
오토인코더를 특성 추출기로 사용하는 방법에 대해 질문
263
3 câu hỏi đã được viết
강의 내용을 바탕으로 저의 데이터를 가지고 적용하려하는데 질문이 있습니다.
제가 가지고 있는 데이터는 이렇습니다.
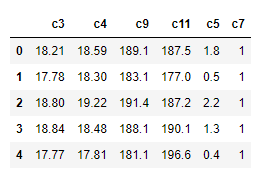
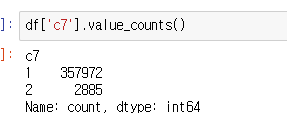

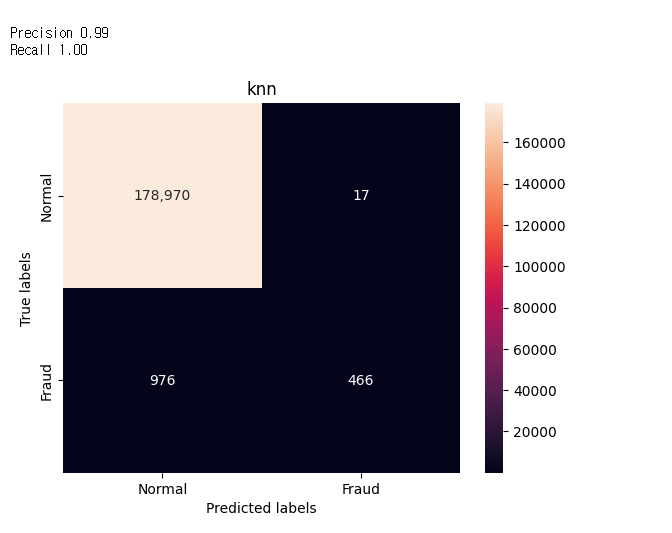
이것을 가지고 165번 파일을 바탕으로
c7을 제외하고 로그 스케일 후 동일하게 따라했는데 아래의 수치가 나왔습니다.
머가 잘못된 걸까요?
c7을 제외한 나머지 항목을 로그 스케일 했었는데 이곳이 문제일까요?
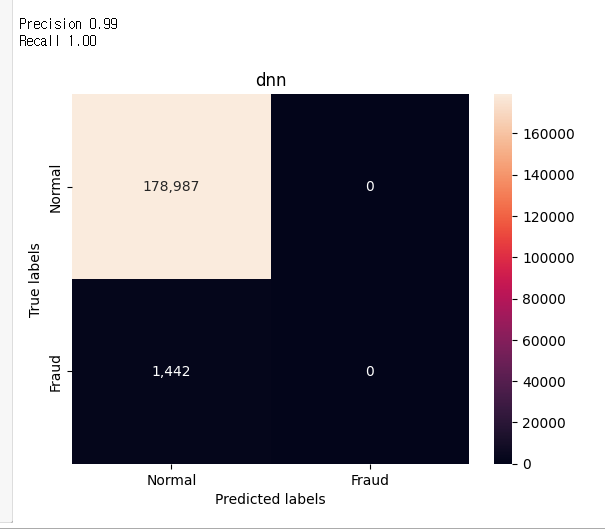
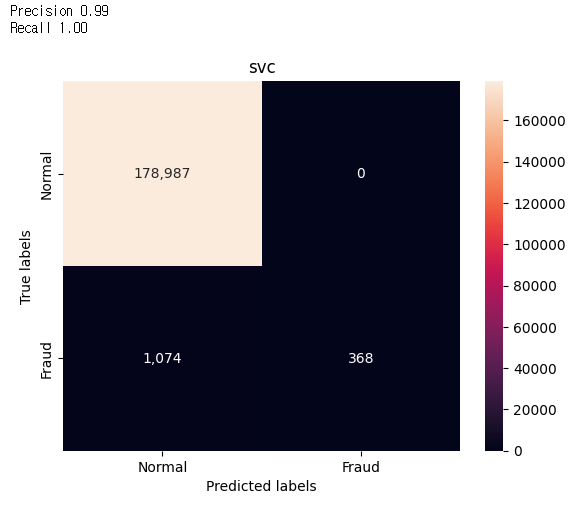
Câu trả lời 1
0
일단 c7을 1, 2 가 아니라 0, 1 로 바꾸시기 바랍니다. 교재에서는 다른 모든 column 값 들이 scaling 되어 있고 amount 만 큰 값이라서 log scale을 잡아 줬지만 수강자님의 데이터는 각 column 별로 log scale 을 잡을 성격이 아니라 전체적으로 standard scaling을 하시는 것이 맞는 것 같습니다. c7 이 label 이라면 c7 을 y 로 분리 하시고 나머지 X column 들에 대해 sklearn.preprocessing.StandardScaler 를 이용해서 normalize 하시기 바랍니다. 감사합니다.
0
c7을 label 로 사용하실 것 아닌가요? 2진 분류 모델은 sigmoid 를 activation 함수로 사용하고 binary crossentropy loss 를 이용하므로 0, 1 로 encoding 되어야 합니다. 감사합니다.
기출 11회 작업형 2_전체 데이터 학습 여부
0
13
1
예측값 결과 소수점 차이
0
17
2
여태까지 발견한 이슈들 공유드립니다.
1
17
1
기출 문제와 실전챌린지 연습문제 무엇부터 푸는게 나은가요?
0
14
0
전처리 train() test([ ])
0
15
2
작업형 1 배경지식 질문
0
19
2
옳게 풀은건지 질문드립니다!
0
14
1
roc_auc_score
0
22
2
추가질문 합니다
0
16
2
시험환경 구름
0
18
2
2유형 질문드려요
0
15
2
RandomForest vs lgb
0
23
2
전처리 관련질문
0
23
3
작업형3 기출
0
17
2
유형2에서 데이터분할 생략 가능여부
0
28
2
9회 기출 유형3 질문
0
19
2
오토인코더+ Knn, SVC 로 해석하는경우
0
67
3
VAE 모델 loss 계산하는 부분 오류
0
271
2
features 수가 작을 경우의 Dense 설정 문의
0
236
1
라이브러리 임포트 시 경고 메세지가 뜹니다.
0
578
1
실습: 001. Imbalanced Dataset Sampling 관련 질문
0
1185
2
깃헙의 자료와 강의의 실습 내용이 다릅니다.
0
274
1
섹션2. DNN 이진분류 part2에서 pos, neg에 대해 질문드립니다.
0
575
1
SMOTE를 활용한 데이터 생성
0
560
1