
과제를 수행하는 코드가 작동은 하는데 오류를 뱉습니다.
462
7 câu hỏi đã được viết
좋은 강의 열심히 듣고 있습니다~ 다름이 아니라 과제로 다음 실시간 검색어 10개를 스크래핑 하는 코드를 작성했습니다. 검색어와 주소를 깔끔하게 출력하는데는 성공했는데 오류가 발생합니다.
코드와 오류 및 결과를 첨부하겠습니다.
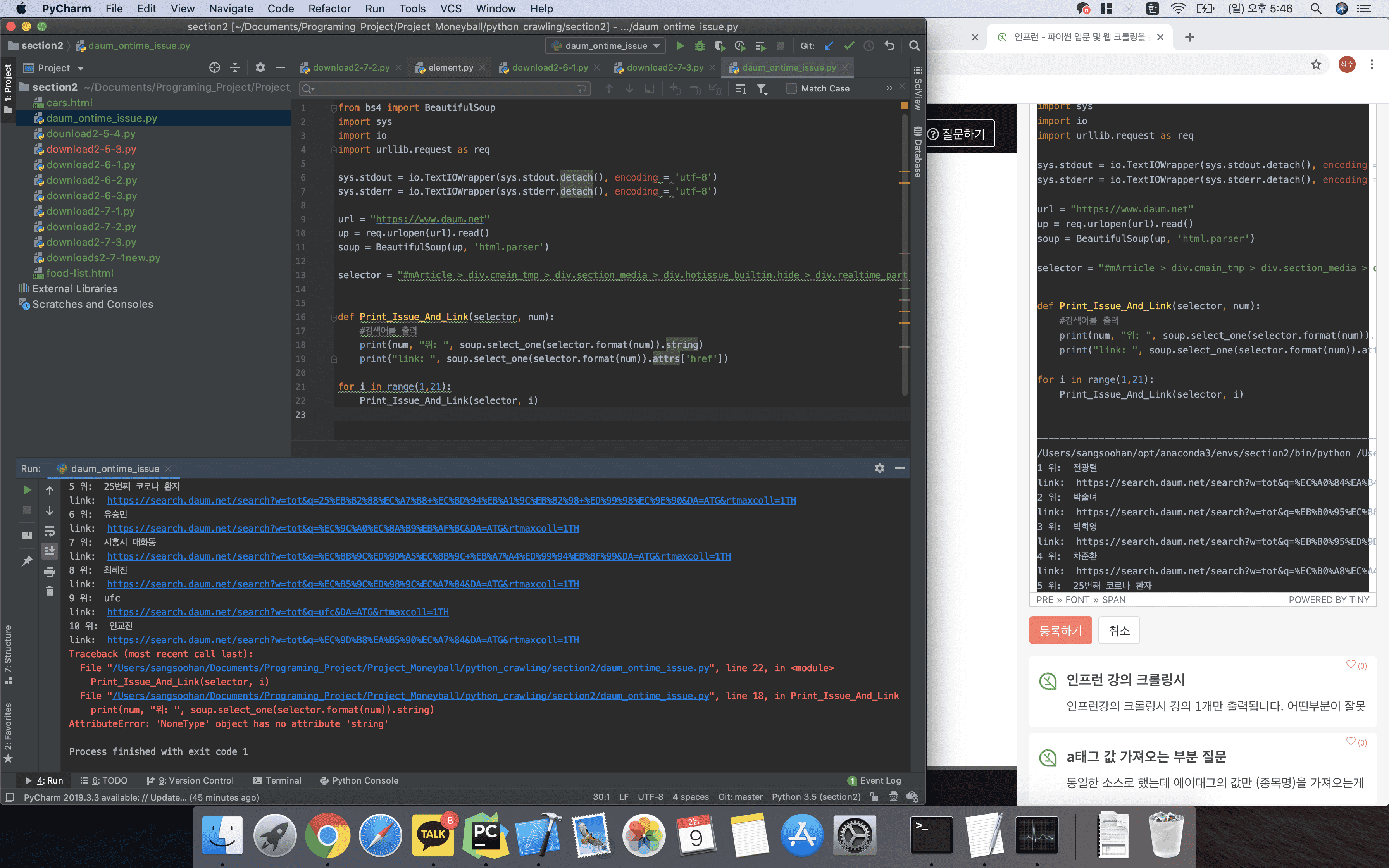
from bs4 import BeautifulSoup
import sys
import io
import urllib.request as req
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding = 'utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.detach(), encoding = 'utf-8')
url = "https://www.daum.net"
up = req.urlopen(url).read()
soup = BeautifulSoup(up, 'html.parser')
selector = "#mArticle > div.cmain_tmp > div.section_media > div.hotissue_builtin.hide > div.realtime_part > ol > li:nth-child({}) > div > div:nth-child(1) > span.txt_issue > a"
def Print_Issue_And_Link(selector, num):
#검색어를 출력
print(num, "위: ", soup.select_one(selector.format(num)).string)
print("link: ", soup.select_one(selector.format(num)).attrs['href'])
for i in range(1,21):
Print_Issue_And_Link(selector, i)
-------------------------------------------------------------------------------------------------------------
/Users/sangsoohan/opt/anaconda3/envs/section2/bin/python /Users/sangsoohan/Documents/Programing_Project/Project_Moneyball/python_crawling/section2/daum_ontime_issue.py 1 위: 전광렬 link: https://search.daum.net/search?w=tot&q=%EC%A0%84%EA%B4%91%EB%A0%AC&DA=ATG&rtmaxcoll=1TH 2 위: 박술녀 link: https://search.daum.net/search?w=tot&q=%EB%B0%95%EC%88%A0%EB%85%80&DA=ATG&rtmaxcoll=1TH 3 위: 박희영 link: https://search.daum.net/search?w=tot&q=%EB%B0%95%ED%9D%AC%EC%98%81&DA=ATG&rtmaxcoll=1TH 4 위: 차준환 link: https://search.daum.net/search?w=tot&q=%EC%B0%A8%EC%A4%80%ED%99%98&DA=ATG&rtmaxcoll=1TH 5 위: 25번째 코로나 환자 link: https://search.daum.net/search?w=tot&q=25%EB%B2%88%EC%A7%B8+%EC%BD%94%EB%A1%9C%EB%82%98+%ED%99%98%EC%9E%90&DA=ATG&rtmaxcoll=1TH 6 위: 유승민 link: https://search.daum.net/search?w=tot&q=%EC%9C%A0%EC%8A%B9%EB%AF%BC&DA=ATG&rtmaxcoll=1TH 7 위: 시흥시 매화동 link: https://search.daum.net/search?w=tot&q=%EC%8B%9C%ED%9D%A5%EC%8B%9C+%EB%A7%A4%ED%99%94%EB%8F%99&DA=ATG&rtmaxcoll=1TH 8 위: 최혜진 link: https://search.daum.net/search?w=tot&q=%EC%B5%9C%ED%98%9C%EC%A7%84&DA=ATG&rtmaxcoll=1TH 9 위: ufc link: https://search.daum.net/search?w=tot&q=ufc&DA=ATG&rtmaxcoll=1TH 10 위: 인교진 link: https://search.daum.net/search?w=tot&q=%EC%9D%B8%EA%B5%90%EC%A7%84&DA=ATG&rtmaxcoll=1TH Traceback (most recent call last): File "/Users/sangsoohan/Documents/Programing_Project/Project_Moneyball/python_crawling/section2/daum_ontime_issue.py", line 22, in <module> Print_Issue_And_Link(selector, i) File "/Users/sangsoohan/Documents/Programing_Project/Project_Moneyball/python_crawling/section2/daum_ontime_issue.py", line 18, in Print_Issue_And_Link print(num, "위: ", soup.select_one(selector.format(num)).string) AttributeError: 'NoneType' object has no attribute 'string' Process finished with exit code 1
Câu trả lời 2
1
안녕하세요.
열심히 하시네요.
불필요한 1개 태그가 더 조회되기 때문에 나오는 에러 같습니다.
1. 개수를 제한하셔도 되고
2. 정확한 css 선택자 태그를 사용하셔서 10개만 가져오시도록 하면 됩니다.
감사합니다.
현재 예제에서 error 발생
0
393
3
유튜브 동영상 다운로드
0
1486
2
Atom 에디터 관련
0
351
1
위시켓 폼데이터
0
284
1
스케줄러 사용 관련 질문 드립니다
0
643
1
selenium 에러
0
441
1
Progress bar 쓰레드 관련
0
499
1
Install Package 관련 문의
0
338
1
tkinter 샘플 코드 실행 오류 건
0
1280
1
4-7-6 네이버 & 카카오 주식 정보 가져오기
0
391
1
네이버자동로그인_by_selenium
0
883
1
위시캣 로그인 처리 및 크롤링 질문
0
355
1
2-8-1 네이버이미지 크롤링 질문
1
617
3
li:nth-of-type 질문
0
358
2
에러가 뜨는데 잘 모르겠어요ㅠ
0
406
2
Install Packages 항목이 안보이는 이유가 뭘까요?
0
411
2
환경변수 Path 설정 방법
0
644
1
웹 브라우저 없는 스크랩핑 및 파싱 실습(1) - 인프런
0
346
1
웹 브라우저 없는 스크랩핑 및 파싱 실습(1) -git주소
0
497
3
download2-8-1. py질문
0
213
1
ip 차단 당하는 거 같은데 아무리 랜덤주고, sleep 줘도 안 되는데 다른 방법 더 있을까요??
0
651
1
인프런 환경이 바뀌어서 제나름대로 하는데
0
199
1
다시올려주신 예제파일로하는데
0
195
1
아직도 에러가뜨나보네요?
0
591
1