
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
멀티GPU시스템에 맞게 프로그램을 수정하고 싶습니다.
23.02.03 23:10 작성 조회수 368
0
늘 좋은 강의 해주셔서 감사합니다.
'[개정판] 딥러닝-컴퓨터비전-완벽가이드'를 수강하다가 질문이 있어서 글을 남깁니다.
제가 사용하는 멀티GPU시스템에서 'efficientdet_train_pascal_voc.ipynb'을 수정하여 원하는 GPU에서 프로그램을 동작하고 싶습니다.
'efficientdet_train_pascal_voc.ipynb'를 실행하는 도중
==================================================
if tf.config.list_physical_devices('GPU'):
ds_strategy = tf.distribute.MirroredStrategy(devices=["gpu:2", "gpu:3"])
else:
ds_strategy = tf.distribute.OneDeviceStrategy('device:CPU:0')
#steps_per_execution은 ModelCheckpoint의 save_freq를 숫자로 설정할 시 적용. num_epochs, steps_per_epoch는 추후에 model.fit()에서 설정되지만, 여기서는 일단 값을 설정해야함.
params = dict(
profile=TRAIN_CFG.profile,
mode = TRAIN_CFG.mode,
model_name=TRAIN_CFG.model_name,
steps_per_execution=TRAIN_CFG.steps_per_execution,
num_epochs = TRAIN_CFG.num_epochs,
model_dir=TRAIN_CFG.model_dir,
steps_per_epoch=steps_per_epoch,
strategy=ds_strategy,
# strategy=TRAIN_CFG.strategy,
batch_size=TRAIN_CFG.batch_size,
tf_random_seed=TRAIN_CFG.tf_random_seed,
debug=TRAIN_CFG.debug,
val_json_file=TRAIN_CFG.val_json_file,
eval_samples=TRAIN_CFG.eval_samples,
num_shards=ds_strategy.num_replicas_in_sync
)
config.override(params, True)
# image size를 tuple 형태로 변환. 512는 (512, 512)로 '1920x880' 은 (1920, 880) 으로 변환.
config.image_size = utils.parse_image_size(config.image_size)
==================================================
를 실행하면 다음과 같이 GPU:2와 3가 잡힙니다. (여기서 궁금한 점이 있는데요, 갑자기 왜 GPU:2와 3의 메모리를 22.7G나 잡아버리나요?)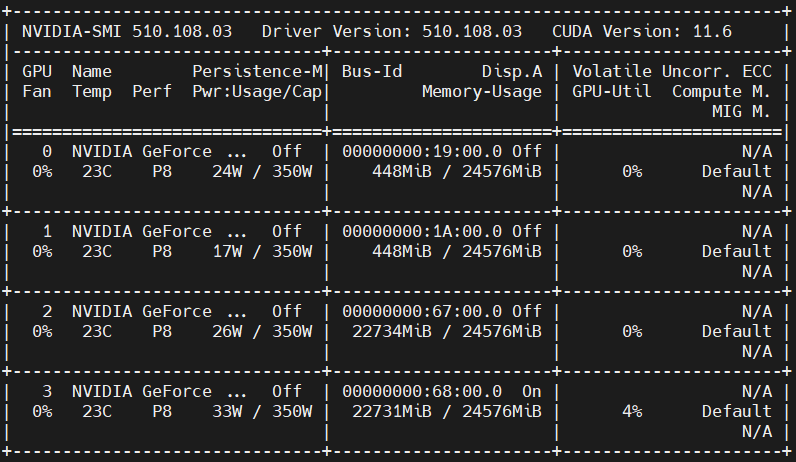
계속해서 'efficientdet_train_pascal_voc.ipynb'을 실행하다가 다음을 실행하면
======================================================
# 강의영상에는 from keras import anchors 이지만 efficientdet 패키지의 keras 모듈이 tf2 로 변경됨.
from tf2 import train_lib
from tf2 import train
# 20개의 class를 가진 efficientdet d0 모델을 생성.
model = train_lib.EfficientDetNetTrain(config=config)
======================================================
갑자기 GPU:0가 잡히면서, 그 이후의 모든 프로그램 코드가 GPU:0에서만 동작을 합니다. (GPU:2와 3은 아무런 동작이 없습니다. )
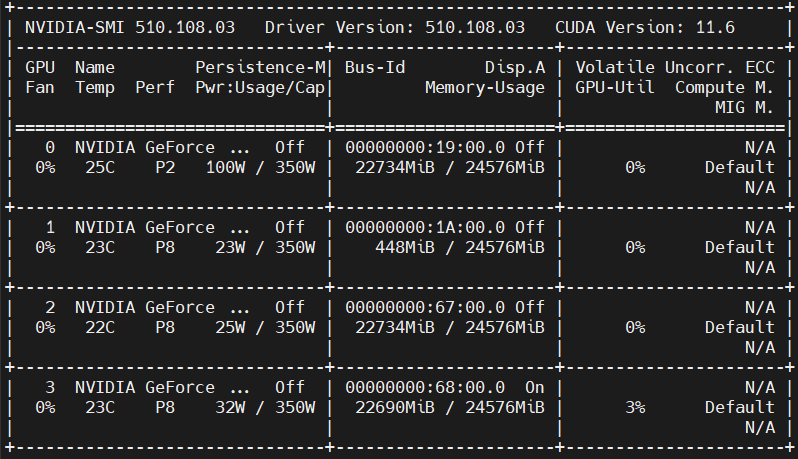
그래서 'train_lib.EfficientDetNetTrain(config=config)'을 고쳐보려고 하는데, 생각보다 쉽진 않네요... 구글 코랩에서 'EfficientDetNetTrain'을 찾아봐도 "A customized trainer for EfficientDet."이라고만 나와있습니다. 어떻게 해야할지 조언을 주세요...
감사합니다.

답변을 작성해보세요.
0

권 철민
지식공유자2023.02.04
안녕하십니까,
저도 EfficientDet을 Multi GPU로 학습해본 경험이 없어서 정확한 답변은 아닐 수 있습니다.
먼저 ds_strategy = tf.distribute.MirroredStrategy(devices=["gpu:2", "gpu:3"]) 를 적용하였기 때문에 단일 노드에서 가용 가능한 GPU 0 ~ 3을 사용하지 않고 2, 3만 사용하는 것 같습니다.
그리고 Tensorflow는 원래 모델 로딩 시 GPU의 가용 가능한 메모리를 기본적으로 다 잡습니다. 그래서 GPU2, GPU3의 메모리 사용량이 Full이 됩니다.
그런데 GPU 0 만 본격적으로 학습 시 사용된다는 것이 문제군요.
일단은 ds_strategy = tf.distribute.MirroredStrategy() 로 변경해서 GPU 0 ~ 3까지 메모리를 잡는지, 그리고 GPU가 학습을 분산 시키는지 다시 확인 부탁드립니다.

mcju
질문자2023.02.06
주말인데 빠른 답변을 주셔서 감사합니다.
먼저 제가 왜 멀티 GPU로 수행하려는 이유에 대해 말씀드리면,
'작업을 모든 GPU에서 분산 동작하고 싶어서가 아니라 원하는 GPU에서(GPU0가 아닌) 특정 작업을 수행하고 싶어서입니다.'
예를들면 'efficientdet_train_pascal_voc.ipynb' 수행시 'efficientdet-d0'는 GPU1에서, 'efficientdet-d2'은 GPU2에서, 'efficientdet-d4'는 GPU3에서 여러 작업을 동시에 수행하고 싶은데, 모든 작업이 GPU0에서만 동작하니 실질적으로 한번에 하나씩만 동작시킬 수 있습니다.
말씀하신 'ds_strategy = tf.distribute.MirroredStrategy()'로 세팅하면, 모든 GPU가 동작할 준비는 하는 걸로 보입니다.
제 GPU가 RTX3090 24GB라서 그런지 대부분의 메모리를 할당해 버리네요...

하지만 프로그램을 계속 수행하면 GPU0만 동작하는 걸 발견할 수 있습니다. (GPU:1, 2, 3은 아무런 동작이 없습니다. GPU3는 모니터가 연결되어 있어 조금의 동작(11%)이 일어나는 것 같습니다. )

이를 해결하기 위해 프로그램을 하나씩 추적하다보니 'model = train_lib.EfficientDetNetTrain(config=config)'을 수행하고 나서는 GPU0에 메모리가 잡히는 것을 발견해서 '여기를 수정해야 할 것 같다'는 생각을 했습니다.
다른 실습들에서는 제가 원하는 GPU에서(GPU0가 아닌) 특정 작업을 수행하는 것들이 가능했는데, 'efficientdet_train_pascal_voc.ipynb' 실습에서는 그게 안되어서 여쭤본 것입니다.
하여튼 감사합니다.
권 철민
지식공유자2023.02.06
음, 그러셨군요.
계속 해보시고, 정 안되시면 다시 글 부탁드립니다.
근데, efficientdet 자체에서는 되는데, efficientdet_train_pascal_voc.ipynb 만 그렇게 안되는 건가요?

답변 1