
월 17,600원
5개월 할부 시
중급자를 위해 준비한
[딥러닝 · 머신러닝] 강의입니다.
최근 인공지능 분야의 놀라운 성과는 모두 강화 학습 분야에서 발표되고 있습니다. 로봇, 자율 주행 기술, 인간을 닮은 기계 등 진정한 인공 지능 기술의 혁신을 이루어 내고 있는 강화 학습 기술을 초보자의 시선으로 알기 쉽게 기초에서 고급 수준까지 다루었습니다.
이런 걸
배워요!
들어올 땐 초보자, 나갈 땐 실무자!
강화학습의 A to Z를 강의 하나로 🤩
강화학습,
초심자의 눈높이에 맞게 학습해요! 📖
강화학습은 일반적으로 우리가 알고 있는 딥러닝/머신러닝처럼 데이터 중심이 아니라, 시행착오 중심으로 발달해 온 인공지능 학습 방법입니다. 최근 딥러닝의 발달에 따라 딥러닝과 강화학습이 만나게 되었고, 그 이후 다양한 강화학습이 실제 문제를 해결하는 데 적용되었습니다. 현재는 많은 성공사례를 가진 중요한 인공지능, 알고리즘의 한 분야로 자리 잡게 되었어요.
본 강의는 파이토치를 딥러닝 도구를 사용하여, 강화학습의 기초부터 고급 지식까지 다룬 강의입니다. 어려운 수학을 사용하지 않고 쉽게 설명하려 노력했으며, 실무에 적용할 수 있도록 실습 중심으로 강의를 진행합니다.
![]()
실제 오프라인 강의로 진행 중인 검증된 커리큘럼
![]()
현장 수강생의 피드백으로 완성도를 높인 강의 자료
![]()
실습 중심의 실용적인 강의
수강 타겟/강의 목적 🙆♀️

강화학습에 관심 있는 분

강화 학습을 업무에 적용하려는 개발자

인공지능 지식의 폭을 넓히고 싶은 분
이런 걸 배워요 📚
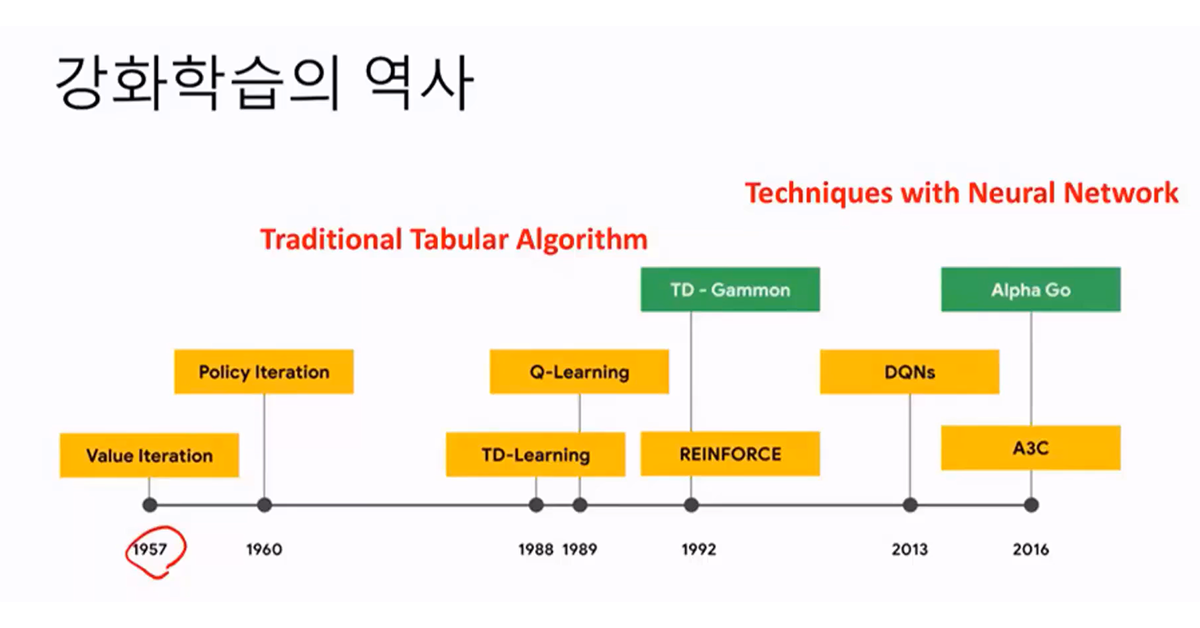
1. 강화 학습의 역사

2. Dynamic Programming

3. Monte Carlo Method

4. Temporal Difference Method (시간차 학습)

5. Deep Q-learning

강의는 실습과 함께! 🔥
수강 전 참고 사항 📢
실습 환경
- Windows, Mac, Linux 모두 무방합니다.
- 사용 도구: VSCODE, Jupyter Notebook, Colab
- PC 사양: 일반적 사양
학습 자료
- 제공하는 학습 자료 형식 (PPT, 클라우드 링크, 텍스트, 소스 코드, 애셋, 프로그램, 예제 문제 등)
- 분량 및 용량, 기타 학습 자료에 대한 특징
잠깐! ✋ 강의 수강을 위해선 파이썬 기초 지식이 필요해요.
유형별로 함께 들으면 좋은 강의를 추천합니다.
Type 1 파이썬 기초 실력이 부족하지만, 시간이 없어 속성 Crash 코스가 필요하신 분
Type 2 머신러닝/딥러닝에 대한 사전 지식을 차근차근 익히고 싶은 분
Type 3 파이썬 언어를 제대로 확실히 익히고 싶으신 분
예상 질문 Q&A 💬
Q. 어떤 프로그램 언어를 사용하나요?
파이썬 언어를 이용하여 알고리즘을 구현합니다.
Q. 딥러닝 사전 지식이 필요한가요?
그렇습니다. 선수 과정 안내를 참고 바랍니다.
Q. 딥러닝 프레임워크는 어떤 것을 사용하나요?
파이토치를 이용하여 딥러닝 네트웍을 구현하고 있습니다. 파이토치 crash 코스가 강의에 포함되어 있으므로 파이토치 사용법을 몰라도 무방합니다.
지식공유자 소개 ✒️
파이썬과 인공지능을 5년간 강의하고 있는 인공 지능 전문 강사입니다.
인프런에 다음과 같은 강의가 올라가 있습니다.
이런 분들께 추천드려요!
학습 대상은
누구일까요?
선수 지식,
필요할까요?
YoungJea Oh 입니다.

오랜 개발 경험을 가지고 있는 Senior Developer 입니다. 현대건설 전산실, 삼성 SDS, 전자상거래업체 엑스메트릭스, 씨티은행 전산부를 거치며 30 년 이상 IT 분야에서 쌓아온 지식과 경험을 나누고 싶습니다. 현재는 인공지능과 파이썬 관련 강의를 하고 있습니다.
홈페이지 주소:
