
이미 누군가가 질문을 하셨는데...
626
작성자 없음
投稿した質問数 0
回答 11
0
selenium 업그레이드됨... 문법도 바뀜
1
296
1
2024.08.28 수요일 기준 날씨 정보 가져오기 소스코드입니다 (참고하세요 : ) )
0
241
1
24년, 부동산 퀴즈 코드입니다. 참고하세요!!
0
190
1
git hub에 push할때 user-agent가 노출되도 상관이 없나요 ?
0
191
1
selenium 관련 web push notification 제어 질문
0
578
1
print(soup.a) 태그 값이 None으로 나옵니다.
0
1186
4
soup으로 검색한 버튼 또는 text를 click할때 어떻게 하나요 ?
1
3566
1
웹툰 사이트 body 안에가 안불러져옵니다.
0
681
2
네이버 웹툰을 활용한 BeautifulSoup 강좌에서 인터페이스가 달라졌습나다.
0
996
1
구글 무비 강좌에서요
0
400
0
네이버 IT뉴스 화면 requets.get 에러가 발생합니다ㅜ
0
437
0
23년 2월 7일, 다음 부동산 화면이 다름
0
413
0
네이버 항공권 관련 제가 작성한 코드 조심스럽게 공유해드립니다.ㅜ
7
2560
2
bs4 활용 2-1 질문합니다.
0
508
2
csv파일 깨짐
0
325
0
url 에러? (\UXXXXXXXX escape)
0
311
0
네이버 쇼핑으로 하면 왜 결과가 안 뜰까요?
0
384
0
쿠팡대신 네이버 쇼핑에서하는데, 5개 아이템만 나옵니다.
0
368
0
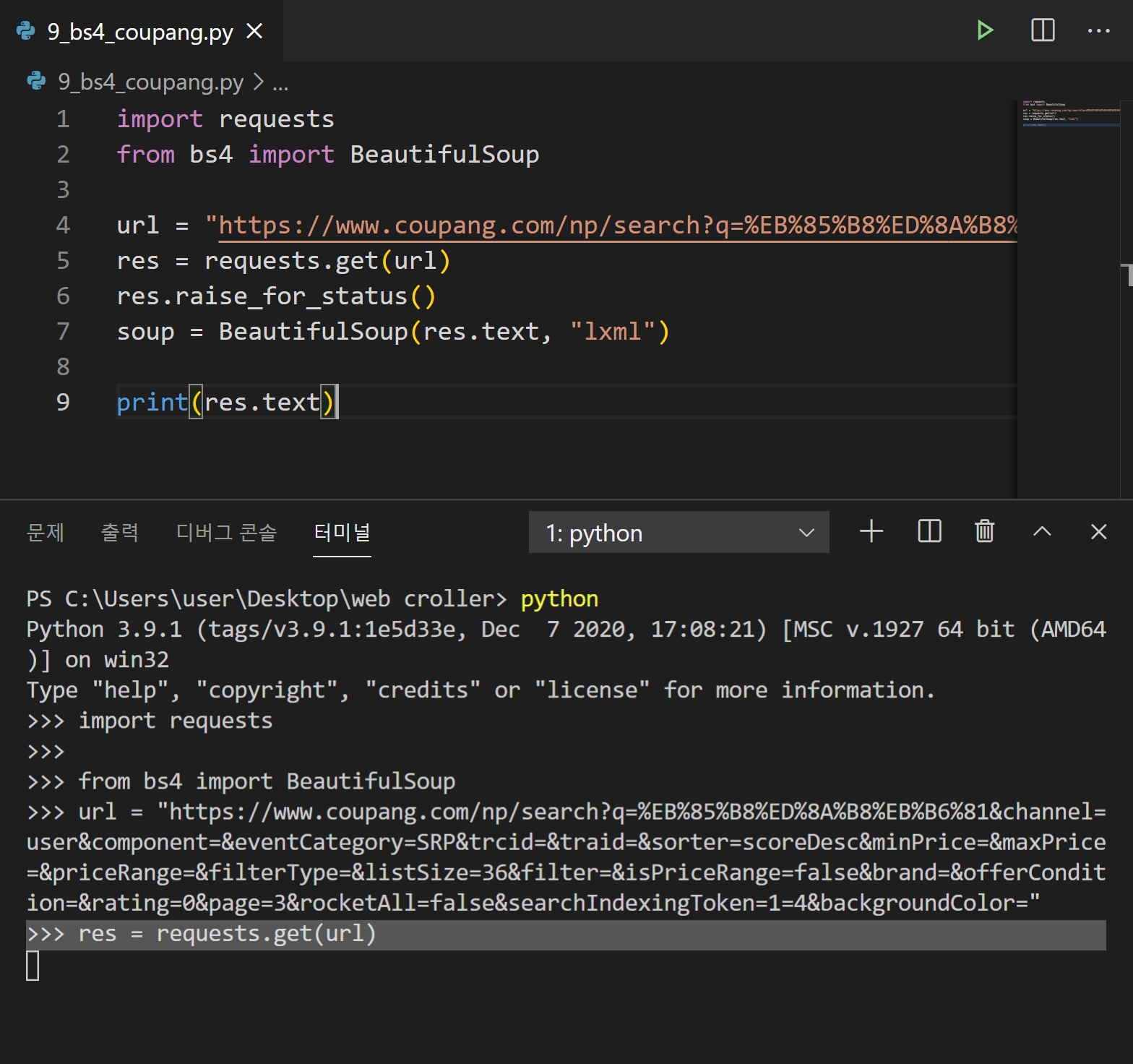
쿠팡 requests에 오류가 생기네요
0
2916
1
URL 문제
0
392
0
request 설치
0
322
0
from selenium import webdriver ?
0
354
1
네이버웹툰 랭크가 안불러져요...;;
0
303
0
안녕하세요 에러문의드려요
0
224
0