




한글 영어 혼합문서 전처리
4343
작성한 질문수 2
안녕하세요!
파이썬 텍스트마이닝으로 연구 계획중인 대학원생입니다
제가 분석하고자 하는 텍스트들은 영어와 한글이 혼합된 문서인데요
텍스트마이닝 강의에서들은 한글 전처리 따로 영어 전처리 따로 설명해주시더라고요!
저 같은 경우에는 전공용어 중 영어로 된것이 있어 한글과 영어를 동시에 전처리 할수 있는 방법을 알고 싶은데요
정보를 얻을수 없어 질문 남깁니다
한글과 영어를 동시에 불용어 처리하고 명사를 추출해 워드클라우드를 만들수 있는 방법을 알고 싶습니다
예로 "생물", "DNA" 모두 추출 가능하도록요
첨부한 그림은 한 연구에서 R을 이용하여 텍스트마이닝 한 것입니다!
이렇게 영어와 한글이 함께 추출되어 워드클라우드 만들수 있도록 전처치 방법을 알려주시면 감사하겠습니다!
답변 1
0
안녕하십니까, 인사이저입니다.
질문에 답변드리겠습니다.
한글 및 영어를 혼합한 텍스트 전처리 기법의 유무와
워드클라우드가 가능한지 여부에 대해서 여쭤보셨는데요,
저희가 알고 있기론
한글 및 영어에 대한 각각의 형태소 분석기 기능이 다르기에,
국영문 혼합된 데이터에 대해 한번에 전처리를 할 수 있는 모듈은 없는 걸로 알고 있습니다 ㅠㅠ
다만 입력된 데이터가 1)한글인지 영문인지 먼저 파악하고 데이터를 분류한 다음에,
2) 각 언어에 대해 다른 형태소 분석기 및 불용어 처리, 토크나이저를 적용한 후,
그 다음에서야 토큰들을 섞어 3) 워드 클라우드를 만드는 것은 가능할 것으로 보입니다.
아래는 예시 코드입니다.
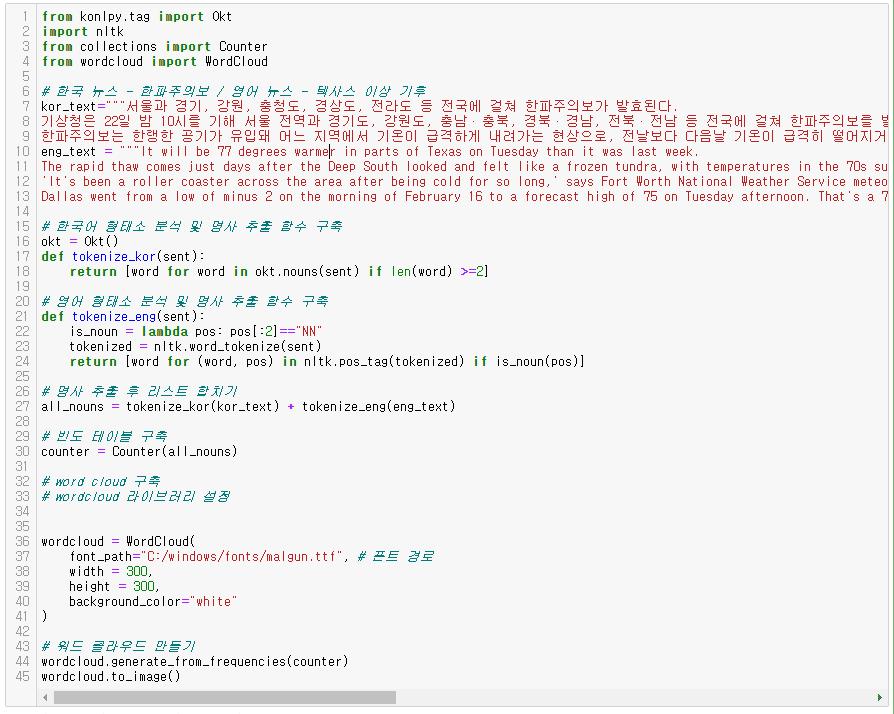
한글의 형태소 분석기는 konlpy의 Okt를 사용했고,
영어는 nltk를 활용했습니다.
nltk 설치는 아래의 코드를 실행하면 됩니다.

데이터는 한글 뉴스 데이터 아무거나, 영어 뉴스 데이터 아무거나 가져와서 넣었습니다.
(날씨로 포커스를 한 번 맞춰봤습니다.)
결과는 아래처럼 나왔습니다.

네, 코드를 보시면 아시겠지만,
영어 데이터 따로, 한글 데이터 따로 형태소 분석과 토크나이징을 진행한 다음에
워드클라우드를 생성하는 모습을 확인할 수 있습니다.
어떻게 궁금증이 해결되셨을지는 모르겠습니다.
한번 내용을 확인해보시고, 궁금한 사항이 있을 시엔 언제든 질문주시기 바랍니다~
감사합니다!
jpype 설치관련
0
1847
2
Konlpy 설치
0
1005
2
Konlpy 설치 페이지에서 jpype 설치 링크
0
390
1
맥 os에서 폰트 경로 지정*코랩 사용
0
1270
1
Re. Konlpy 설치오류(Okt 오류)
0
1601
1
Konlpy 설치 오류
0
3856
1
tfidf 관련
0
531
1
TF-IDF 질문입니다.
0
555
1
토픽모델링 날짜 관련 오류
0
275
1
질문드립니다.
0
355
1
워드클라우드 plt.subplot 질문
0
326
1
p54 문의드립니다
0
198
1
문의드립니다.
0
1059
1
문의드립니다
0
218
1
p55 문의드립니다
0
228
1
mecab 설치 오류
0
477
1
mecab 설치 오류
0
1377
1
가이드 53페이지 질문(konlpy 파일 없음)
0
291
1
konlpy 설치 오류
0
633
1
jpype 설치 오류
0
280
1
wordcloud image mask가 적용이 안됩니다.
0
1289
1
wordcloud 설치가 안됩니다
0
277
1
가상환경 3.7.11로 설치한 가상환경을 conda info로 확인한 버전과 python --version으로 확인한 버전과 다릅니다.
0
673
1
p.45 konlpy 설치 확인단계에서 오류가 발생합니다.
0
6085
4