
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
해결됨
(재업)인기제품 추천방식 결과가 달라요
22.04.07 10:23 작성 조회수 119
2
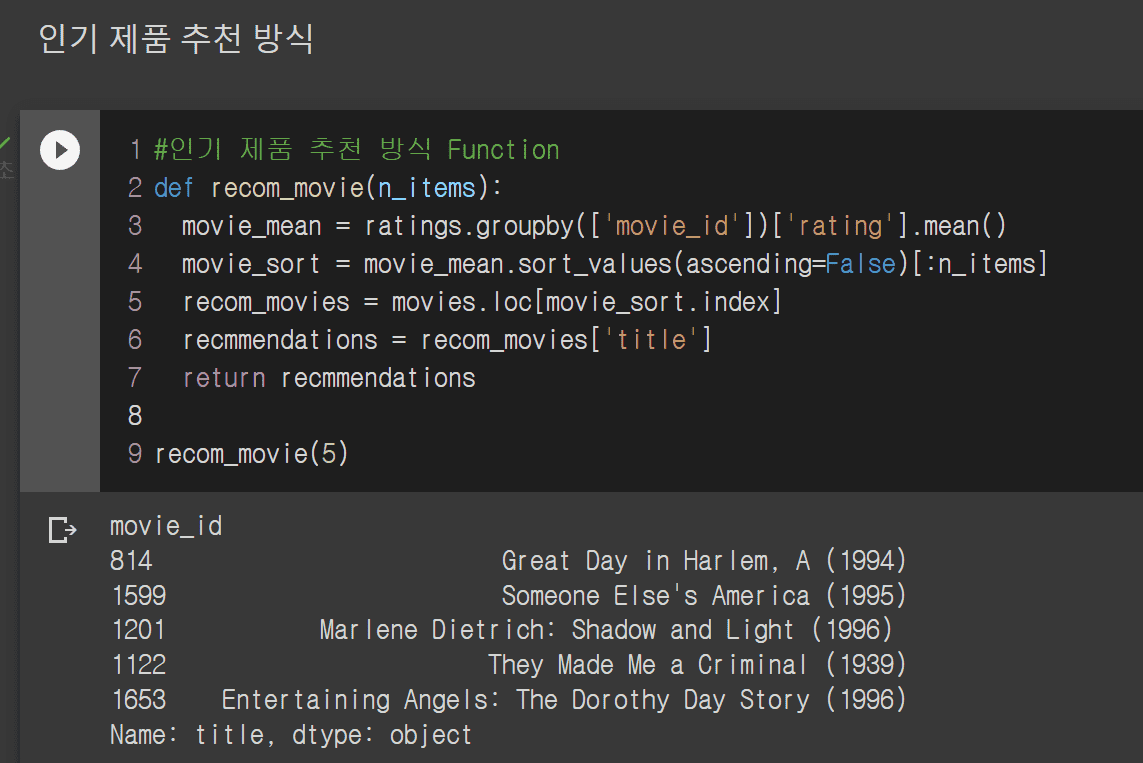
인기 제품 추천 방식 코드를 보고 따라쳤는데, 강사님이랑 결과(movie_id)가 다른데 왜 그런건가요?
#사용자 u.user 파일을 DataFrame으로 읽기
import os
import pandas as pd
base_src = 'drive/MyDrive/RecoSys/Data'
u_user_src = os.path.join(base_src,'u.user')
u_cols = ['user_id','age','sex','occupation','zip_code']
users = pd.read_csv(u_user_src,
sep='|',
names=u_cols,
encoding='latin-1')
users = users.set_index('user_id')
users.head()
# u.item 파일을 DataFrame으로 읽기
u_item_src = os.path.join(base_src,'u.item')
i_cols = ['movie_id','title','release date','video release date',
'IMDB URL','unknown','Action','Adventure','Animation',
'Children\'s','Comedy','Crime','Documentary,','Drama','Fantasy',
'FilmNoir','Horror','Musical','Mystery','Romance', 'Sci-Fi','Thriller','War','Western']
movies = pd.read_csv(u_item_src,
sep='|',
names=i_cols,
encoding='latin-1')
movies = movies.set_index('movie_id')
movies.head()
#u.data 파일을 DataFrame으로 읽기
u_data_src = os.path.join(base_src,'u.data')
r_cols = ['user_id', 'movie_id','rating','timestamp']
ratings = pd.read_csv(u_data_src,
sep = '\t',
names = r_cols,
encoding='latin-1')
ratings = ratings.set_index('user_id')
ratings.head()
#인기 제품 추천 방식 Function
def recom_movie(n_items):
movie_mean = ratings.groupby(['movie_id'])['rating'].mean()
movie_sort = movie_mean.sort_values(ascending=False)[:n_items]
recom_movies = movies.loc[movie_sort.index]
recommendations = recom_movies['title']
return recommendations
recom_movie(5)

답변을 작성해보세요.
1

거친코딩
지식공유자2022.04.07
안녕하세요.
거친코딩입니다.
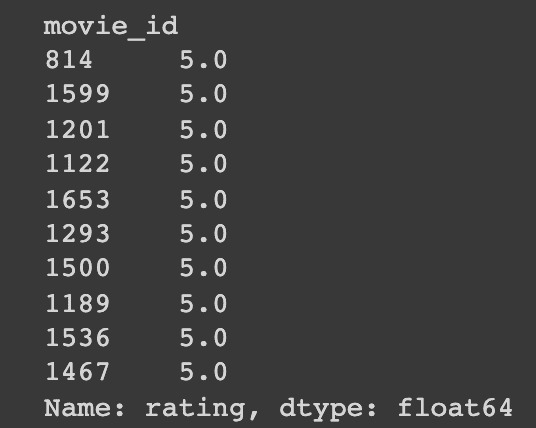
저 또한 새롭게 코드를 돌려보았을 때 학습자님처럼 같은 결과값이 나왔습니다.
그런데 자세히 보니, 해당 부분이 다르게 나온 이유는 코랩 쪽에서 데이터를 보여주는 우선 순위(그들만의 글자 순)으로 보여주는 것 같았습니다.
쉽게 말해서 코드로 말씀드리면 아래와 같습니다.
1순위~10순위가 5.0으로 동일하게 점수를 배정받고 있기 때문에, 단순히 5개를 찍히는 것은 코랩쪽에서 보여지는 규칙인 것 같습니다.
나중에 향후 비즈니스에서는 이러한 동점이 나온 상황에서는 룰 베이스(각자 비즈니스 도메인)에 맞게 처리하시면 될 것 같습니다.
감사합니다.
-거친코딩 드림-
movie_mean = ratings.groupby(['movie_id'])['rating'].mean()
movie_sort = movie_mean.sort_values(ascending=False)[:10]
movie_sort

답변 1