




리트코드 1179 CASE WHEN , GROUP BY 관련 질문입니다
377
작성한 질문수 4
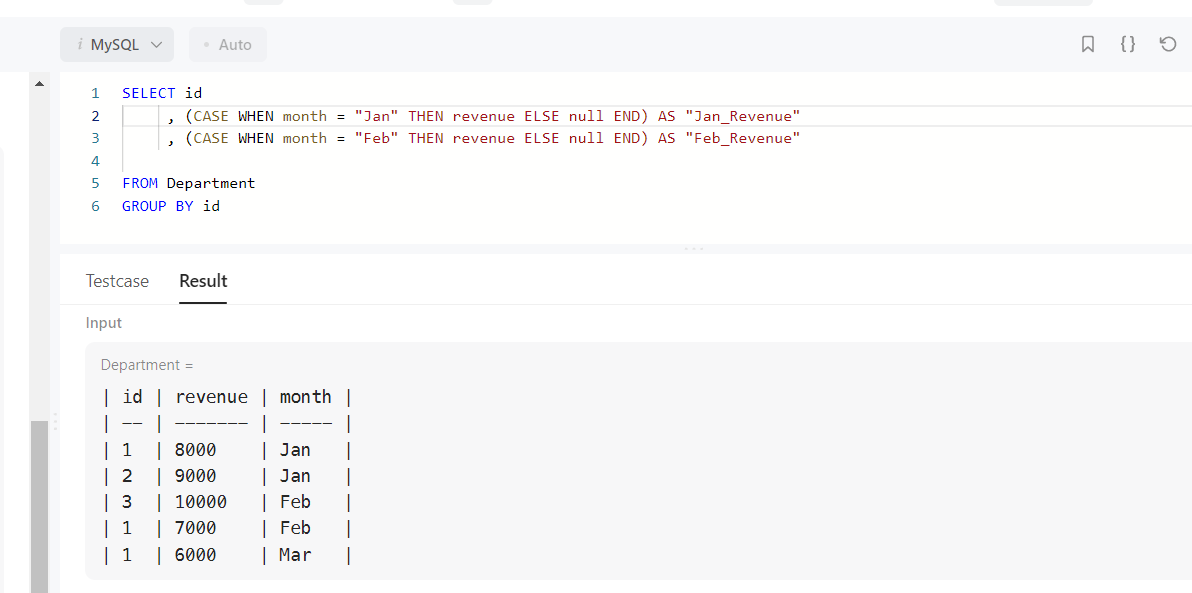 위의 코드는 제가 작성한 코드고요 돌려봤더니 틀린 코드입니다 (복잡해서 Jan,Feb 만 작성해서 보여드릴게요)
위의 코드는 제가 작성한 코드고요 돌려봤더니 틀린 코드입니다 (복잡해서 Jan,Feb 만 작성해서 보여드릴게요)
저 CASE 문 왼쪽에 SUM 을 붙이는게 강사님이 가르쳐준 답이었습니다
GROUP BY 를 왜 하는지, CASE WHEN 을 왜 쓰는지는 이해가 됩니다
하지만 이해가 안되는 부분이 있습니다.
문제에서는 분명 (id, month) 가 기본키라고 설명하고 있습니다
그 말은 즉 ,
예를 들어 id 가 1 이고 month 가 Feb 인 데이터는 단 하나라는 의미입니다
그렇게 되면 SUM 을 사용할 필요가 없지 않나요?
하지만 SUM 을 사용하지 않고 제 코드를 돌려보면 아래 사진의 X 표시를 한 두개의 데이터가 결과에 나오지 않습니다
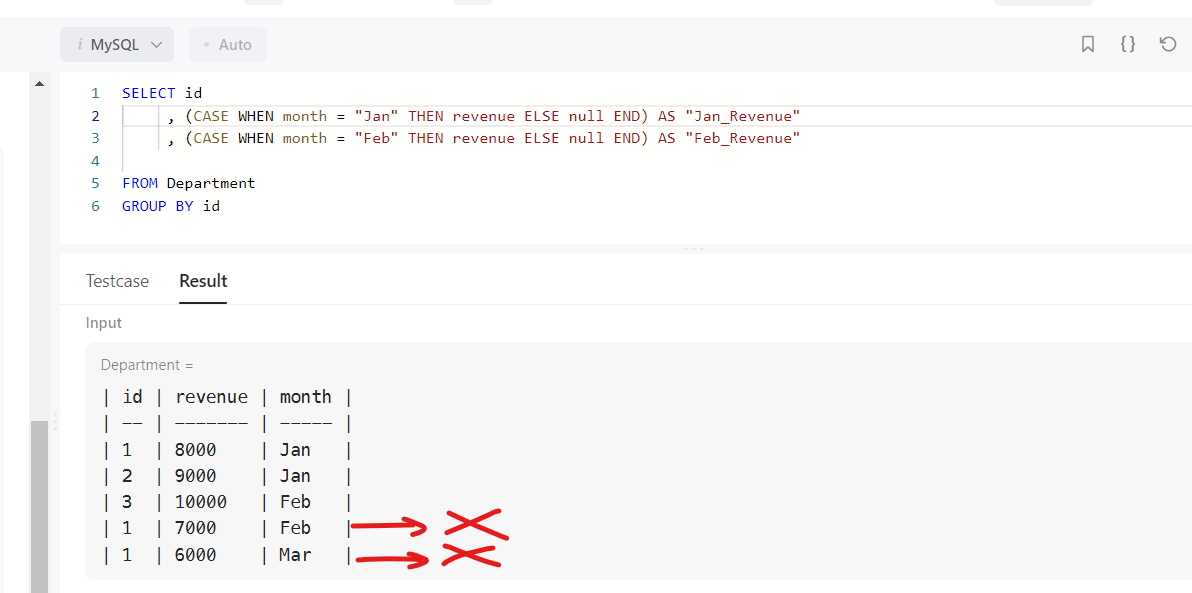
제 생각에는 SQL문이 GROUP BY 를 어떻게 처리하느냐에 대한 문제인거 같습니다
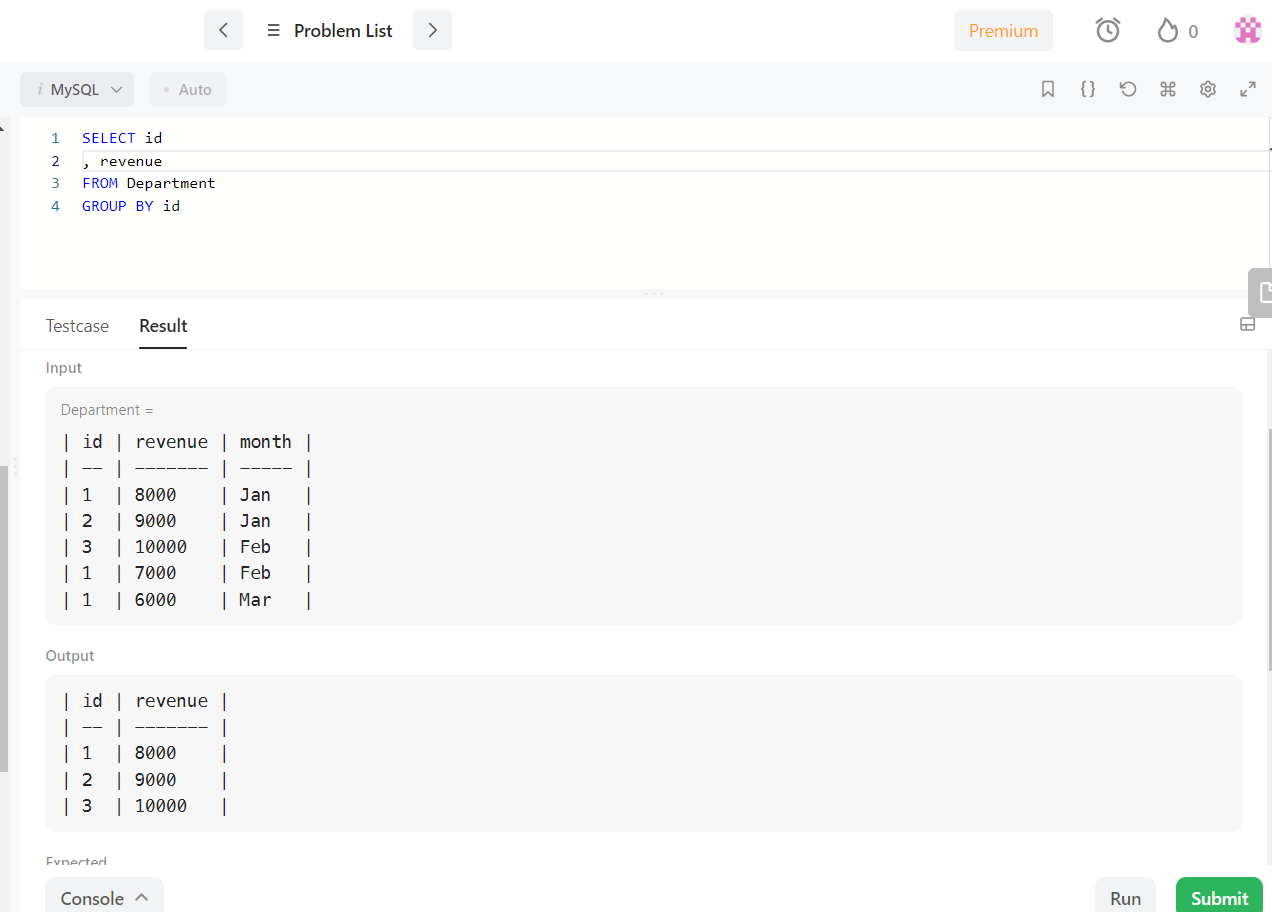 이런것 처럼 group by id 를 한 후 revenue 를 출력해보면 해당 id 그룹의 가장 첫 데이터만 가져오는 것과 연관이 있는 듯 합니다. 누구도 저 SQL문을 쓰면서 해당 id 그룹 중 가장 위에 있는 데이터의 revenue 값을 구하려는 사람은 없을텐데 저게 왜 오류가 안나는 코드인지도 모르겠고요
이런것 처럼 group by id 를 한 후 revenue 를 출력해보면 해당 id 그룹의 가장 첫 데이터만 가져오는 것과 연관이 있는 듯 합니다. 누구도 저 SQL문을 쓰면서 해당 id 그룹 중 가장 위에 있는 데이터의 revenue 값을 구하려는 사람은 없을텐데 저게 왜 오류가 안나는 코드인지도 모르겠고요
이거에 대해서 설명해주실 수 있을까요?
왜 리트코트 문제에서 SUM 을 붙여야만 하는지 이해가 안됩니다
답변 1
0
이 문제에서는 주어진 테이블을 피봇해 아래와 같은 형태의 output을 반환해야 합니다.
id | Jan_Revenue | Feb_Revenue
1 | ... | ...
2 | ... | ...
여기서는 id=1, month='Jan'인 데이터가 단 하나 뿐이지만 만약 여러 개라면, id=1인 row의 Jan_Revenue 컬럼값은 딱 한 자리인데, 여러 개의 값 중 무엇이 들어가야 할까요? 마음대로 하나 고르는 게 아니라 집계를 해야 합니다. 이런 경우 합계를 구하라던지(sum), 가장 큰 값을 구하라던지(max) 하는 지시가 문제에 주어집니다.
이 문제에서는 id=1, month='Jan'인 데이터가 하나이므로 이런 지시가 주어지진 않았지만, 사실 Jan_Revenue 자리에 들어갈 후보는 하나가 아니라 두 가지입니다. Jan_Revenue는 case when month = 'Jan' then revenue else null end 로 만들어진 컬럼이므로 우선 테이블의 각 row를 하나씩 체크하며 month 값에 따라 revenue 값, 또는 아무 것도 채우지 않는 것(null) 중 한 가지를 선택하게 되죠. 값들만 나열하면 아래와 같이 될 거에요.
[8000, null, null, ... ]
이들을 집계해 최종적으로 Jan_Revenue에 들어갈 값을 구해야 하는데, 여기서 숫자(revenue) 값은 딱 하나이고(id=1, month='Jan'인 데이터가 하나) 나머지는 null이므로 sum, max, min 등 어떤 집계함수를 사용하든 8000이라는 값을 가져올 수 있습니다.
결론은 group by를 사용해 피봇테이블을 만들 때는 집계함수가 꼭 필요하다는 것이고, 이번 문제와 같은 경우에는 sum 대신 다른 것을 집계함수를 사용해도 동일한 값을 반환합니다.
리트코드 1280. Students and Examinations
0
94
3
16강 LEFT JOIN 리트코드 (183. Customers Who Never Order) 관련 질문
0
103
2
African Cities 문제관련 질문
0
65
1
SQL 코딩테스트 질문
0
242
1
HACKER RANK에서 문제찾기
0
109
2
강의 자료 다운로드
0
101
2
Asian population 문제가 없어요
0
88
2
INNER JOIN 에서 A.키 쓸때 빨간 색 나오고 'dause'
0
77
2
별칭 관련해서 질문 있습니다.
0
88
2
rising temperature 문제 질문
0
109
2
해커랭크 TOP EARNERS 문제 질문
0
110
1
ON 뒤에 질문
0
106
2
INNER JOIN 질문. 강의와 결과값이 다릅니다.
0
211
3
END, 뒤에 * 붙이면 에러가 뜹니다
1
213
2
CustomerID가 중복되서 나타나요
0
242
3
별칭이 전체 테이블을 못 불러와요.
0
152
2
CASE WHEN 쿼리 오류 문의
1
342
3
CASE문제풀이 질문
0
133
1
Customers Who Never Order 풀다가 Alias관련 질문사항
0
141
1
Average Population 질문
0
143
1
Revising Aggregations - The Count Function 질문
0
110
1
Average Population of Each Continent 에대해서 질문
0
200
3
w3schools 에서 쿼리 작성 질문
0
167
1
INNER JOIN 할 때 NULL 값이 안보일 수도 있나요?
0
332
1