
Bắt đầu phân tích dữ liệu Python với dữ liệu công khai
Có tin đồn rằng Ediya sẽ mở một cửa hàng gần Starbucks. Vị trí cửa hàng của Ediya và Starbucks khác nhau như thế nào? Liệu xu hướng biến động giá bất động sản từ năm 2013 – 2019 có được phản ánh vào giá bán căn hộ? Có những công viên nào trong khu phố của chúng tôi? Làm cách nào chúng tôi có thể sử dụng dữ liệu trong cổng dữ liệu công cộng? Mục tiêu là xử lý nhiều loại dữ liệu khác nhau thông qua dữ liệu công cộng và làm quen với Python cũng như các thư viện phân tích dữ liệu khác nhau.
6,347 học viên
Độ khó Cơ bản
Thời gian Không giới hạn

[Thông báo sắp xếp lại] Tất cả nội dung của Bắt đầu với Phân tích dữ liệu Python với Dữ liệu công khai đã được thay đổi hoàn toàn. (5 giờ 33 phút trước =>13 giờ 52 phút)
Xin chào.
📊 Bài giảng về bắt đầu phân tích dữ liệu Python với dữ liệu công khai đã được đổi mới hoàn toàn .
Tiếp theo Chương 1 đến Chương 4, khóa học đã được tổ chức lại để tập trung vào tiền xử lý dữ liệu trong [Chương 5 Phân tích dữ liệu tiêu chuẩn của Công viên đô thị].
✍🏻Tất cả mã và video đã được viết lại .
📈[Chương 5] Nội dung tiền xử lý dữ liệu đã được bổ sung đáng kể từ 55 phút hiện tại lên 217 phút .
# Dữ liệu tiêu chuẩn của công viên thành phố yêu cầu xử lý trước dữ liệu khác nhau như giá trị bị thiếu, giá trị ngoại lệ, giá trị lỗi, ngày tháng, v.v., vì vậy tôi nghĩ nó phù hợp cho những ai muốn tìm hiểu cách xử lý trước thông qua dữ liệu thực.
# Một phương pháp tạo báo cáo bằng Pandas Profiling, cho phép phân tích thống kê kỹ thuật dễ dàng và mạnh mẽ bằng nhiều thư viện khác nhau, đã được thêm vào.
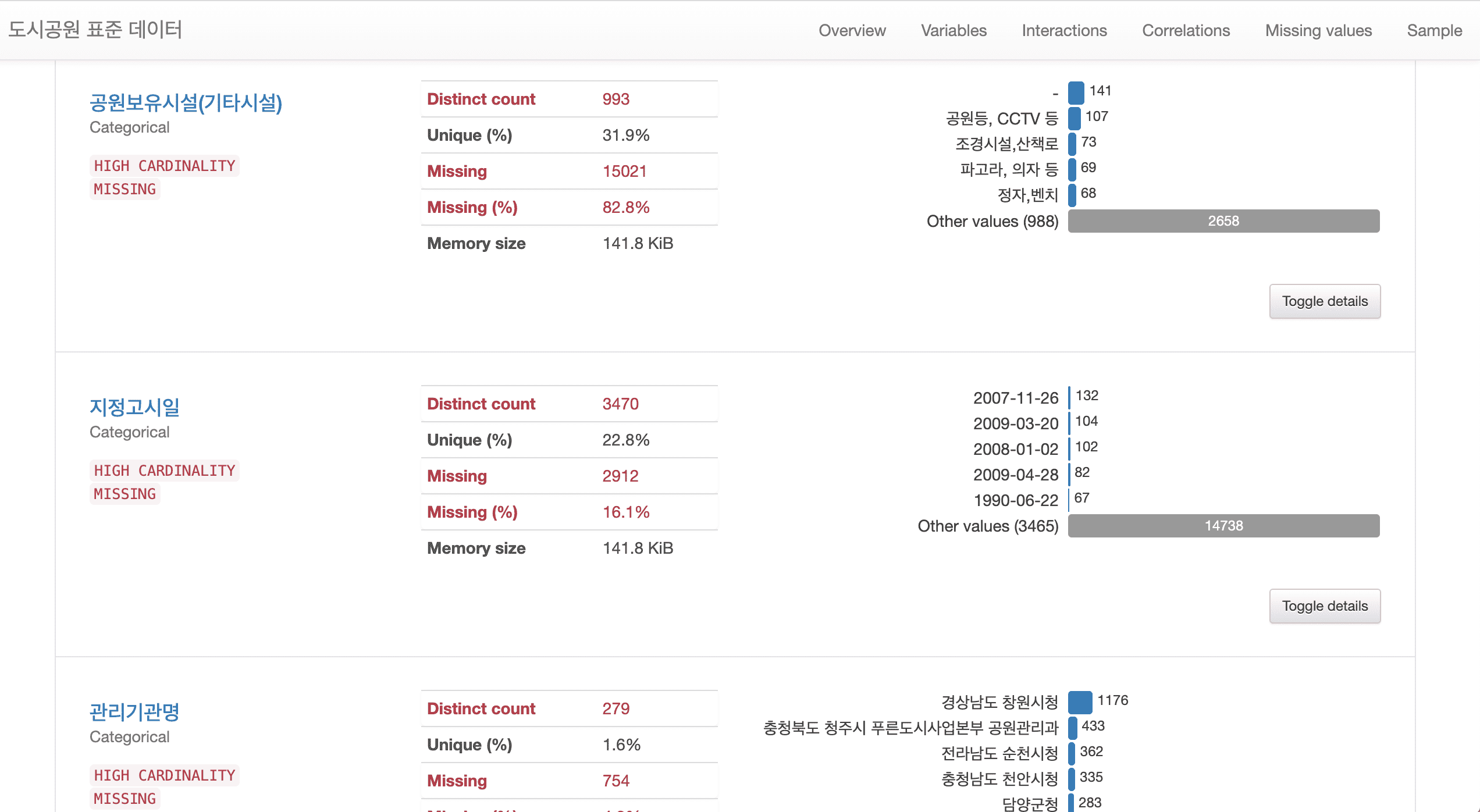
# Một phương pháp xử lý trước dữ liệu văn bản bằng cách sử dụng biểu thức thông thường đã được thêm vào. Ngoài ra, dữ liệu văn bản được hiển thị theo nhiều cách khác nhau.

# Các kỹ thuật che giấu thông tin cần thiết để bảo vệ thông tin cá nhân đã được thêm vào.
Trong bài giảng phân tích sự phân bố của các công viên đô thị hiện có, chúng tôi đã bổ sung đáng kể nội dung về các kỹ thuật khác nhau thường gặp trong công tác tiền xử lý.
Đặc biệt, nội dung mới đã được thêm vào để bạn có thể tìm hiểu về quá trình tiền xử lý và phân tích văn bản bằng cách sử dụng biểu thức chính quy .

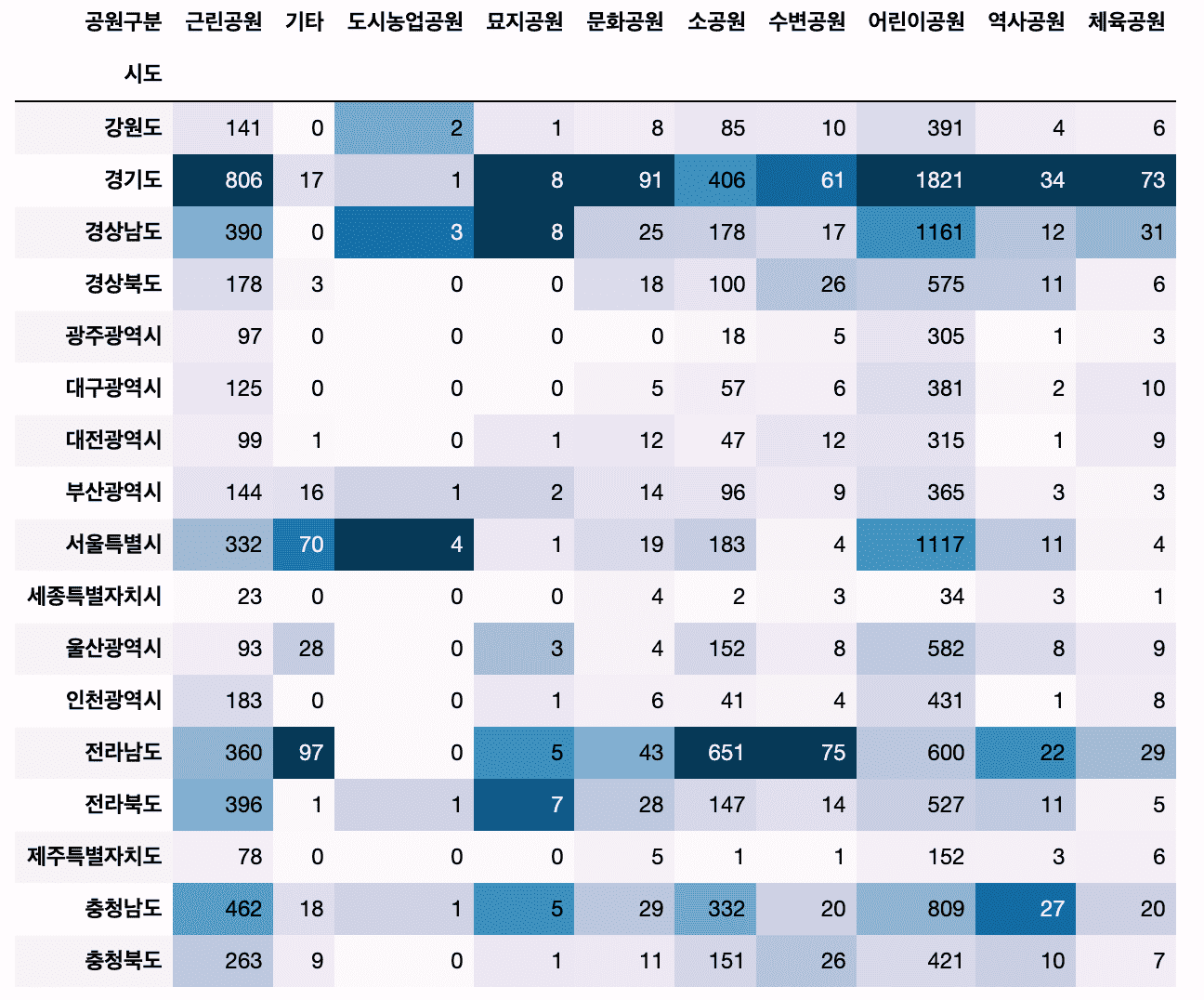
# Một phương pháp để lập bảng chéo giữa dữ liệu phân loại và phân loại thông qua bảng chéo đã được thêm vào.
Ngoài ra, chúng tôi sẽ sử dụng chức năng tạo kiểu của Pandas để thể hiện màu sắc trong khung dữ liệu mà không cần trực quan hóa.
# Hãy thử những ứng dụng đa dạng hơn của kỹ thuật trực quan.
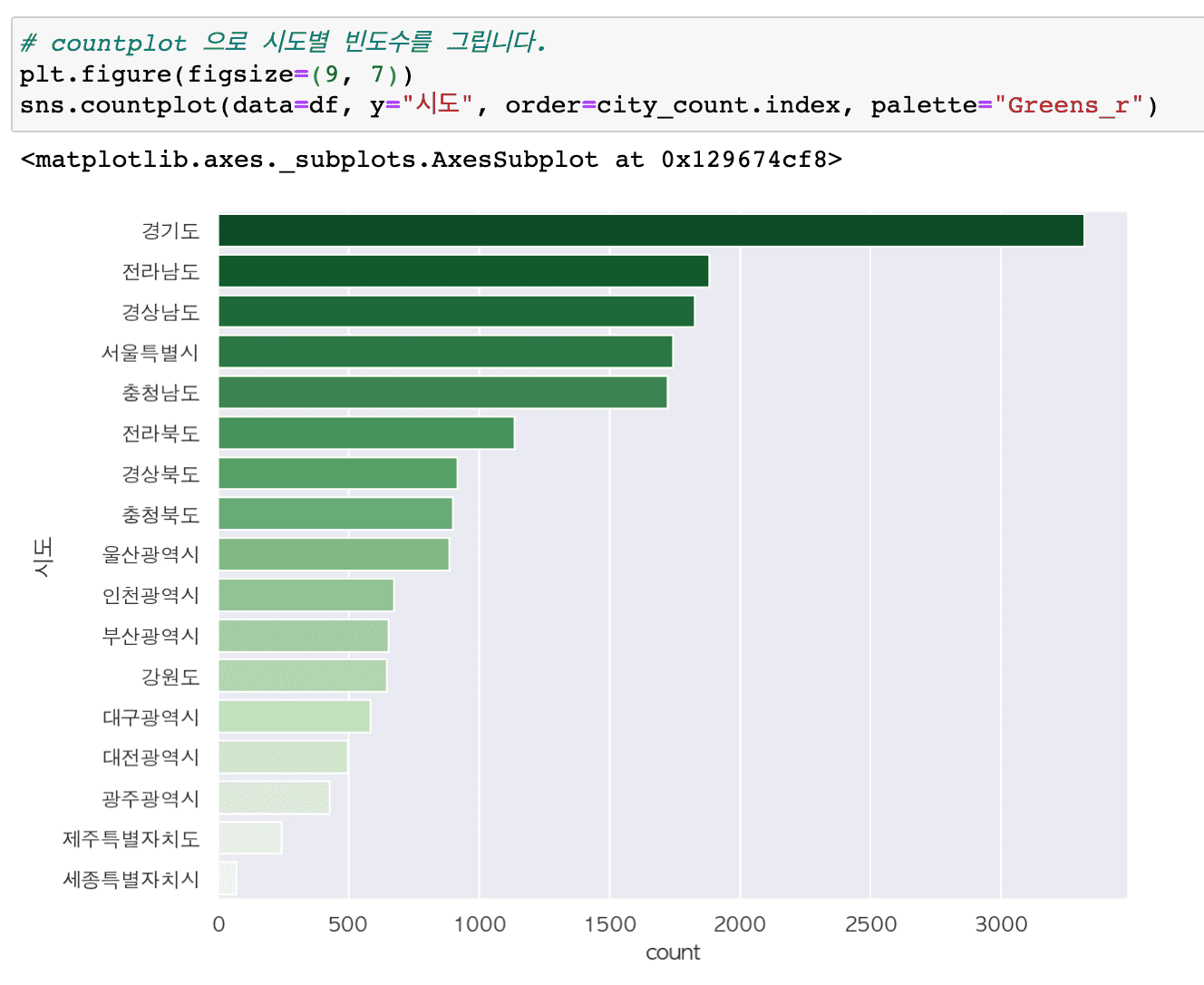
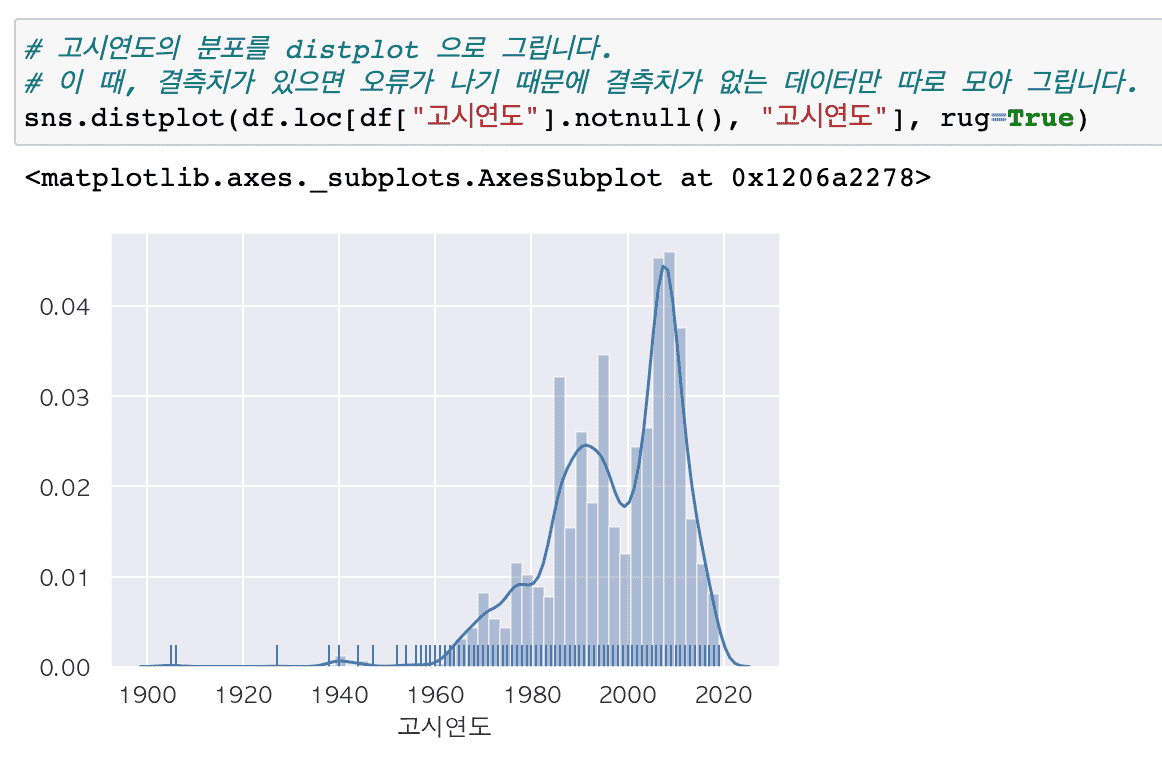
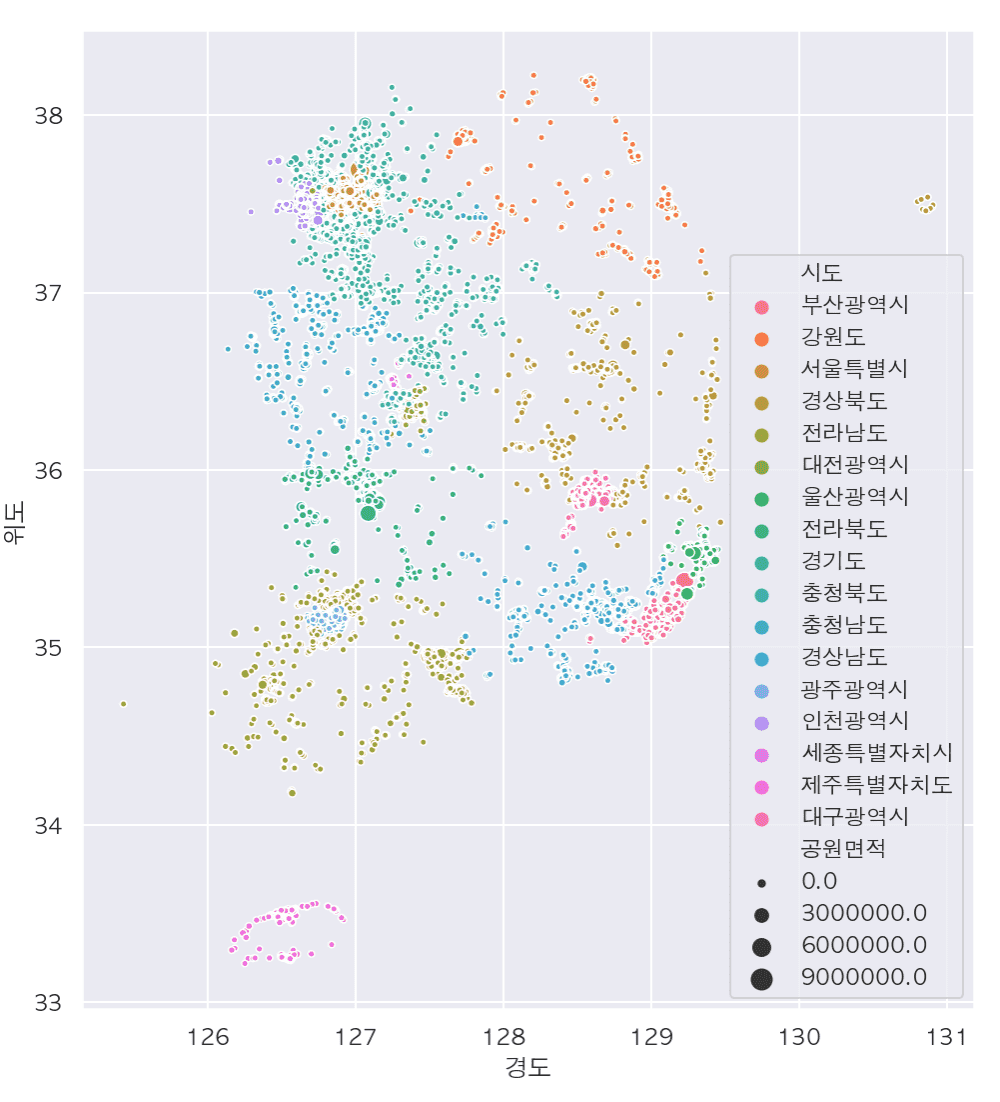
Tổng hợp các cập nhật lớn
#PandasHồ sơ
- Tạo các báo cáo thống kê mô tả khác nhau về tất cả dữ liệu bằng một dòng mã
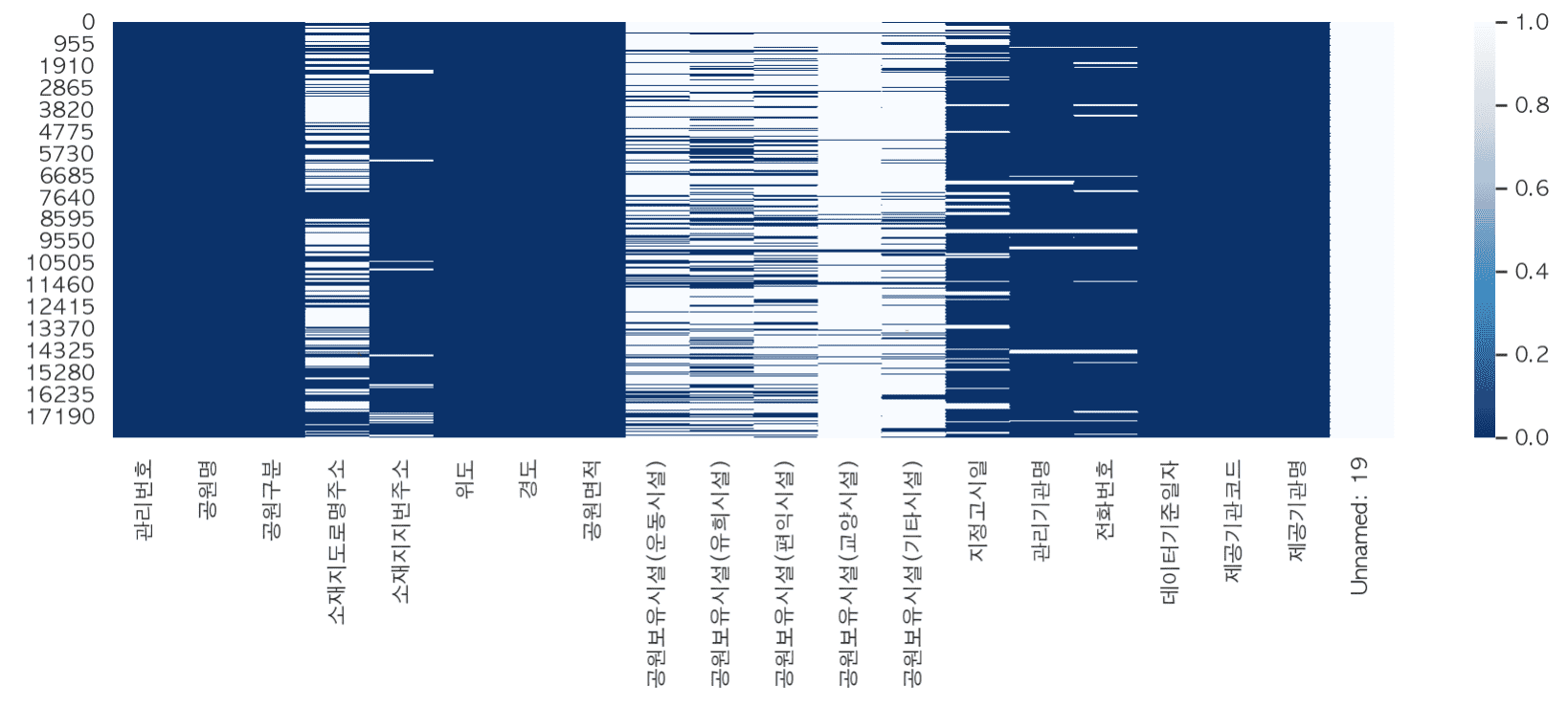
# Cần xử lý trước nhiều dữ liệu khác nhau để thực hành
- Tạo biến dẫn xuất
- Thay thế các giá trị còn thiếu
- Tìm và xử lý các giá trị ngoại lệ và lỗi
- Thay đổi kiểu dữ liệu
# Xử lý dữ liệu văn bản bằng biểu thức chính quy
- Chỉ nhập dữ liệu bạn muốn
- Chỉ trích xuất các từ khóa từ các loại văn bản khác nhau và đếm tần suất của chúng
- Vẽ một đám mây từ
- Tạo các hàm tiền xử lý dữ liệu văn bản để tái sử dụng code
- Che giấu thông tin: Tìm và che giấu các mẫu thông tin cá nhân, số điện thoại, email và số đăng ký xe.
# Biến số và biến phân loại
- Tìm các biến số và phân loại theo kiểu dữ liệu
- Sử dụng Pivot_table và Crosstab
# Tìm các công viên xung quanh tôi và thể hiện chúng trên bản đồ
- Tiền xử lý và hiển thị dữ liệu thông qua folium
Nếu bạn để lại một đánh giá tốt về khóa học, nó sẽ giúp ích rất nhiều cho việc cải tiến và cải thiện khóa học!
Cảm ơn
