




Python 에서 성능을 추구하면 안되는 걸까? - 0. 문제 파악하기
2026. 01. 21. 13:08
안녕하세요, 3always8입니다.
Python으로 프로그래밍에 입문 하시는 분들이 정말 많습니다. 저도 그랬구요.
흔히 Python 은 배우기 쉽고, 사용하기 쉽지만, 느리고 효율이 낮은 언어라고들 합니다.
하지만 지금 당장 내 코드가 3시간째 안 끝나고 있거나,
아무리 다시 돌려봐도 매번 "Segmentation Fault" 가 발생하면서 멈춰버린다면,
원래 이렇게 오래 걸리고 무거운 일일까요?
혹은 Python이란 이유만으로 이 모든 걸 감당해야 할까요?
많은 경우, 그정도는 아닙니다.
속도를 높이고 메모리 사용량을 개선하기 위한, 흔히 아시는 방법부터 흔하지 않은 방법까지,
여러 글에 걸쳐 소개하겠습니다.
그럼 가장 먼저 뭘 배워야 할까요?
측정하는 법 입니다.
얼마나 느린지, 어디가 느린지 알아야 고칠 수 있습니다.
단순한 예제를 하나 가져왔습니다. 바로 보시죠.
# profiling.py
import random
import time
start = time.time()
# 5만 개의 숫자가 있습니다.
all_numbers = [random.randint(1, 1000000) for _ in range(50000)]
# 그 중 특정 숫자들 10000개가 있습니다.
bad_numbers = [random.randint(1, 1000000) for _ in range(10000)]
# 이제 all_data 안에 targets 가 있는 경우들을 찾아 보겠습니다.
results = []
for n in bad_numbers:
if n in all_numbers:
results.append(n)
end = time.time()
print(f"찾은 개수: {len(results)}")
print(f"걸린 시간: {end - start:.3f}")이 예제에서는 전체 숫자(all_numbers)가 5만 개이고, 나쁜 숫자(bad_numbers)가 1만 개인 상황을 가정합니다.
그리고 전체 숫자 중 나쁜 숫자가 혹시 몇 개나 들어 있는지를 찾습니다.
그런데 실제 이 코드를 돌려보시면 시간이 꽤나 오래 걸립니다.
찾은 개수: 485개
걸린 시간: 3.424초컴퓨터의 세계에서 1초는 아주 긴 시간입니다. 그런데 3초가 넘게 걸리다니요.
만약 전체 숫자가 5만 개가 아니라 50만 개라면 어떻게 될까요? (바쁘신 분들은 돌려보지 마세요)
찾은 개수: 3915개
걸린 시간: 27.960초만약 전체 숫자가 500만 개라면? 찾아야 하는 나쁜 숫자가 10만 개라면?
이럴 때마다 그냥 돌려놓고 다른 일을 하다 와야만 하는 걸까요?
이걸 개선하는 건 다음 글에서 해보고, 이번 글에서는 정확히 어디가 문제인지를 알아내 봅시다.
1. time - 가장 단순한 시간 측정 방법
첫 번째 측정 방법을 소개합니다.
별도의 설치 없이 import time 만 하면 그 다음부터 쓸 수 있습니다. Python 안에 이미 포함되어 있거든요.
우리가 이번에 쓸 time.time() 은 현재 시각을 초로 변환해서 보여주는 함수입니다.
import time
print(time.time())
# 결과: 1768973618.29933이걸 사용해서, 두 time.time() 사이의 시간 간격을 알아낼 수 있습니다.
start = time.time()
end = time.time()
print(end - start)
# 결과: 2.2605438232421875start 로 시작하는 line과, end 로 시작하는 line은 약 2.26초 간격으로 실행되었군요.
그러면 이 start 와 end 사이에 측정하고 싶은 코드가 동작하도록 하면
end - start 가 우리가 측정하려는 시간입니다.
눈썰미가 좋으신 분이라면 우리가 예제로 사용한 코드에 이 패턴이 들어가 있는 걸 보셨을 겁니다.
그런데 정확히 어디에서 시간이 오래 걸리는지 알고 싶으면 어떻게 해야 할까요?
여러 번 하면 됩니다. 이론상.
# profiling.py
import random
import time
start1 = time.time()
all_numbers = [random.randint(1, 1000000) for _ in range(50000)]
end1 = time.time()
print(f"걸린 시간1: {end1 - start1:.3f}")
start2 = time.time()
bad_numbers = [random.randint(1, 1000000) for _ in range(10000)]
end2 = time.time()
print(f"걸린 시간2: {end2 - start2:.3f}")
start3 = time.time()
results = []
end3 = time.time()
print(f"걸린 시간3: {end3 - start3:.3f}")
start4 = time.time()
for n in bad_numbers:
if n in all_numbers:
results.append(n)
end4 = time.time()
print(f"찾은 개수: {len(results)}")
print(f"걸린 시간4: {end4 - start4:.3f}")걸린 시간1: 0.015
걸린 시간2: 0.003
걸린 시간3: 0.000
찾은 개수: 493
걸린 시간4: 3.5451,2,3번은 별로 오래 걸리지 않았고, 대부분 4번에서 시간이 오래 걸렸군요.
그런데 너무... 불편합니다.
매번 start, end 로 시작하는 line을 작성해야 하고, 이걸 나중에 지우는 것도 번거로운 일이죠.
혹은 측정하고 싶은 부분이 for문 안에 있는 경우, 걸린시간: ... 라는 부분이 수십 수백 번 등장하는 걸 보거나,
측정을 제대로 하기 위해 추가로 코딩을 하다 보면 배보다 배꼽이 커지기 십상입니다.
2. line_profiler - 어떤 line이 범인인가?
이런 불편을 해결하기 위한 도구로 line_profiler 를 소개합니다.
아래와 같이 간단한 설치가 필요합니다.
pip install line_profiler
혹은
python -m pip install line_profilerline_profiler는 "특정 함수 안에 들어있는 line들 중 누가 시간이 오래 걸리는지" 를 알아낼 수 있습니다.
그러면 우리 코드를 하나의 함수로 만들어 봐야겠군요.
아래와 같이 main 이라는 함수에 우리가 측정하고 싶은 모든 내용을 다 때려넣겠습니다.
함수 이름은 뭐든 상관없습니다.
그리고 마지막에 이 함수를 호출해서 실행까지 하도록 했습니다.
생긴 건 조금 다르지만, 실행해보면 우리의 처음 예제와 거의 같은 결과를 보실 수 있을 겁니다.
# profiling.py
import random
import time
def main():
start = time.time()
# 5만 개의 숫자가 있습니다.
all_numbers = [random.randint(1, 1000000) for _ in range(50000)]
# 그 중 특정 숫자들 10000개가 있습니다.
bad_numbers = [random.randint(1, 1000000) for _ in range(10000)]
# 이제 all_data 안에 targets 가 있는 경우들을 찾아 보겠습니다.
results = []
for n in bad_numbers:
if n in all_numbers:
results.append(n)
end = time.time()
print(f"찾은 개수: {len(results)}")
print(f"걸린 시간: {end - start:.3f}")
main()이제 이 함수 위에 @profile 이라는 문구만 추가로 하나 달아줄게요.
# profiling.py
...
@profile
def main():
...마지막으로, 실행 방법이 조금 특이합니다. 터미널에서 아래와 같이 실행해주시면 됩니다.
kernprof -l -v profiling.py이제 조금 기다리면 결과가 나옵니다.
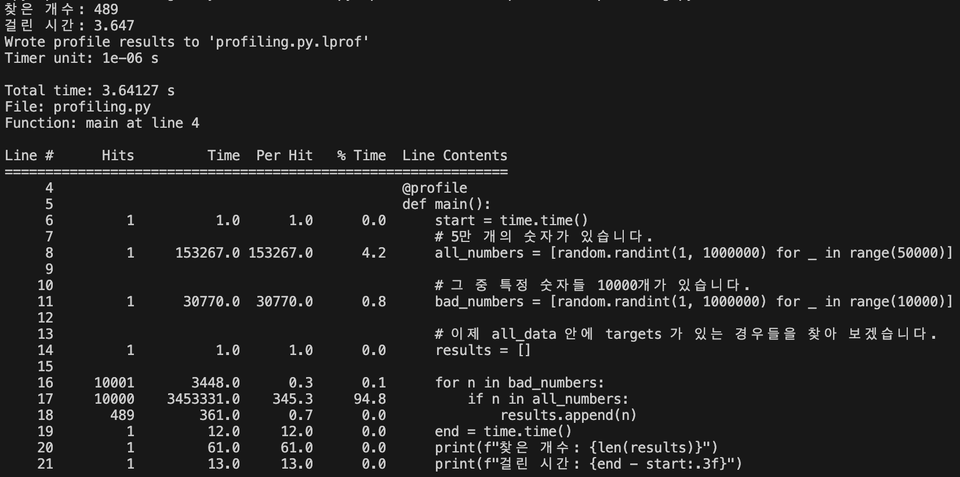
line_profiler 실행 결과
위 이미지에서 Line # 가 17인 곳을 보시면, 해당 line이 전체 시간의 94.8% 만큼을 잡아먹었다는 걸 알 수 있습니다.
측정 원리는 간단합니다. 우리의 코드가 실행되는동안, line_profiler는 0.000001초에 한 번씩 "너 지금 몇 번째 line 실행하고 있어?" 를 확인합니다.
여기에 자주 걸린 line 은 그만큼 전체 시간이 오래 걸리는, 주요 범인 line이란 뜻이죠.
그리고 확인 결과 전체의 94.8% 가 전부 17번째 line을 실행하고 있었다는 겁니다.
3. cProfile - 어느 함수가 범인인가?
이외에도 코드에 여러 함수들이 등장하는 경우, 어떤 함수가 오래 걸렸는지 알아내는cProfile 이라는 도구가 있습니다.
이건 python 에 내장되어 있어서 별도의 설치 없이 사용할 수 있습니다.
그만큼 오래되고 공식적인 도구이기도 합니다.
다만 우리의 지금 예시는 함수가 없거나, 있어도 하나 뿐이죠.
우리 예시를 강제로 아래처럼 수정해서, cProfile을 사용하는 방법을 보여드리고 넘어가겠습니다.
# profiling.py
import random
import time
def get_all_numbers(n):
return [random.randint(1, 1000000) for _ in range(n)]
def get_bad_numbers(n):
return [random.randint(1, 1000000) for _ in range(n)]
def find_numbers(all_nums, bad_nums):
results = []
for n in bad_nums:
if n in all_nums:
results.append(n)
return results
def main():
all_numbers = get_all_numbers(50000)
bad_numbers = get_bad_numbers(10000)
results = find_numbers(all_numbers, bad_numbers)
print(f"찾은 개수: {len(results)}")
if __name__ == "__main__":
main()아래 명령어로 cProfile을 실행합니다.
python -m cProfile -s tottime profiling.py그 결과는 아래와 같이 나옵니다.
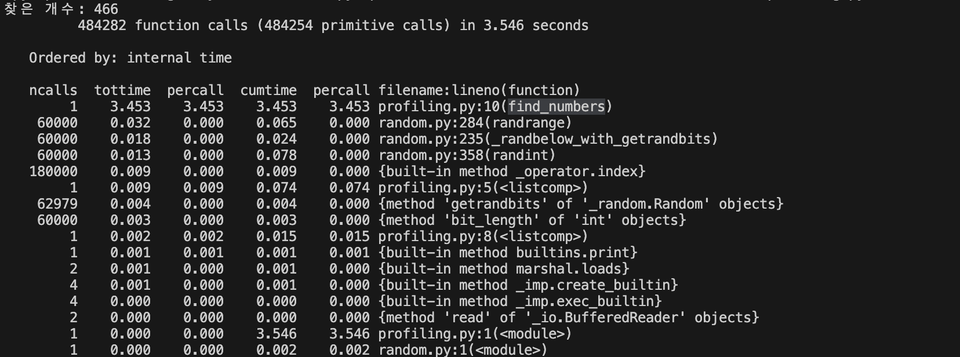
cProfile 결과
가장 시간이 오래 걸리는 게 맨 위로 오도록 한 상태입니다.
profiling.py 의 10번째 줄인 find_numbers 함수로 범인이 좁혀졌네요.
오늘 여러 도구를 사용해 파악해보니, if n in all_numbers: 라는 부분이 시간이 오래 걸리는 범인입니다.
이건 간단하게 생겼는데 왜 이렇게 오래 걸릴까요? 더 빠르게 할 순 없는 걸까요?
다음 글에서 이어서 확인해보겠습니다.
3줄 요약:
특정 부분의 시간이 얼마나 걸리는지 알아내고 싶다면
time어떤 line 때문에 오래 걸리는지 알아내고 싶다면
line_profiler어떤 함수 때문에 오래 걸리는지 알아내고 싶다면
cProfile
내용이 도움이 되셨다면 박수! 댓글! 부탁드립니다.
독자 여러분의 피드백이 더 나은 컨텐츠를 제작하는 데 매우 큰 도움이 됩니다.
모두 행복한 프로그래밍 하시길 바랍니다.
감사합니다!