
-
질문 & 답변
카테고리
-
세부 분야
데브옵스 · 인프라
-
해결 여부
해결됨
대쉬보드 문제
20.09.01 23:26 작성 조회수 485
1
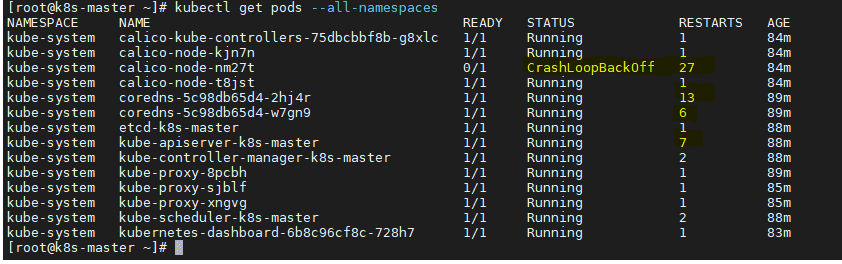
안녕하세요. 위처럼 자꾸 CrashLoopBackoff가 되며 Restarts하는 것들이 많습니다.
또한, 노드를 다 올렸는데도,
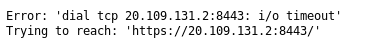
이런 에러가 나서, 대쉬보드가 안올라오네요.. 이유를 알 수 있을까요?
참고로 아래 정보 드립니다.
[root@k8s-master ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc mq state UP group default qlen 1000
link/ether 42:01:0a:aa:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.170.0.2/32 brd 10.170.0.2 scope global dynamic eth0
valid_lft 2416sec preferred_lft 2416sec
inet6 fe80::4001:aff:feaa:2/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:2d:a2:2e:59 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 20.108.82.192/32 brd 20.108.82.192 scope global tunl0
valid_lft forever preferred_lft forever
5: calied26a64eb57@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1440 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
[root@k8s-master ~]# ps -ef|grep proxy
root 1661 1599 3 13:15 ? 00:02:28 kube-apiserver --advertise-address=10.170.0.2 --allow-privileged=true --authorization-mode=Node,RBAC --client-ca-file=/etc/kubernetes/pki/ca.crt --enable-admission-plugins=NodeRestriction --enable-bootstrap-token-auth=true --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key --etcd-servers=https://127.0.0.1:2379 --insecure-port=0 --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key --requestheader-allowed-names=front-proxy-client --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --requestheader-extra-headers-prefix=X-Remote-Extra- --requestheader-group-headers=X-Remote-Group --requestheader-username-headers=X-Remote-User --secure-port=6443 --service-account-key-file=/etc/kubernetes/pki/sa.pub --service-cluster-ip-range=10.96.0.0/12 --tls-cert-file=/etc/kubernetes/pki/apiserver.crt --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
root 1680 1605 1 13:15 ? 00:01:22 kube-controller-manager --allocate-node-cidrs=true --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf --bind-address=127.0.0.1 --client-ca-file=/etc/kubernetes/pki/ca.crt --cluster-cidr=20.96.0.0/12 --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt --cluster-signing-key-file=/etc/kubernetes/pki/ca.key --controllers=*,bootstrapsigner,tokencleaner --kubeconfig=/etc/kubernetes/controller-manager.conf --leader-elect=true --node-cidr-mask-size=24 --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt --root-ca-file=/etc/kubernetes/pki/ca.crt --service-account-private-key-file=/etc/kubernetes/pki/sa.key --use-service-account-credentials=true
root 1963 1922 0 13:15 ? 00:00:03 /usr/local/bin/kube-proxy --config=/var/lib/kube-proxy/config.conf --hostname-override=k8s-master
root 3786 2440 0 14:07 pts/1 00:00:00 kubectl proxy --port=8001 --address=10.170.0.2 --accept-hosts=^*$
root 4343 3806 0 13:37 ? 00:00:00 /usr/libexec/gsd-screensaver-proxy
root 25421 16253 0 14:28 pts/0 00:00:00 grep --color=auto proxy
[root@k8s-master ~]# kubectl version
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.5", GitCommit:"20c265fef0741dd71a66480e35bd69f18351daea", GitTreeState:"clean", BuildDate:"2019-10-15T19:16:51Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.12", GitCommit:"e2a822d9f3c2fdb5c9bfbe64313cf9f657f0a725", GitTreeState:"clean", BuildDate:"2020-05-06T05:09:48Z", GoVersion:"go1.12.17", Compiler:"gc", Platform:"linux/amd64"}

답변을 작성해보세요.
1

꼬꼬꼬
질문자2020.09.02
헐 강사님... 저 성공했어요 ㅠㅠ dashboard까지 잘 나옵니다... 너무 감격스럽네요...ㅠㅠㅠ
강사님 자료 + 구글링을 통해서 성공했습니다...
다른사람들 질문도 엄청 많이 봤는데 저처럼 cloud를 통해 vm하나씩 구축하는 사람들이 저와같은 문제가 많은거 같더라구요..
엄청 구글링하다가 쿠버네티스 네트워크 plugin(calio)에 대한것을 알게되었어요.(솔직히 뭔지 잘 모릅니다.)
근데 calio로 절대 안되는것 같아서 weavenet이라는 것을 찾아서 설치했더니 바로 되더군요. 아마 저처럼 cloud를 통해 하시는 분들은 이걸로 하시면 될것같아요... 이글을 누가 읽을지는 모르지만요..
그리고, gcp 외부 ip로 접속이 안되서 master에 gnome인가? gui로 볼수 있는것을 설치후, 윈도우 원격접속(외부ip로 접속) 후, firefox(인터넷접속)을 통해 localhost:8001~~~(자료실 dashboard 접속 링크)로 접속했더니 dash board 나왔습니다. ㅠㅠㅠ
>> 참고자료 링크 : https://zerobig-k8s.tistory.com/31?category=297761
>> 완료 사진

*) calio대신 weave설치사진
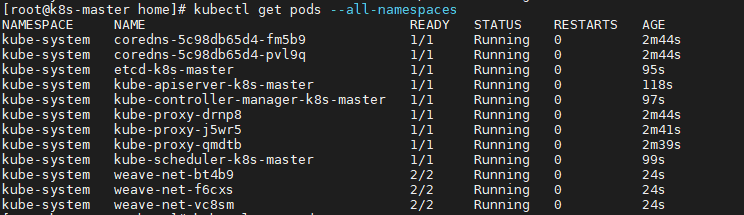
*) all running 및 ready상태 0 없음
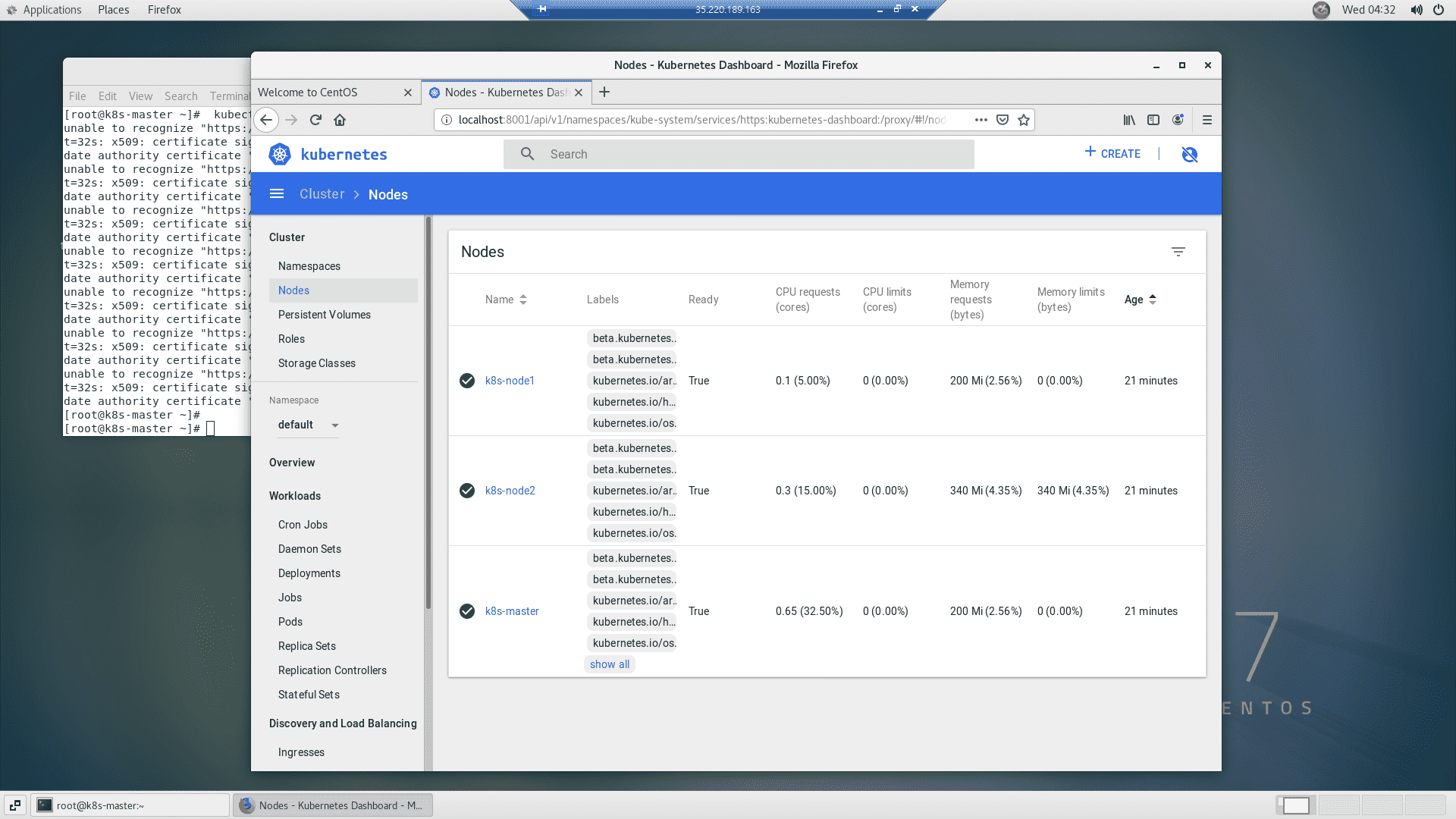
*) 원격접속 후 dashboard 확인완료
저의 추가 질문이 있다면.
1. 외부 ip를 통해 제 로컬 pc에서 dashboard를 접속하고 싶습니다. 방화벽 다 오픈했는데도 안되네요.. 방법알 수 있을까요?
2. 네트워크 plugin이 뭔지 간단히 설명해주실 수 있을까요?
많은 도움 감사드립니다.
0

일프로
지식공유자2020.09.02
짝짝짝 설치 축하드립니다!
1. 저도 GCP 환경에 대해서는 전문가가 아니라 잘 모릅니다. ㅎㅎ 앞으로도 GCP환경을 사용했을 경우 이와같이 제 강의 내용과는 다른 부분이 발생될 수 있고요. 그래도 이렇게 하나씩 해결하면서 잘 진행하실 수 있으실것 같네요.
2. 해당 내용에 대한 강의는 현재 [아키텍쳐편] Networking 부분을 연재하고 있고 빠르면 이번 주말내로 업로드할 예정이고,
간단하게는 해당 플러그인이 모든 Pod들간의 통신 담당하고 있습니다.
감사합니다.
0
꼬꼬꼬
질문자2020.09.02
calico 최신버전을 설치하려니까 이렇게 뜨네요ㅠㅠ.. 그래서 그냥 원래 자료실에서 나와있는데로 다시 설치했는데요.
다시 했더니 같은 문제가 생기네요. calico node가 0/1이고 계속 restarts되요..
... cluster ip, pod ip등은 어떻게 확인해야할까요.. 네트워크 문제같은데 잘모르겠네요ㅠㅠ
gcp에서 vm올려서 실행하고 있는것입니다..
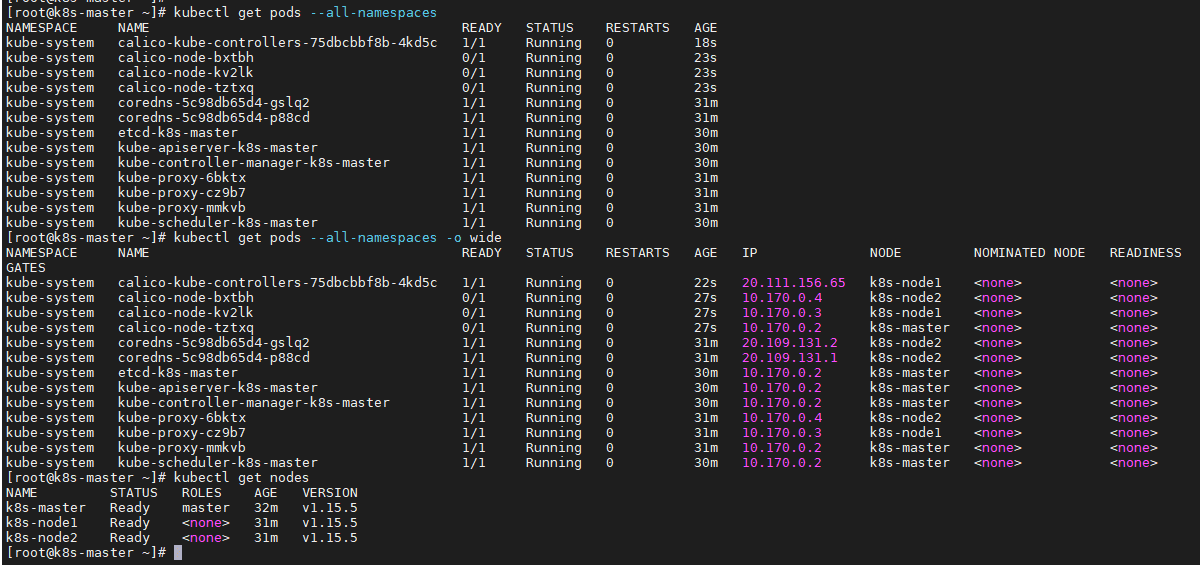
그리고 궁금한게...gcp인 경우 master를 못들어가도 강의듣는데 지장은 없을까요?
0
일프로
지식공유자2020.09.02
일단 컴포넌트들이 restart가 되더라도 ready 1/1 Running이되고 restart 수치가 계속 올라가지 않는 컴포넌트 들은 현재 문제가 없다고 보시면됩니다.
하지만 그렇지 않고 restart 숫자가 계속 올라가면 문젠데
calico나 dns관련 Pod들이 문제가 있어 보이네요. 이게 잘못되는 경우는 일반적으로 network 문제입니다. network 문제는 본인이 꼼꼼이 챙겨봐야 하는 문제라 제가 드리는 답변이 정확하지 않을 수 있습니다.
일단 calico node Pod들 중에서 하나만 계속 restart가 올라가는것 처럼 보이는데
kubectl get pods --all-namespaces -o wide 명령을 사용하면 해당 pod가 어느 node위에 올라갔는지가 나옵니다.
kubectl get nodes 명령을 통해 모든 node들이 ready 상태인지도 확인해 보시면 좋고요.
그걸보고 만약 해당 node와 통신이 안되고 있다면 안되는 원인을 찾아야 합니다 .
그리고 만약 node에 문제가 없다면, calico 설치를 다시 해보시겠어요?
일단 기존 내용을 삭제하고
kubectl delete -f calico.yaml
아래 내용으로 calico 최신버전을 설치해 보시기 바랍니다.
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
calico가 정상적으로 작동하지 않으면 dashboard도 안되는게 맞아요.

답변 4