
-
질문 & 답변
카테고리
-
세부 분야
프로그래밍 언어
-
해결 여부
미해결
2020.11.29일
20.11.29 12:50 작성 조회수 225
1
여러분 naver blog가 2020년 경으로 바뀌었습니다

답변을 작성해보세요.
0

남박사
지식공유자2020.11.29
네이버 블로그 검색 기능이 리뉴얼 되었습니다.. 일단 기존의 블로그 검색결과각 VIEW 라는 카테고리로 변경되었으며 개발자 도구를 살펴보면...
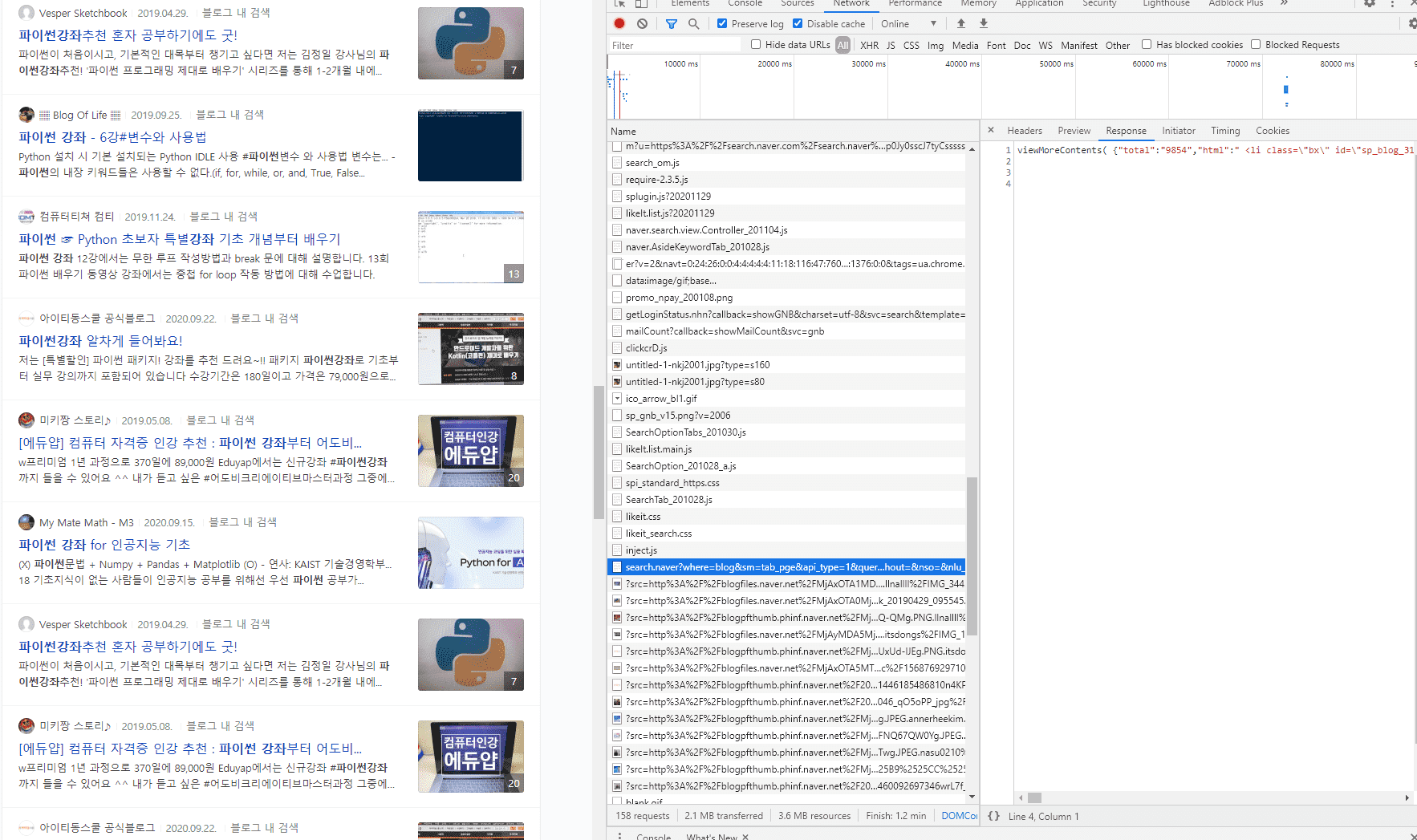
블로그 검색 결과를 스크롤 내려보면 스크롤 내리는 타이밍에 검색 결과가 추가되는걸로 보아 ajax로 통신하는것을 알수 있고 개발자 도구의 네트워크 탭에서 어떤 주소로 ajax 통신을 하는지 알 수 있습니다.
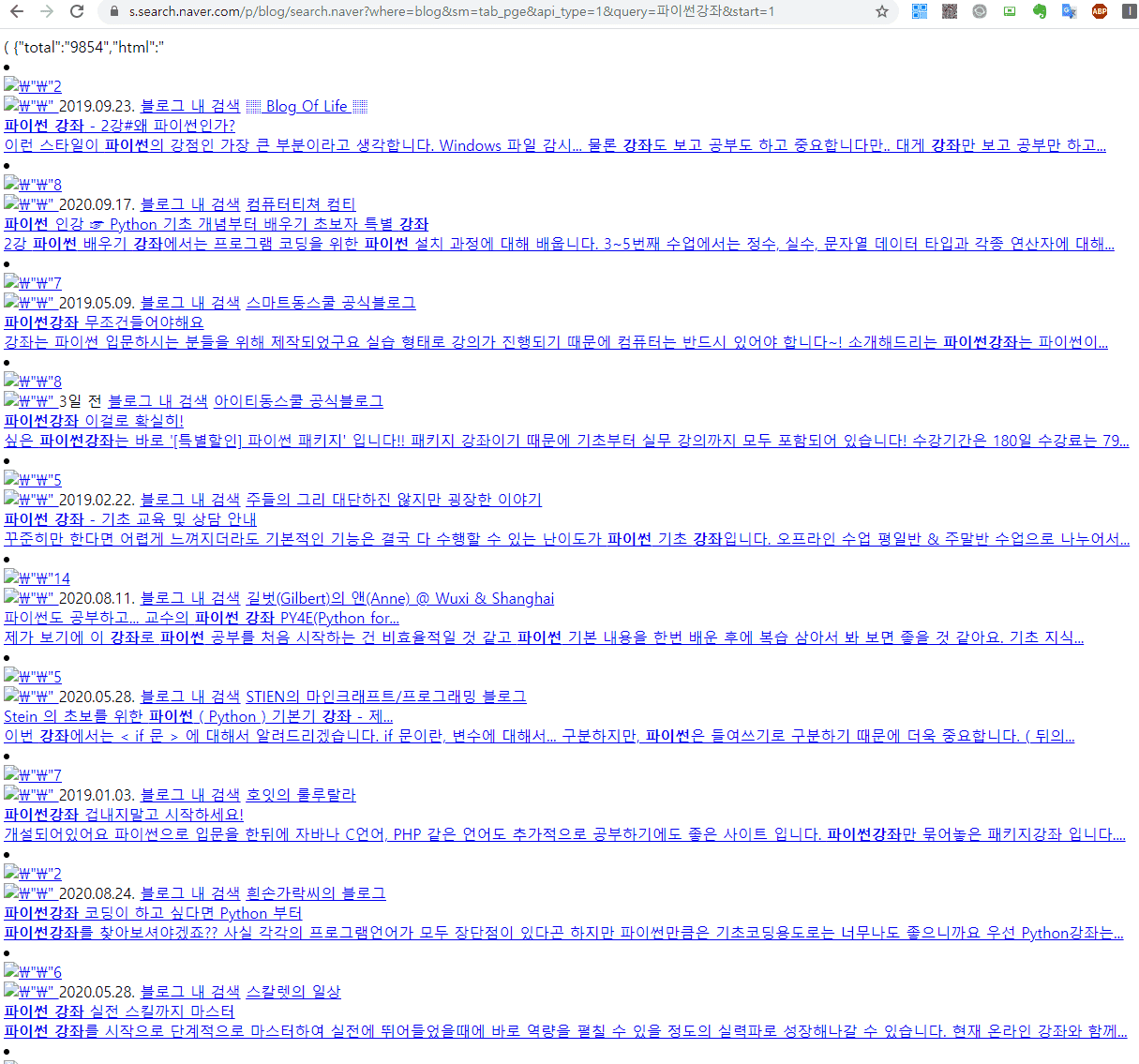
해당 ajax 통신하는 주소를 직접 접속해보면 위의 이미지처럼 결과가 나오는것을 확인할 수 있고 이를 분석하면 원하는 결과를 얻을 수 있습니다.
'''
함수화 시키고 페이징 기능 추가
'''
import requests
from bs4 import BeautifulSoup
import json
def get_search_naver_blog(keyword, start_page, end_page=None):
'''네이버 블로그 검색 함수
Args:
keyword (str): 검색어
start_page (int): 현재 페이지
end_page (int): 마지막 페이지
Returns:
list : 최종 결과 목록
'''
# 검색 URL 주소
# 네이버 페이징 처리는 1페이지, 2페이지 이런식이 아니라
# startpage= 로 1, 11, 21 이런식으로 시작게시물 수의 개념으로 봐야함
# url = "https://search.naver.com/search.naver?where=post&sm=tab_nmr&query={}&nso=&start={}".format(keyword, start_page)
# 2020-11-29 일 수정
# 웹페이지를 호출하면 아래의 주소로 ajax 통신을 하여 결과를 받아온 후 결과를 렌더링 하는 형태로 변경됨.
url = "https://s.search.naver.com/p/blog/search.naver?where=blog&sm=tab_pge&api_type=1&query={}&start={}".format(keyword, start_page)
r = requests.get(url)
# 받아온 결과에 total 이라는 문자열이 없으면 오류로 판단!!!
if r.text.find('total":"') < 0:
return []
# 데이터는 {"total":"갯수", "html":"블로그결과태그"} 형태로 넘어오는데
# 자바스크립과 파이썬의 이질성으로 dict 형태나 json 형태로 바로 가공이 되지 않아서
# 그냥 문자열로 처리함.
__find_string = 'total":"' # 최종 갯수를 먼저 파악하기 위해 결과갯수 추출
__result = r.text # request.get() 으로 얻은 텍스트 데이터
# 결과에서 HTML 태그를 분리해내기 위한 파싱
__html = __result[__result.find("<"):-1]
# 얻어온 결과는 자바스크립트로 동작하는 문자열이라 " 문자가 \" , ' 문자가 \' 로 되어있음 이를 파이썬에서 사용할 수 있게 제거
__html = __html[:-4].replace('\"', "").replace("\\", "").strip()
# total 문자열을 찾아서 원하는 갯수만 추출하기 위해서 파싱
'''
"total":"1234" 에서 1234값을 찾기위한 여정
1. 문자열.찾기('total":"') 이라는 글자의 시작위치 찾음
2. 시작위치에 total:":" 글자수만큼 더한곳이 실제 원하는 데이터의 위치임 "total":"1234" 에서 필요한건 1의 위치
3. 문자열 슬라이싱은 [시작:종료] 임
4. 시작위치는 total":" 위치 더하기 total":" 의 갯수만큼이 시작위치
5. 종료 위치는 "total":"1234" 에서 4 뒤의 " 여야 하기 때문에 " 문자를 total":" 이후에 나타는 " 를 찾아야 함
6. 5의 조건을 구현하면 문자열.찾기('"', 어디서부터)
7. 6의 어디서부터가 문자열.찾기(대상) + 대상.길이 가 됨
8. 아래의 코드는 이를 한줄로 작성한 코드임
# 문자열[문자열.찾기(대상) + 대상.길이 : 문자열찾기('"', 문자열찾기(대상) + 대상.길이))]
'''
tot_count = int(__result[__result.find(__find_string) + len(__find_string):__result.find('"', __result.find(__find_string) + len(__find_string))])
# lxml 파서를 사용해서 응답내용 BeautifulSoup 으로 변환하여 bs 에 저장
bs = BeautifulSoup(__html, "lxml")
# 최종 결과를 리턴할 리스트
results = []
if end_page is None:
# 총게시물 갯수 / 10 을 int 형으로 하면 end_page 값을 알 수 있음
end_page = int(tot_count / 10)
if end_page > 50:
end_page = 51
for li in bs.select("li"):
try:
title = li.select("a.api_txt_lines")[0].text
href = li.select("a.api_txt_lines")[0]["href"]
summary = li.select("a.total_dsc > div.api_txt_lines")[0].text
results.append((title, href, summary, ""))
except:
continue
# 현재 페이지가 마지막 페이지보다 작으면
if start_page < end_page:
# 현재 페이지에 + 10증가 후
start_page += 10
# 함수 스스로 재호출(재귀함수) 후 결과를 현재 results(결과를 리턴할 리스트)에 확장(extend) 시킴
results.extend(get_search_naver_blog(keyword, start_page, end_page))
# 최종 결과 리스트 리턴
return results
# 함수 호출
results = get_search_naver_blog("파이썬강좌", 1)
# 결과 출력
for r in results:
print(r)위는 수정된 코드이며 강좌 노트에 작성해놓았습니다.

답변 1