
복습을 하면서 궁금증이 생겨서 올립니다. RMSLE 적용시, -1보다 작은 음수값을 수학적으로 대입할 수 없는데.,..
evaluate_regr(y_test, pred)
에 test데이터 세트와 예측 값을 넣는데,
y_test의 경우
y_test[y_test < -1] 에 해당하는 값이 없기 때문에, np.log1p에 대입할 수 있지만,
pred[pred < -1]에 해당하는 값은 존재하기 때문에, 예측값이 -1이보다 작은 경우에는 np.log1p에 대입할 수 없다고 생각합니다.
그래서, mean_squared_log_error를 호출하여 squared = False로 계산을 하였더니,
ValueError: Mean Squared Logarithmic Error cannot be used when targets contain negative values.
라고 오류가 뜨더라구요.
결국 -1보다 작은 음수값을 대입할 수 없다는 수학적 오류 때문이겠지요...
하지만, 선생님께서 하신 RMSLE
def rmsle(y, pred): log_y = np.log1p(y) log_pred = np.log1p(pred) ## log1p 랑 expm1은 하나의 쌍임. squared_error = (log_y - log_pred) ** 2 rmsle = np.sqrt(np.mean(squared_error)) return rmsle
를 활용한다면 오류가 뜨지 않는데,
제가 생각하는 방식에는 어떤 문제점이 있을까요?
Câu trả lời 4
0
감사합니다. RMSLE를 사용할 때에는 series로 입력을 해야되는군요.
저는 선생님께서 사용하지 않으신다던 mean_squared_log_error를 사용해보려고 하다가 이러한 오류를 발견하게 되었네요.
복습 열심히 해서 캐글강의까지 듣도록 하겠습니다 ^^
0
예측 값에 대해서
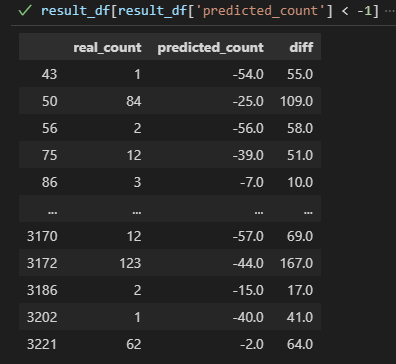
pred[pred < -1]로 확인을 해보니,
-1보다 작은 값들이 존재하고, rmsle를 정의하실 때, 이 부분에서 먼저 오류가 나와야 하는 것이 아닌가 생각이 됩니다.
예측값이 횟수이기 때문에 오류가 나오지 않는 다라는 것은 이해가 갑니다.
하지만, pred[pred < -1] 결과가 -1보다 작은 값들이 나오는데,
pred = lr_reg.predict(X_test)와 같이 선형회귀 방식으로 예측한 결과값(pred)에 대해서 오류가 있는 걸까요?
1
확인해 본 결과 y_test 값이 Series로 입력이 되는 군요. Series의 경우 np.mean 처리시에 nan 값이 제외되고 연산이 되는 군요.
log1p(pred)에서 pred가 -1 보다 작은 음수값은 모두 nan이 됩니다.
그런데 rmsle(y, pred)에서 log_y는 y값이 Series라 Series가 되고, squared_error도 Series가 됩니다. 그런데 여기에 np.mean(squared_error)를 수행하면 nan 값들은 제외가 되고 평균값을 구하게 됩니다.
아래와 같이 y_test를 Series가 아닌 array로 입력하게 되면 RSMLE는 nan 값이 됩니다.
evaluate_regr(np.array(y_test) ,pred)
y_test값을 Series가 아니라 array로 입력하는 게 원칙적으로는 더 정확할 것 같습니다. 다만 pred 가 -1보다 작아지는 경우에 RMSLE를 계산하려면 기존대로 Series값을 넣으면 좋을 것 같습니다.
저도 한수 배웠습니다. 좋은 질문 감사합니다.
0
안녕하십니까,
말씀하신 내용이 맞습니다.
자전거 대여 예측은 대여 횟수를 예측하기 때문에 학습 데이터도 0보다 크고, 예측데이터도 모두 0보다 큰 값이 나와서 문제가 발생하지 않았습니다.
Log 계열 평가지표를 사용할 때는 실제값과 예측값이 모두 0보다 큰값이 나오는지 먼저 확인해 줘야 합니다.
감사합니다.
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
57
2
안녕하세요 열심히 수강중인 학생입니다
0
96
2
정수 인덱싱
0
89
2
넘파이 오류
0
119
2
11강 numpy의 axis 축 질문 드립니다.
0
111
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
100
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
85
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
84
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
77
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
82
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
84
3
파이썬 다운그레이 후 사이킷런 재설치
0
133
2
좋은 강의 감사합니다.
0
90
2
scoring 함수 음수값
0
81
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
109
2
분류 평가 정확도 예측
0
95
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
115
1
카카오톡 채널 있나요
0
121
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
197
2
pca 스케일링 관련하여 질문드립니다.
0
119
2
주피터 대신 구글 코랩
0
187
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
157
2
실루엣 스코어..
0
99
2