숫자들을 날짜와 함께 크롤링하고 싶습니다. 그런데 문제는 pagesource를 봐도 저런 숫자들이 어떤 태그 아래 저장되어 있는지 나오지 않네요. ctrl+f로 검색해보니 "연건동"같은 string은 아예 등장하지도 않구요. 이런 데이터를 크롤링하기 위해서 참고할 수 있는 강의가 있을까요?
답변 4
1
넵 다음 글은 이후에 이어지는 글인데... 검색 방법이나, 궁금한 부분들을 찾을 수 있는 팁을 넣은 것인데, 유의사항도 함께 넣은 것이긴 하네요. 추가로 본 강의의 선수 강의인 파이썬 입문과 크롤링 부트캠프 에서 naver open API 사용법을 설명드렸고, 본 강의에서 naver open API 를 scrapy 와 함께 사용하는 케이스도 설명드렸는데요. naver open API 중에 데이터랩 과 쇼핑 인사이트 데이터를 가져올 수 있는 API를 다음과 같이 제공합니다. 강의 내의 설명을 통해 Open API 사용법을 익힌 후, 다음 API 에 적용해서 이를 사용해보셔도 좋을 것 같고요. Open API 는 제공하는 정보 이외의 추가적인 정보를 가져올 수는 없지만, 제공하는 정보는 확실히 공식적인 방법으로 가져올 수 있기 때문에, 참고하시면 좋을 것 같습니다.
https://developers.naver.com/docs/datalab/search/
감사합니다.
0
안녕하세요. 관련 그래프는 javascript 등, 완전히 다른 언어로 되어 있을 가능성이 높아보입니다. 그래서, 저런 데이터를 뽑으려면 관련 언어도 이해해야 하고, 경우에 따라서는 하나의 프로그램 안에서 처리가 되기 때문에, 크롤링은 불가능할 수도 있습니다. 네이버 데이터쪽은 naver open API 를 사용할 수도 있을 것 같습니다.
코딩을 잘 따라 한 것 같은데 오류가 발생하는 것 같습니다
0
648
1
scrapy를 jupyter 환경에서 할 수 있나요
0
372
1
[실전 크롤링: scrapy 크롤링 팁] 질문있습니다.
0
326
1
[실전 크롤링: 지마켓 크롤링하며, scrapy 실전 활용법 익히기1] 5분50초쯤 질문
0
233
1
[강력/최신 크롤링 기술: Scrapy 로 지마켓 크롤링하기1] 관련 질문
0
289
1
xml을 parsing할때 <을 < 로 인식합니다.
0
342
1
pipelines.py에서 process_item내에서 print문이 작동을 하지 않네요 ㅠ
0
297
3
PhantomJS 문의
0
309
1
selenium 문의
0
337
1
브라우저 제어해서 크롤링하기 - 처음강의 마지막부분 문의
0
3015
1
on error 해결 방법 질문
0
366
1
[팁] 윈도우 cmd 커맨드
0
356
1
[팁]Chrome User Agent 아는법
0
335
1
실전 크롤링: 브라우저를 제어해서 트위터 사이트 로그인 하기 질문
0
259
1
동영상 강의 만드실 때 사용한 툴을 알려주실 수 있을까요?
0
253
1
CSS Selector 에서 질문이 있습니다.
0
449
2
pip install scrapy 오류
0
499
1
셀레니움 실행불가
0
1593
1
실전 크롤링: XPATH와 Selenium 활용해서 페이스북 로그인 하기 에서 질문이 있습니다.
0
233
1
언제 get_text()를 사용하고 또 언제 .text를 사용하나요?
0
301
1
강의교안자료 받을수있을까요?
0
272
1
[강의 9:27관련 질문] price, title 열 위치
0
163
1
div에 있는 클래스가 2개이면 어떻게 하나요?
0
375
1
css 셀렉터에 대해 질문이 있습니다.
0
157
1