




후속 질문3 드립니다!
414
작성한 질문수 6
https://www.inflearn.com/questions/67575
의 후속 질문입니다.
항상 빠른 답변 너무나 감사드립니다!
파이썬 머신러닝 완벽 가이드 강의 분류 파트까지 듣고 캐글 advanced로 넘어왔는데,
이곳에서 질문 드리는게 더 적절할 것 같아 게시판을 옮겼습니다~
1. LightGBM으로 멀티 클래스 분류를 할 경우(target 클래스가 3개) eval_metric='auc_mu'을 사용하는 것이 맞나요? 또한 멀티 클래스 분류의 경우 재현율을 어떻게 봐야할지 모르겠습니다.
2. 피쳐 엔지니어링을 하면서 2개의 피쳐 간 상관계수가 1.0인 경우 1개의 피쳐를 drop해야 하나요? 만약 drop을 해야되는 경우(혹은 꼭 그렇지 않아도 되는 경우) 어떤 이유에서인지 궁금합니다.

3. target별 피쳐 분포도가 아래와 같은 경우 저는 해당 피쳐를 drop하는게 맞다고 생각했는데, drop한 경우 정확도가 0.01퍼센트 가량 하락했습니다. 이는 크게 우려할 만한 정도가 아닌가요? 혹은 본 피쳐를 살리는 것이 맞는걸까요?
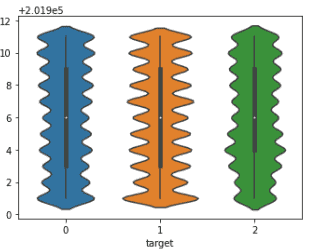
4. 2개의 피쳐(범주형)가 각각 대분류, 중분류로 나뉘어지고, 피쳐간의 상관관계도 0.8~0.9 정도로 높게 나타나는 경우 어떻게 처리하는 것이 좋은가요?
(예를들어, A 피쳐는 위험도별로 1군, 2군, 3군,
B 피쳐는 위험물질별로 a, b, c, d, e, f, g, h, i로 카테고리가 나뉘어질 때,
B 피쳐의 a, b, c는 A피쳐의 1군,
B피쳐의 d, e, f는 A피쳐의 2군,
B피쳐의 g, h, i는 A피쳐의 3군과 같은 형식으로 포함관계가 성립)
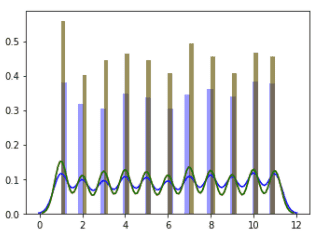
5. 아래처럼 피쳐간의 분포 모형이 비슷할 경우 .mean()을 활용하여 해당 피쳐의 영향을 극대화하는것도 괜찮은 방법일까요? 그리고 본 강의에서 .mean() 등을 활용하여 새롭게 피쳐를 추가했을 때, 원래 존재하던 개별 피쳐는 따로 drop하지 않던데 그 이유는 무엇인가요?
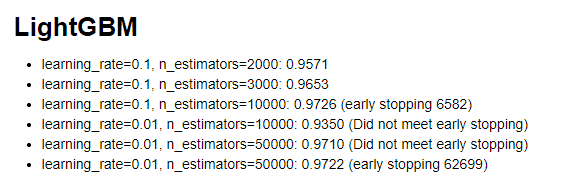
6. 저번 질문에 대한 답변을 듣고 n_estimators를 매우 높여본 결과 아래처럼 정확도가 나왔습니다.
(끝에서 2번째는 n_estimators=20000일 때인데 오타가 났습니다)
테스트를 진행하면서 궁금했던 점이 learning_rate를 줄이고 n_estimators를 늘리는 것이 모델 성능 향상에 큰 영향을 주는게 맞나? 라는 의문이 들었습니다. 혹시 이런 방법이 특히나 효과를 볼 수 있는 데이터셋이 따로 존재하는 것일까요?
8. LightGBM에서 F1 score를 평가 메트릭으로 사용하기 위해(주최측에서 macro f1 score를 평가지표로 활용한다고 발표) 아래처럼 메서드를 생성하여 학습을 진행하였는데, 이후 채점시 정확도가 10% 가량 하락했습니다. 여기서 세 가지 질문이 있습니다.
> 8-1. 아래처럼 커스텀하여 사용하는 것이 맞나요?

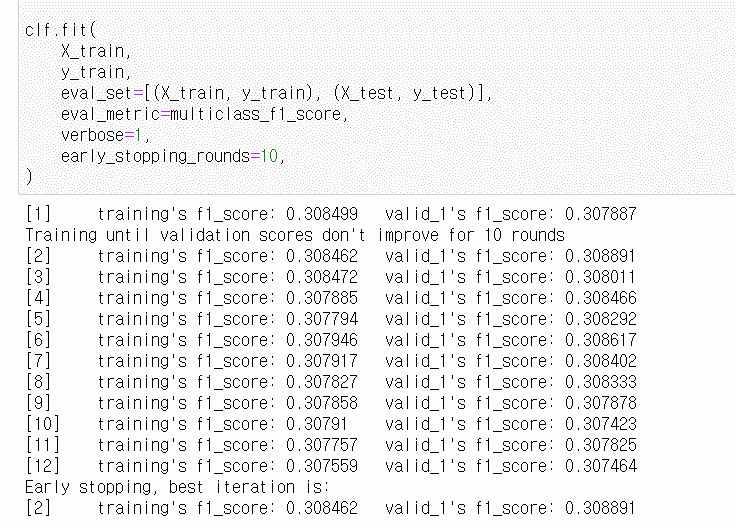
> 8-2. f1 score를 eval metric으로 변경할 경우 이후 LightGBM이 모델을 피팅할 때 f1 score를 향상시키는 방향으로 학습하는 것이 아닌가요? 왜 이렇게 낮은 정확도에서 early stopping이 발생하는지 이해가 되지 않습니다. (스크린샷에는 early_stopping_rounds=10이지만, 500으로 두고도 테스트해봤으나 별반 차이가 없었습니다)
> 8-3. 현재 제 문제(f1 score로 평가 메트릭 변경 후 학습시 정확도가 잘 오르지 않고, 최종 점수가 낮은 것)를 해석하면, 이전까지 logloss로 피팅한 모델은 비록 제출시 점수는 높더라도 우연이거나 과적합되었을 가능성이 높은 것으로 해석하면 될까요? 따라서 이제부터 f1 score로 피팅하면서 피쳐 엔지니어링을 좀더 신경쓰면 되는걸까요?
긴 질문 읽어주셔서 정말 감사드립니다!!!
답변 1
0
안녕하십니까,
아, 지금 특정 경연대회 문제에 참가하시고 계시는군요.
그런데 질문이 한 thread에 너무 많아서 제가 답변을 한꺼번에 드리기가 어렵군요. 다음 번에는 10개 정도의 질문이 있으면 3~4개 정도로 쪼개서 올려 주셨으면 합니다.
1. lightgbm에서 multi class roc-auc는 저도 해보진 않았지만 문서를 확인하니 말씀하신 auc-mu로 되어 있군요. multi class 재현율은 one-vs-rest 방식을 적용합니다. 즉 A, B, C 세개의 클래스가 있을 때 A이냐 아니냐, B이냐 아니냐, C이냐 아니냐를 3개의 recall 을 구한 뒤 이를 평균합니다. 이를 쉽게 구하는 방법으로 사이킷런의 recall_score()인자로 average를 이용하는 것입니다. macro또는 weighted 로 설정하면 됩니다. macro는 일반 평균 weighted는 클래스별 true값에 따라 가중치를 부여하여 평균을 적용합니다. 아래 문서 참조하셨으면 합니다.
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html
2. 삭제해서 성능이 떨어지면 drop 할 필요 없습니다. 만일 상관도가 높은 컬럼들이 많다면 삭제후 성능을 확인해볼 필요는 있습니다. 일반적으로 피처들이 매우 많은 경우 상관도가 높은 컬럼들이 많은 경우 다중 공선성등의 이유로 인하여 성능이 저하 될 수 있습니다.
3. 왜 떨어뜨려야 된다고 생각하신 건지요? 떨어뜨려서 성능이 저하되면 떨어뜨릴 필요는 없습니다.
만일 지금 어떤 경연대회에 참석하시고 있는 거라면 충분히 모델을 테스트 하신 후에 feature selection은 후반에 하시는 게 좋습니다.
4. 어떤 피처를 선택할 것인가는 직접 모델을 만들어 봐야 되기 때문에 제가 정확한 답변을 드릴 수가 없습니다만, 제 생각에 두개 피처 모두 그대로 유지하시는게 좋을 것 같습니다.
너무 피처간의 상관관계에 집중하실 필요는 없습니다. 업무적으로 타겟값에 영향을 미칠 수 있다고 생각되는 모든 컬럼은 그대로 유지하고, 중요한 컬럼들은 재결합/재가공등을 통해서 추가적인 피처들로 만드는게 중요합니다.
5. 피처 엔지니어링은 정답이 없습니다. 필요하다고 생각되면 추가해서 만들어보고 테스트 해봐야 합니다. 데이터 분포도만 가지고 제가 정확한 답변은 드릴 수가 없지만, 일단 추가해서 만들어 보십시요.
피처 엔지니어링을 수행할 때는 일단 기존 피처는 그대로 유지하고 추가적인 피처를 계속 만듭니다. 이때 업무적으로 중요한 피처들에 대해서 감을 잡는게 중요합니다. 그리고 이를 위해서 데이터별 분포도등을 참조하는것도 도움이 됩니다. 말씀해 주신 피처들에 대해서는 mean(), std()를 적용해 보는 것도 좋을 것 같습니다. 그리고 앞에서도 말씀드렸듯이 기존 피처들은 삭제하실 필요가 없습니다(feature selection은 후반에, 하지만 이 컬럼의 경우 어느정도 의미있는 피처로 보이므로 삭제할 필요는 없어보입니다. )
6. 일반적으로 learning_rate는 줄이고 n_estimators는 늘리는게 조금이라도 성능향상에 도움이 될 수 있지만 절대적이진 않습니다. 테스트 결과가 그렇게 나왔으면 그 결과를 적용하시면 됩니다.
8. 이건 문제군요. 2번 돌고 끝났다는 것은 학습이 안되고 있다는 것입니다. 먼저 질문입니다. 확인 후에 다시 논의하시지요.
f1_score(... , average='macro') 수행 전에 y_pred 변환로직이 있던데, 이게 맞게 변환된건가요?
sql사용
0
78
2
좋은 강의 감사드립니다.
0
93
2
8분 40초경 LGBClassifier에서 설정해주신 파라미터들 관련 질문
0
279
2
사용 가능한 RAM을 모두 사용한 후 세션이 다운되었습니다
0
646
1
안녕하세요 선생님
0
248
1
권철민교수님 진심으로 감사드립니다.
0
331
1
안녕하세요 선생님
0
371
1
# credit_card_balance 데이터셋 피쳐엔지니어링
0
287
1
초거대 데이터셋을 Submission하려면?
0
206
1
Library 관련 질문
0
383
3
최적화 함수 에러
0
623
4
LightGBM Iteration관련
0
450
2
안녕하세요 교수님 vm 관련해서 질문이 있습니다.
0
221
1
코드를 실행했는데 오류가 발생합니다
0
2035
2
bayes_opt 회귀 모델에 적용하려면..
0
282
1
타겟값의 로그변환에 대해서
0
809
1
아나콘다 환경설정
0
481
1
깃허브 주소 문의드립니다.
0
379
1
손실함수에 대한 질문
0
360
1
card_bal 데이터셋 시각화 관련 질문입니다
0
248
1
LGBM null값 처리에 관해 질문있습니다
0
555
1
컬럼 관련 질문
0
299
1
히스토그램 x 값
0
377
1
n_iter 횟수 넘음 질문
0
510
2