
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
CRAFT 모델 train and validation data split 관련 오류
22.12.14 23:53 작성 22.12.16 10:20 수정 조회수 334
0
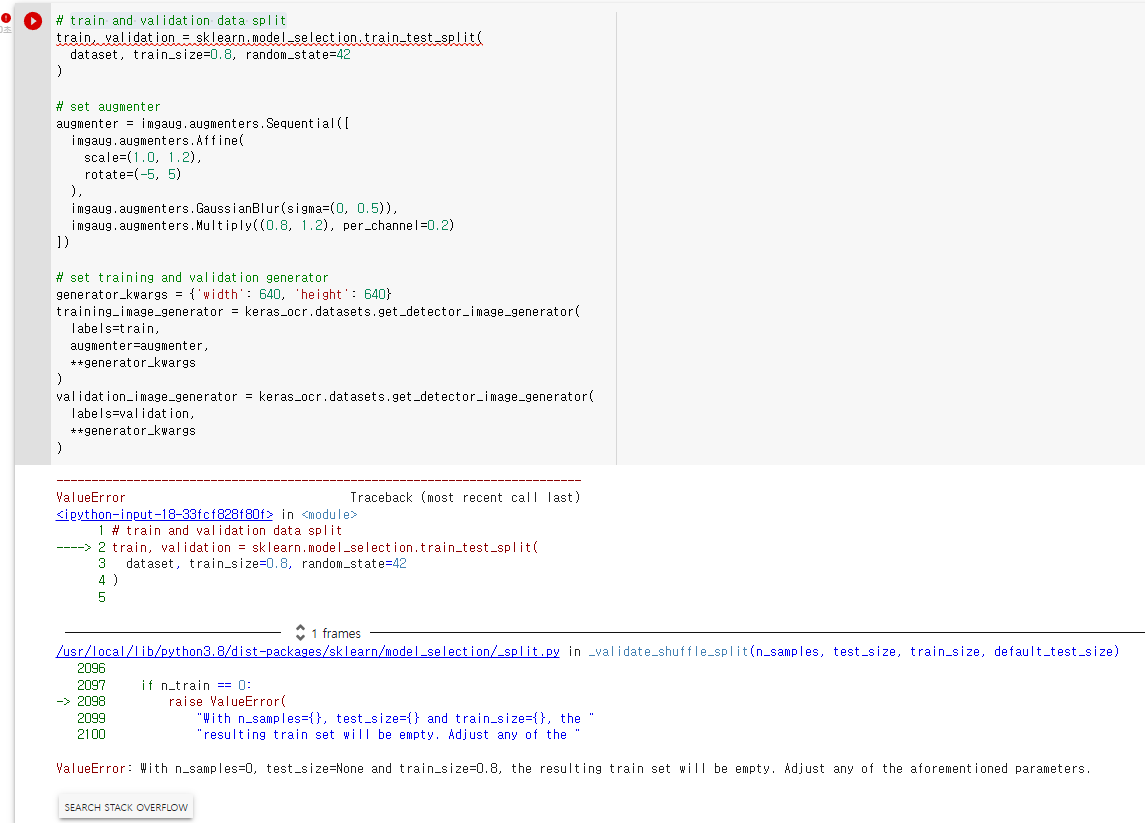 Custom Dataset을 만들어서 CRAFT 모델에 적용하려고 하는데 위와 같은 에러가 발생합니다. 에러를 해결할 방법에 대해 문의드립니다.
Custom Dataset을 만들어서 CRAFT 모델에 적용하려고 하는데 위와 같은 에러가 발생합니다. 에러를 해결할 방법에 대해 문의드립니다.
Custom Dataset 수를 120장 정도로 했을때는 위 코드 부분에서 에러가 나지 않았는데 Image Augmentation 적용후 Custom Dataset 수를 220장 정도로 늘린 후에 CRAFT 모델에 적용하려고 하니 위와 같은 코드에러가 발생합니다. (120장 넣었을때는 Custom Dataset .zip파일 압출을 풀때 .png파일부터 압축 해제가 되었는데, 220장으로 늘린 후에는 .txt 파일부터 압축해제가 되는데요, 혹시 .png파일부터 압축해제가 안되어서 그런건 아닌지 생각도 해봤습니다)
그리고 압축해제 후 코드창에 Dataset을 입력하면 []로 빈 파일로 나옵니다.

답변을 작성해보세요.
0

AISchool
지식공유자2022.12.18
안녕하세요~. 반갑습니다.
먼저 답신이 늦어서 죄송합니다ㅠ.
작성해주신 내용을 토대로 추론해보면 아래와 같이
dataset = get_licenseplate_detector_dataset(cache_dir='.')dataset을 읽어서 불러오는 함수의 결과값으로 빈 배열 []이 나오시는 상태이신 것 같은데요.
custom dataset으로 사용하시려면 아래 함수를 custom dataset에 맞게 변경해서 다시 작성하신뒤 사용하셔야합니다. 해당 과정의 custom dataset을 읽어오는 함수 작성에서 뭔가 문제가 있어서 return 결과값이 빈배열로 넘어오는 상황으로 예상됩니다.
def get_licenseplate_detector_dataset(cache_dir=None):
"""
Args:
cache_dir: The directory in which to store the data.
Returns:
Lists of (image_path, lines, confidence) tuples. Confidence
is always 1 for this dataset. We record confidence to allow
for future support for weakly supervised cases.
"""
if cache_dir == None:
raise ValueError('cache_dir is None')
main_dir = os.path.join(cache_dir, 'license_plate_detection_data')
training_images_dir = os.path.join(main_dir, 'images')
training_gt_dir = os.path.join(main_dir, 'annotations')
dataset = []
for gt_filepath in glob.glob(os.path.join(training_gt_dir, '*.txt')):
image_id = os.path.split(gt_filepath)[1].split('.')[0]
image_path = os.path.join(training_images_dir, image_id + '.jpg')
lines = []
with open(gt_filepath, 'r') as f:
for row in f.read().split('\n'):
current_line = []
row = row.split(' ')
character = row[-1][1:-1]
x1, y1, x2, y1, x2, y2, x1, y2 = map(int, row[:8])
current_line.append((np.array([[x1, y1], [x2, y1], [x2, y2], [x1, y2]]), character))
lines.append(current_line)
# Some lines only have illegible characters and if skip_illegible is True,
# then these lines will be blank.
lines = [line for line in lines if line]
dataset.append((image_path, lines, 1))
return dataset사용하시는 custom dataset의 정확한 데이터셋의 형상을 알수없어서 정확한 문제 원인은 알 수 없지만 예상되는 가능성 중 하나는 위 함수에서는 jpg 파일 형태를 읽어오는데 답변주신내용으로는 데이터셋이 png 파일이라고 말씀해주신것으로보아 위 코드의 jpg를 읽어오는 부분을 png를 읽어오는 것으로 변경하지 않은것이 아닐까 싶습니다.
위 get 함수 안의 변수 하나하나에 값이 잘들어갔는지 단계적으로 체크해보시면서 디버깅해보시면 좋을 것 같습니다.
좋은 하루되세요~.
감사합니다.

답변 1