




Inflearn Community Q&A
asked

split() 함수 사용시 결과값이 잘못나오는 이유는 뭘까요?
Resolved
Written on
·
387
0
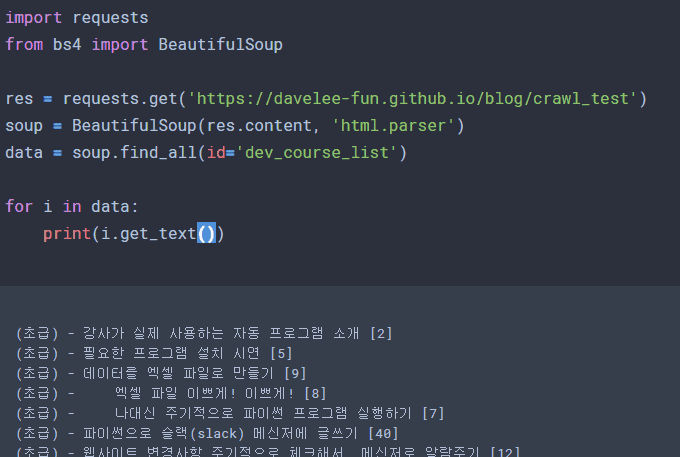
.split('[') 함수 사용시 결과 값이 틀린 이유는 뭘까요?

Answer 2
1
우선 코드를 보여주시려면, 제가 복사해서 테스트해볼 수 있을 정도는 되야 해요. 제가 직접 이미지를 놓고 모든 코드를 이미지를 보면서 직접 쳐봐야 테스트를 해봐야 한다면, 답변을 드리는데에도 시간이 많이 걸리고, 대충 답변을 드리면 그것도 문제가 있을 것 같아요.
말씀하신 코드는 id 가 dev_course_list 인 데이터를 통째로 가져왔기 때문에, 반복문을 한번밖에 돌지 않고, 데이터도 통째 데이터밖에 없는 상태로 보입니다. enumerate() 함수로 반복문 횟수를 가져올 수 있으니, 다음과 같이 써보시면 이해하실 수 있을 꺼예요.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content, 'html.parser')
data = soup.find_all(id='dev_course_list')
for num, i in enumerate(data):
print (num, i.get_text())
print (num, i.get_text().split('['))
0
캡쳐로 문의하면 그런 문제가 있었군요. 다음부터는 txt로 문의드리겠습니다. (죄송)
통째로 데이터를 가져온 상태라는 것에 대해 대충(?)은 이해 했습니다. ^^