인프런 커뮤니티 질문&답변
작성한 질문수

알고리즘 예측확률
해결된 질문
20.06.03 15:18 작성
·
539
0
안녕하세요 이번에 weka 중급 강좌를 수강하게된 수강생입니다.
현재 제가 몇가지 요인들을 가지고 ( 나이, 성별, 현재상태 등등) 21가지 정도의 요인을 가지고
질병인지 아닌지 예측을 하는걸 돌리고있는데 확률이 아무리 높아도 70~80%대 더라구요 ... 종류별로 거의 모든 알고리즘을 써봤는데
현재 153개의 데이터를 가지고 있어서 예측 확률을 90%이상을 나오게하려면 153개중에 90%를 트레이닝 시켜야 90%가 넘기던데 사실상 .. 153개중에 90% 트레이닝 시키고 10%를 테슽해봤자 15개밖에안하는거라 .. ㅠㅠ.. 다른방법으로 예측 확률을 높이는 방법이 있을까해서 질문을 남겨봅니다 .. 제가 어떤걸 해야 확률이 올라갈까요 ? 구글링을 통해서 예측하는데 관여율이 높았던 변수들 수치를 봐도 가장 높은게 0.15 정도고 나머지도 0.1 정도씩 요인들이 많아서그런지 고만고만하더라구요 .. 그래서 어떤 변수들을 빼야되는지도 잘 모르겠네요 ㅠㅠ.. 혹시 다른 방법이 있을까요 ?
답변 7
1
1
2020. 06. 08. 19:07
강의에 특징(속성)선택 동영상을 참조해주세요.
질문하신 내용이 포함됩니다.
특징선택도 알고리즘이 많으니 여러개를 조합해서 선택하시는 것을 추천드립니다.
1
2020. 06. 07. 13:27
안녕하세요.
질문주신 내용을 답변드리면서 보완할 수 있는 아이디어가 생각나서
관련내용을 동영상으로 업로드 하였습니다.
섹션 8 번외편에 Experimenter 시각화 제목으로 올려놨습니다.
앞으로도 좋은 질문에서 영감을 얻은 아이디어나 다른매체의 좋은 내용은
선별해서 번외편으로 동영상으로 제작하여 강의에 추가하겠습니다.
1
2020. 06. 03. 20:22
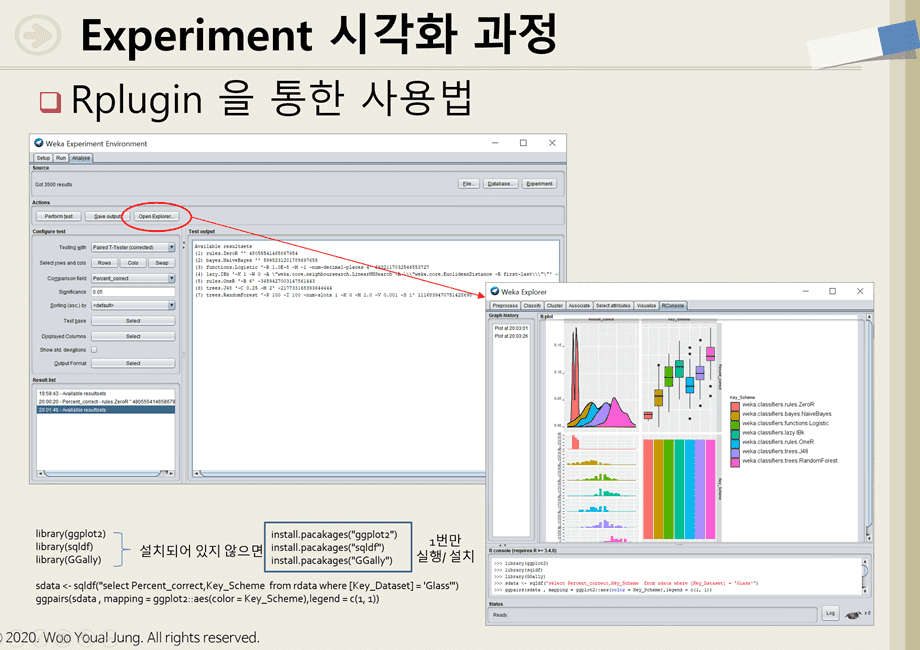
Experimenter 로 비교검정된 수치정보를 weka 에서 시각화 할 수 없는지 문의하셨습니다.
Weka 는 약한 시각화 기능을 보완하기 위해 R 과 Python 을 plugin 을 제공하여
Weka 에서 R 과 Python 연동을 지원합니다만,
결국 확률밀도함수와 같은 그래프 시각화는 R 과 Python 코딩작업을 해야 합니다.
만약 R 과 Python 에서 분석하시고자 코딩을 위해 비교검정 데이터를 받으시고 싶다면
아래 2가지 방법을 참조하십시요.
첫번째는 Experimeter 의 시작인 "Setup" 패널에서 "Result Destination" 에
물리적인 파일명을 설정하면 비교검정 결과를 arff 나 csv 파일로 받을 수 있습니다
두번째는 Experimeter의 결과인 "Analyse" 패널에서 "Open Explorer" 을 클릭하면
weka Exlplorer 의 전처리 패널로 이동하면서 비교검정 결과를 raw data 로 확인할 수 있고
"save" 를 클릭하여 arff 나 csv 파일로 받을 수 있습니다
감사합니다.
1
2020. 06. 03. 15:42
질문 주셔서 감사합니다.
1. 70~80% 예측률 향상
어떤 경우에 어떤 알고리즘이 적합하다고 하는 것은 선입견 입니다.
따라서 질병예측에 적합한 알고리즘을 미리 정하지 마시고 Experimenter 로 다양한 알고리즘을 비교검정 해보십시요.
강의내용에 Experimenter 사용법을 참고해 주세요.
2. 적은양의 데이터 과적합 우려
데이터 건수가 적은 것은 3가지 보완책이 있습니다.
다만 이들은 이론적인 대안 일뿐입니다.
첫째, 가능한한 더 많은 데이터 확보
둘째, 분할검증이 아닌 10 이상 교차검증 실시
세째, 독립변수 데이터 형태가 수치형이면 표준화와 정규화 필터링후 학습 후 Experimenter 로 비교검정
굉장히 이론적인 답변이죠?
데이터 건수가 적은 것은 대표성을 나타내기 어렵기 때문에 더 많은 데이터 확보가 답입니다.
그러나 어디 현실이 그런가요?
따라서 교차검증 및 표준화/정규화 필터링이 약간의 대안은 될수 있습니다.
일단 실행해 보시죠.
그러면 의외의 결과를 얻을 수 있습니다.
감사합니다.
0
2020. 06. 08. 18:36
헉 !.. 감사합니다 영상까지 만들어주실줄이야 ... 너무 큰 도움이 되었습니다 ㅠㅠ..
하다보니 자꾸 질문이 생기네요 ,, 너무 질문을 많이 올리는것 같아 죄송합니다 ㅜㅜ..
이전에 말씀드린대로 확률을 계속 올리려고 노력중인데 데이터확보가 어려운 상황이라 .. 일단 최대한 노력 중인데
weka에서 feature engineering이 제가 하고있는것이 맞는가 해서 질문 드립니다 .. 우선 가지고 있는 변수들이라도 조합을 하거나
관련도가 적은건 없애려하고있는데 Explorer - Select attributes - Attribute Evaluator(CfsSubsetEVal - P1 -E 1), Serch Method(BestFirst - D 1 N 5) 둘다 기본값으로 하고 Start를 하니 결과값에 Selected attributes로 7가지의 변수가 뜨던데 이 변수들이 가장 관련이 높은 변수들이 맞는건가요 ? .. 아니면 새로운 feature engineering 방법이 있을까요 .. ㅠㅠ 다시한번 질문을 너무 많이 드려 죄송합니다
0
2020. 06. 03. 16:48
두번째, 세번째 방법 모두 해본 방법이지만 아주 미미하게 오를뿐 많이는 안오르더라구요 ㅠㅠ.. 결국 답은 데이터 확보겠군요 .. 감사합니다 다른 질문이긴한데 Experimernter 로 다양한 알고리즘끼리의 확률을 서로 비교검증하는걸 수치로는 확인 했는데 이걸 시각화해서 2d나 3d 형태의 그래프로 나타내고싶은데 혹시 weka에서 바로 그런 시각화 된걸 확인 할 수도 있는가 해서 질문 드립니다.
하려면 파이썬같은 다른 프로그래밍언어들을 사용해서 직접 코딩을 해야 될까요 ?