
-
질문 & 답변
카테고리
-
세부 분야
딥러닝 · 머신러닝
-
해결 여부
해결됨
GridSearchCV 와 관련하여 질문드립니다!
20.09.22 05:42 작성 조회수 222
0
1. 제가 실습해보려는 데이터셋이 40만 row 인데, 이 경우 cv 값을 몇으로 설정하는게 가장 좋은가요? 피쳐는 30개입니다.
2. 최적의 cv 값이 존재하나요? (가령 각 폴드 당 최적의 데이터 수가 존재한다든가...) 혹은 폴드 당 데이터 수가 많을수록 더 좋은건가요? 이 부분이 의문입니다 ㅠㅠ
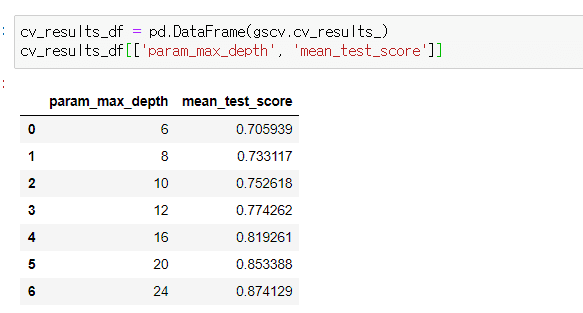
3. 아래에서 max_depth를 6~24까지 줬을 때 24가 최적 파라미터로 결과가 나와서 혹시나 하는 마음에 24~32까지 줘봤더니 32가 최적 파라미터로 나왔습니다. 원래 이렇게 max_depth 최적값이 크게 나올 수도 있는 건가요? 아니면 다른 문제가 있는 걸까요? 문제가 없다면 40 넘게 max_depth를 더 키워봐도 되는걸까요? 과적합이 발생하고 있는게 아닌지 걱정됩니다 ㅠㅠ

4. 분류의 다양한 알고리즘을 한 예제에 모두 사용해봤는데, 정확도가 엄청 상이했습니다.
만약 전처리를 하지 않은 raw 데이터셋으로 모두 동일하게 fit 했을 때 정확도가 10~20% 가량 차이가난다면,
정확도가 비교적 지나치게 낮은 알고리즘보다는 높은 알고리즘을 기준으로 튜닝하는게 맞는건가요?
아니면 전처리가 더 중요하기 때문에 전처리 이후 다시 다양한 알고리즘을 적용해보는게 우선시되는건가요?
5. 2진 분류가 아닌 레이블이 3개인 분류(다중 클래스 분류)를 할때는 어떤 검증 방법을 써야 하나요?
6. 5번과 비슷한 질문인데 다중 클래스 분류를 할 경우에는 부스팅 방법이 적합하지 않은 것인가요? 랜덤 포레스트를 제외한 모든 부스팅 알고리즘 정확도가 엄청 낮게 나옵니다ㅠㅠ (혹은 제가 원핫인코딩 방식을 사용하지 않은게 잘못일까요?? 현재 클래스가 연속성이 없는 0, 1, 2로 나뉘고 있습니다)

답변을 작성해보세요.
1

권 철민
지식공유자2020.09.22
안녕하십니까,
1과 2번 답변: 최적의 CV 갯수는 없습니다만, 데이터 세트 크기로 봐서는 CV=5 정도가 적합해 보입니다.
3. max_depth 더 큰 값을 넣으셔도 상관없습니다. 다만 max_depth이외에 다른 파라미터를 테스트 하고 있으시지 않기 때문에 성능이 최적화 되고 있다고 보기는 힘들것 같습니다. 여러 파라미터와 결합해서 테스트 해보시지요
4. 전처리 하지 않았는데 10~20% 차이가 난다면 전처리 부터 해야 합니다. 그런데 전처리 하지 않았다고 10~20% 까지 차이가 나는 경우는 흔하지 않습니다.
5. 이진 분류와 다중 분류의 검증 방법은 서로 큰 차이가 없지만 다중 분류는 일반적으로 정확도를 성능 지표를 사용하는 경향이 있지만, 이는 적용하는 업무별로 다른 지표를 사용할 수도 있습니다.
6. 랜덤 포레스트는 매우 뛰어난 알고리즘입니다. 하지만 부스팅이 랜덤 포레스트보다 많이 떨어지는 경우는 흔하지 않습니다. xgboost나 lightgbm을 사용하셨는데 성능이 얼마정도 떨어진건지 다시한번 말씀해 주십시요. 트리기반 알고리즘은 원-핫 인코딩을 사용하지 않았다고 성능이 크게 저하되지 않습니다.
그리고 '현재 클래스가 연속성이 없는 0, 1, 2로 나뉘고 있습니다' 라는 의미를 제가 이해하지 못했습니다. 다시 한번 재 정의 부탁드립니다.
감사합니다.


답변 1