
MDP 행동가치함수에 대한 문의 입니다.
410
投稿した質問数 1

제일 아래 쪽 ? 부분이 정의에 의한 부분이 맞는 건지요?
설명하실때 왼쪽은 행동에 대한 합을 나타내고 오른쪽은 하나의 행동에 대해서라고 강의를 하셨는데 이 부분이 이해가 가질 않습니다.
回答 1
0
안녕하세요 강석원님.
제가 질문을 정확히 이해하지 못해 나름의 방식으로 답변을 드리겠습니다.
결론부터 말씀드리자면 강석원님이 말씀하신 마지막 수식은 틀린 수식입니다.
MDP에서 정책, 가치함수, 행동가치함수를 이해하는 것이 생각보다 좀 어렵습니다.
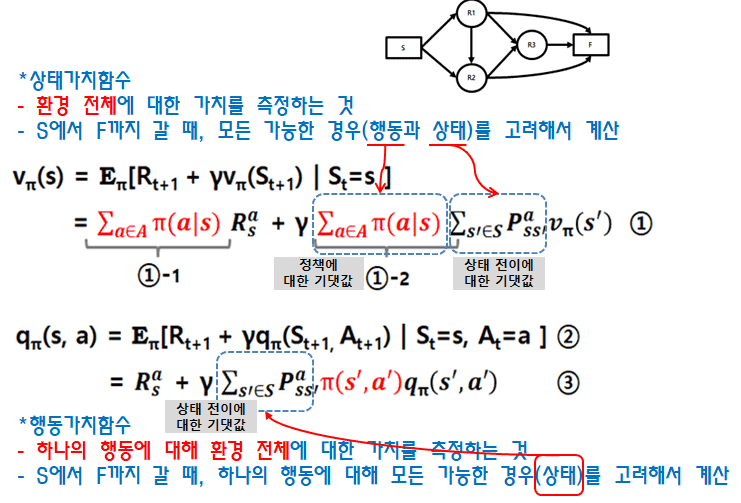
상태가치함수는 환경 전체에 대한 가치를 측정합니다. 라우팅 그림을 참고하시면 에이전트가 S에서 F까지 갈 때 취할 수 있는 모든 행동과 갈 수 있는 모든 상태를 고려해야 합니다. 그래서 수식 (1)-2에서 상태이동에 대한 확률P와 행동에 대한 확률 ㅠ(정책)을 모두 고려한 확률의 기대값을 구합니다.
반면 행동가치함수는 하나의 행동에 대한 가치를 측정합니다. 행동가치함수는 하나의 행동만을 고려하기 때문에 상태가치함수와 달리 모든 행동을 고려할 필요가 없이 하나의 행동만을 고려하면 됩니다.
이 개념을 가지고 수식을 다시 보시면 이해가 좀 더 쉽습니다.
감사합니다.
딥러닝 코드에 Batch Normalization 적용해보기 질문입니다
0
586
1
딥러닝으로 Regression 문제 적용해보기 (House Price Kaggle 문제) 질문입니다
0
485
1
Binary Classfication 딥러닝 적용해보기 질문입니다
0
369
1
파이토치 device (gpu / cpu) 관련 질문드립니다.
0
720
1
혹시 응용편은 어디서 볼 수 있을까요?
0
478
1
karting asset
0
451
2
using Unity.MLAgents; 오류
0
658
1
Augmentation 질문
1
394
1
cartpole_reinforce.ipynb 에러
0
547
2
DQN 알고리즘 실행 결과
0
370
1
DQN 코드 에러
0
504
1
DQN 질문
0
560
1
개발환경 구축관련 문의 드립니다.
0
242
1
MDP질문
0
216
1
MDP 질문
0
279
1
보상값과 보상함수
0
894
1
MDP 상태가치 함수에서 기대값 관련 질문 드립니다.
0
421
1
Reward 에 대한 질문 드립니다.
1
251
1
ppo에서 exploration을 어떻게 하는지 궁금합니다.
0
890
2
강의 외 질문입니다. Env 내부 action에 대한 질문입니다.
0
310
1
episode중간에 weight나 모델을 저장하고싶습니다.
0
951
2
action을 매 episode마다 출력하기위해서는 어떻게 해야하나요?
0
231
1
TypeError: in user code: TypeError: Can not convert a NoneType into a Tensor or Operation.
0
1058
5
cartpole_dqn 중 def train_mini_batch(self,Q):에서 Q[0,0,action]의 0,0의 의미는?
0
206
1