




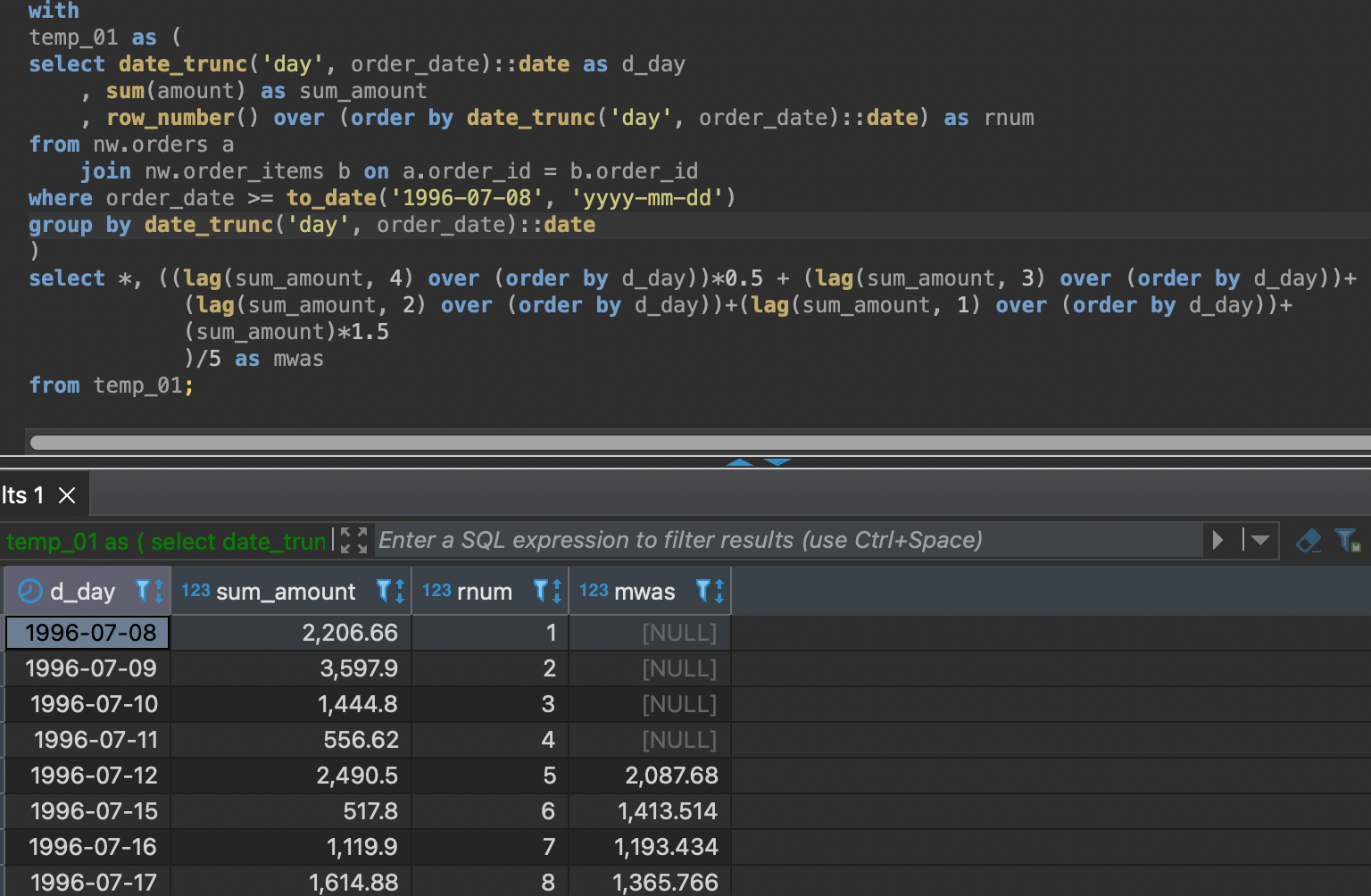
가중이동평균
안녕하세요 강사님
1) 판다스로 한다고 하면 for문과 pandas iloc을 활용하여 정말 간단히 가중이동평균을 구할 수 있는데 SQL에서는 영상의 방법 말고는 다른 수단이 없는건가요??? 예컨대 윈도우를 현재행을 계산할때 이전 행 4개의 위치를 각각 지정할 수 있으면 영상에서처럼 between 할 필요없이 계산이 가능할거 같은데 진행하신 방법이 잘 안와닿습니다.....
2) SQL에서의 자료분석 query가 대체적으로 pandas보다 긴거 같습니다. 취미로 코딩공부해온입장으로 실무를 전혀 모르는데요 제가 지금 당장 데이터분석을 한다면 sql을 데이터를 받아서 python에 임포트 후 pandas로 할거 같아요 실무에서는 어떤가요?? pandas보다 SQL query 작성의 이점이 어떻게 될까요? RDMBS식의 db라면 pandas가 제일 간편할거 같습니다
답변 2
1
안녕하십니까,
오, 제 SQL을 수정할 정도로 실력이 뛰어나시군요.
1. 파이썬에서는 상수나 가중치 등을 를 변수로 지정해서 일자가 많더라도 코드를 줄일 수 있을거 같은데 SQL에서 상수를 변수로 지정할 수 있을까요?
=> lag와 같은 Analytic(window) function에서 레코드의 offset을 지정하는 숫자값은 변수로 지정하거나 동적으로 할당할 수 없습니다. 반드시 상수로 지정해 줘야 합니다.
처음 질문 올려주신 pandas와 SQL을 비교해 보면
Pandas는 절차적인 프로그램 기반에서 수행할 수 있습니다. 즉 파이썬 코드내에서 Pandas의 API를 호출하여 로직을 구현할 수 있습니다. 반면에 SQL은 자체적인 Query Language입니다. SQL 자체 내에서 절차적인 프로그램(예를 들어 For loop)을 수행할 수는 없습니다. 다른 프로그램내에서 사용하거나 Stored Proceduer를 통해서 절차적인 프로그램을 구현합니다.
Pandas는 매우 뛰어난 분석 라이브러리를 제공합니다. 하지만 실무에서는 SQL을 훨씬 더 많이 사용합니다. 가장 대표적인 이유로
1. Pandas는 H/W 메모리의 제약을 받습니다. 그러니까, 16G RAM PC에서는 그 이상 데이터를 Pandas에 올릴 수가 없습니다.
2. 기업 환경의 대부분의 데이터는 RDBMS에 저장되어 있으므로 SQL의 경우 별도의 변환없이 분석이 가능합니다. 또한 기업내 개발 인력들은 대부분 SQL에 익숙합니다.
그럼에도 불구하고 Pandas는 매우 큰 장점을 가지고 있습니다. 제가 생각하는 큰 장점은
1. 컬럼레벨로 매우 편리하게 가공할 수 있습니다.
DataFrame['age'] = DataFrame['age'] + 10 과 같이 컬럼별로 데이터 가공이 매우 쉽습니다. 쉬운걸 넘어서 매우 강력합니다.
2. 다양한 통계 패키지와 시각화 패키지, 머신러닝 패키지와 잘 결합되어 있습니다.
Pandas는 numpy기반이므로 파이썬 생태계의 다양한 통계 패키지, 그리고 시각화 패키지와 결합되어서 통계 분석에 잘 활용될 수 있습니다. SQL은 Histogram등의 함수를 기본으로는 제공하지 않습니다. 다만 DBMS 벤더별로 해당 함수를 제공하는 경우등이 있습니다. 그럼에도 불구하고 파이썬 생태계의 다양한 기능을 함께 사용할 수 있는 Pandas는 상용 DBMS보다 더 나은 통계 분석 수행을 하는데 유용합니다.
또한 사이킷런과 같은 머신러닝 패키지에서 기본 데이터로 사용될 수도 있습니다.
머신러닝 모델을 만들시 빠르게 피처들을 분석하고, 시각화 하며, 모델을 프로토 타이핑하는데 매우 유용하게 사용될 수 있습니다.
3. 시계열 데이터 처리에 최적화 되어 있습니다.
Pandas의 창시자가 원래 월스트리트의 데이터 분석가 출신이었기 때문에 시계열 데이터 처리를 매우 쉽게 해줄수 있습니다. 사실 가중이동 평균은 Pandas로 쉽게 할 수 있지만 SQL로는 어려운 부분이 있기 때문에 제가 일부로 실습 예제로 택한 것이었습니다.
4. 절차적인 프로그래밍내에서 사용가능합니다.
python과 같은 프로그램 언어와 함께 결합하여 절차적인 처리가 가능합니다.
하지만 Pandas가 SQL을 대체하기에는 단점도 있습니다. 위에서 언급한 사항을 제외하고라도
1. 여러개의 조인을 수행할 때 번거롭습니다. Pandas는 조인도 잘 됩니다. 그런데 여러개를 이어서 조인하게 되면 SQL이 훨씬 더 간편합니다.
2. Group by가 직관적이지 않습니다. 분석에서 Group by가 차지하는 역할은 매우 높습니다. 그런데 pandas의 group by 는 사용이 간편하지 않습니다.
3. 절차적인 처리로 수행하는 방식에 익숙해 지면 코드가 길어질수 있고, 한눈에 어떤 작업을 하려는지 알기가 어려울 수 있습니다. SQL의 경우 절차적인 처리가 아니라 집합적으로 한번에 처리하는 것을 목표로 합니다. 때문에 매우 직관적인 쿼리문 작성이 가능합니다. 물론 어려운 로직인 경우 절차적인 처리가 더 편리하지만, 로직 처리시 절차적인 처리에 의존하려는 경향성이 커지면 코드가 길어지고, 한눈에 파악할 수 없습니다.
SQL 고수냐 아니냐를 가르는 여러가지 기준이 있지만 복잡한 절차적 처리를 직관적인 SQL로 얼마나 잘 만들어 내는가가 매우 중요한 요소이고, 이런 능력을 키우기 위해서 노력해야 합니다.
마지막으로 SQL 자료 분석 쿼리가 Pandas보다 길다고 하셨는데, case by case로 다릅니다. 제 개인적인 생각엔 더 복잡한 로직이거나 조인과 group by 가 많이 필요한 분석은 SQL이 훨씬 더 짧고 간결합니다.
감사합니다.
0
안녕하세요 선생님 전년도 월매출 비교강의에서나오는 lag를 사용하니 좀더 간편하게 작성이 되는 것 같습니다
lag는 분명히 fundamental강의에서도 설명해 주셨었는데 까먹고있다가...필요한 상황에서 해당 부분 강의들으니 적용이 되네요 ㅎㅎ;;
하나 아쉬운건 query의 재사용성인데요 만약 20일 가중평균을 준다라면 20개 전부 함수를 입력해줘야하는??그런 불편함이 있네요
파이썬에서는 상수나 가중치 등을 를 변수로 지정해서 일자가 많더라도 코드를 줄일 수 있을거 같은데 SQL에서 상수를 변수로 지정할 수 있을까요?
예컨대 일수 = x 로 지정해서 x만 바꾸면 query의 변수도 자동으로 바뀌어 코드의 재사용이 가능하게 만들 수 있는지요?
"주문별 고객별 연관 상품 추출 SQL로 구하기-02" 수업 질문
0
59
2
쿼리 질문있습니다!!
0
56
2
없는강의요청해도됩니까,,
0
95
2
아래와 동일한 질문에 대한 추가질문입니다
0
78
2
cnt/max로 구한 결과의 차이
0
117
2
쿼리에 대한 질문이 있습니다.
0
123
2
퍼널 질문드립니다.
0
116
1
ADSP자격증
0
289
2
특정 스키마에서 생성한 편집기의 쿼리를 판다스에 삽입하는 방법
0
161
1
백업파일 테이블 생성 오류
0
240
1
"사용자별 특정 상품 주문시 함께 가장 많이 주문된 다른 상품 추출하기"에서 조건관련..
0
171
1
Plotly을 이용해 treemap시각화시 공유사항
0
290
2
월단위 카테고리별 매출액과 주문건수 및 전체매출액 대비 비율 sql로 구하기 수업 중 질문이 있습니다.
0
254
1
with 절 질문
0
245
1
데이터 분석 SQL Fundamentals 강의 할인 문의
0
216
1
리텐션 구하는 방법 문의
0
216
1
캐글데이터 Postgresql 사용
0
364
2
mau 구할때 group by 사용안해도 count 집계함수가 왜 가능한지 모르겠습니다.
0
266
1
매출분석 1에서 partition by와 group by의 차이
0
364
1
postgres 설치 오류
0
321
1
맥 계정에서 postgres 접속 시 비밀번호 입력 실패현상
1
555
2
pandas 연계시 오류.....
0
1274
3
시각화 그래프가 안보여요
0
306
1
ntile 정규분포에 관하여 ... 향후 일을 하게 될 시
0
366
1