
-
질문 & 답변
카테고리
-
세부 분야
데이터 분석
-
해결 여부
미해결
CSS 선택자 copy + 네이버 미국증시
22.01.09 01:37 작성 조회수 212
1
- 먼저 유사한 질문이 있었는지 검색해보세요.
- 서로 예의를 지키며 존중하는 문화를 만들어가요.
- 잠깐! 인프런 서비스 운영 관련 문의는 1:1 문의하기를 이용해주세요.
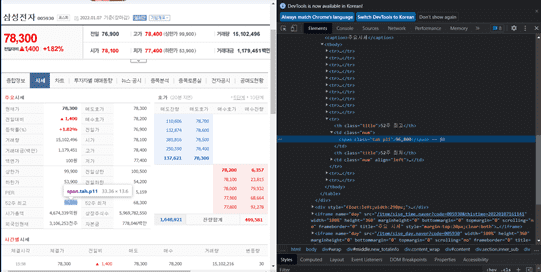
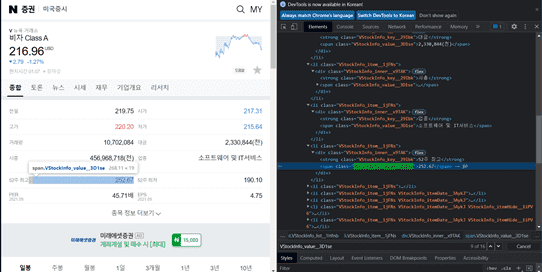
tickers = ['APPL.O', 'GOOGL.O']
for ticker in tickers:
url = f"https://m.stock.naver.com/index.html#/worldstock/stock/{ticker}/total"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
price = soup.select_one("#content > div.GraphMain_mainGraph__3npcJ.UNCHANGED > div.GraphMain_frameGraph__19k0w > div.GraphMain_stockInfo__2-Uf6 > strong")
name = soup.select_one("#content > div.GraphMain_mainGraph__3npcJ.UNCHANGED > div.GraphMain_frameGraph__19k0w > div.GraphMain_stockInfo__2-Uf6 > span.GraphMain_name__3XazJ")
print(name, price)
답변을 작성해보세요.
3

스타트코딩
지식공유자2022.01.10
미국증시는 제가 수업에서 다룬 예제가 아니라서
답변 드리기 어렵지만
내친김에 같이 알려 드리겠습니다 ^^
1. 문제의 원인
말씀해 주신 미국증시 사이트는 정보를 "동적으로" 가져오고 있습니다.
페이지가 로딩되고나서 서버에 데이터를 가져오고 있죠.
그래서 None이 뜨는 겁니다.
2 . 해결방법
1) 이때 초보자의 경우 셀레니움을 이용합니다.
(대부분 크롤링 됩니다)
2) requests를 사용하고 싶다면 서버와 통신하는 api를 찾아야 하는데요.
자세히 알려드리기엔 내용이 많고 조금 어렵습니다. ㅎㅎ
(개발자 도구의 Network 탭을 분석합니다)
소스 코드를 첨부해 드리겠으니 활용해 보세요 :)
import requests
import json
# naver stock api 활용해서 52주 최고가 확인하기
url = 'https://api.stock.naver.com/stock/AAPL.O/basic'
response = requests.get(url)
data = json.loads(response.text)
print(data['stockItemTotalInfos'][8]['key'])
print(data['stockItemTotalInfos'][8]['value']) # 8번째 요소에 52주 최고가
2
스타트코딩
지식공유자2022.01.10
안녕하세요.
class 나 id 가 없어서 당황하셨군요!
저는 보통 세가지 방법을 사용하는데요.
1. 개발자도구의 copy 기능을 이용한다
2. 셀렉터를 자세하게 짠다 (nth-child이용)
3. 반복문과 조건문을 이용해서 찾는다 (노가다)
52주 최고가는 1번을 이용하면 잘 불러와지네요 코드 첨부해 드릴테니 확인해 보세요!
import requests
from bs4 import BeautifulSoup
codes = [
'005930',
'000660',
'035720'
]
for code in codes:
url = f"https://finance.naver.com/item/sise.naver?code={code}"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
price = soup.select_one("#content > div.section.inner_sub > div:nth-child(1) > table > tbody > tr:nth-child(11) > td:nth-child(2) > span").text
price = price.replace(',', '')
print(price)

곽수민
질문자2022.01.11
말씀하신대로 해봤더니 오류가 나서, 인터넷에 찾아봤더니 nth-child 지원이 안되서 오류가 뜨는거고 nth-of-type로 바꿔야 한다고 하더라구요...
그러면 숫자가 다행히도 떴는데 52주 최저가의 수치가 뜨더라구요!
도대체 왜 이러는지는 모르겠지만 웹사이트 자세히 보면서 마지막에 td:nth-of-type (1)로 바꾸니까 해결이 되었습니다.
친절한 설명 감사합니다!
0
스타트코딩
지식공유자2022.01.13
*답변 정책 변경 (2022.01.13 이후)
강의 내용 외 타사이트 질문에 대한 답변은
실전편 수강생들에게만 제공해 드리도록 변경되었습니다.
- 기존 답변은 유지

답변 3