
-
질문 & 답변
카테고리
-
세부 분야
컴퓨터 비전
-
해결 여부
미해결
local setting 질문
21.08.04 13:10 작성 조회수 402
0
안녕하세요 강사님
좋은 강의 감사합니다.
object detection을 local pc에 세팅해보고자 하는데
올려주신 code를 그대로 실행하는데 에러가 자꾸 납니다.
제 환경은 아래와 같습니다.
CPU : i5-10400
GPU : RTX3060
SW :
- torch 1.9.0
- cuda 11.4
- mmdet : 2.14.0
- mmcv : 1.3.9
두가지 질문을 드리고자 합니다.
1. 아래와 같은 에러는 어떻게 잡아야 하는지 궁금합니다.
mm_faster_rcnn_train_kitti.ipynb file 에서
train_detector(model, datasets, cfg, distributed=False, validate=True) # <= 왼쪽 코드를수행 할 때 에러가 납니다.
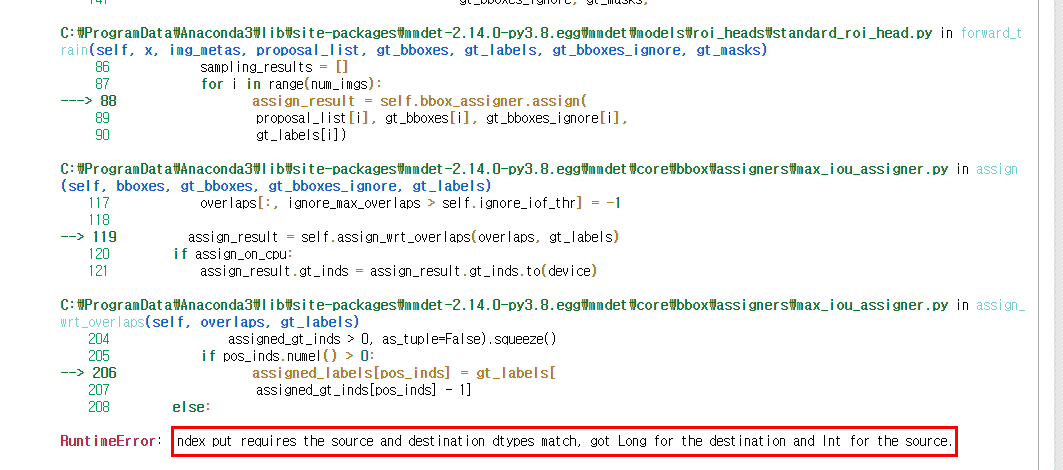
위 결과를 보는것도 mmdet나 mmcv 코드를 열어서 확인하면서 하나씩 수정하면서 보고 있습니다.
위 결과 이전에는 아래와 같은 에러가 났었습니다.

위 에러를 수정하기 위해서 site-packages/mmdet/datasets/builder.py 126번 줄에 num_workers=0 라는 코드를 추가하니 문제가해결되었는데 바로 질문 1번에 있는 에러가 나왔습니다.
이렇게 하나씩 에러를 해결하는 게 쉽지 않습니다.
언제 local에서 학습을 해볼 수 있을지 걱정이 많습니다.
어떻게 하는게 좋을까요?
2. local에 setting하는 방법에 대한 설명을 추가로 요청드려도 될까요?
가능하다면 local setting하는 방법에 대한 설명을 요청드리고 싶습니다!
좋은 강의 감사합니다!

답변을 작성해보세요.
1
0

odod
질문자2021.08.06
강사님 답변 감사합니다!
강사님 강의와 답변 덕분에 빠른 시간안에 detection model 학습 시켜서
생각보다 아주 아주 좋은 성능의 detector를 만들었습니다.
custom data가 제가 볼땐 생각보다 애매한 데이터 들이 많아서
detection시에 혼동하는 경우가 많을 줄 알았는데
정식 테스트를 거치지는 않았지만 거의 95% 검출해 냅니다.
진짜 성능 끝내줍니다.
mmdetection을 사용하니 정말 빠른 시간에 모델을 만들 수 있네요!
딥러닝 처음 한지는 오래되었지만, 딥러닝에만 집중하지 못해 4년이라는 시간만큼 뒤쳐져 있었는데
강의 집중해서 듣고 3일만에 segmentation model까지 만들었습니다.
다들 어떻게 이렇게 빨리 만들었냐고 물어보네요 ㅎㅎ
좋은 강의 감사합니다!
남은 부분도 열심히 듣고 궁금한 점이 있으면 또 질문 드리겠습니다!
0
odod
질문자2021.08.04
마지막으로 하나 더 질문이 있습니다!
제가 아래와 같이 config file을 만들어서 돌렸는데
혹시 한번이라도 train된 model은 어디에 저장되는지 궁금합니다.
0
odod
질문자2021.08.04
해당 내용이 어디서 수정되어야 하는지 좀 더 찾아보고 수정한 뒤에 결과 공유드리도록 하겠습니다.
추가로 질문이 있습니다.
개인적으로 가지고 있는 데이터셋을 학습시키려고
https://mmdetection.readthedocs.io/en/latest/tutorials/customize_dataset.html
위 링크에 있는 내용을 따라서 세팅한 뒤에
```
python tools\train.py configs\my_data\mask_rcnn_r50_caffe_fpn_mstrain-poly
```
위 명령으로 학습을 진행시켰습니다.
두가지 문제가 발생했는데
첫번째로는

type이 맞지 않는 문제가 3번 연달아 발생했습니다.
해당 파일로 이동해서 곱샘의 형태를 아래와 같이 변경하였습니다.
#p[0::2] *= w_scale # origin
#p[1::2] *= h_scale # origin
p[0::2] = p[0::2] * w_scale # fixed
p[1::2] = p[1::2] * h_scale # fixed
곱셈하는곳 두곳과 뺄셈하는 곳 한 곳을 수정하니 정상적으로 train이 시작되었는데 문제가 없는 행동일지 걱정됩니다.
두번째로는
첫번째 epoch 학습이 완료된 이후에 다음과 같은 에러메세지가 나왔습니다.
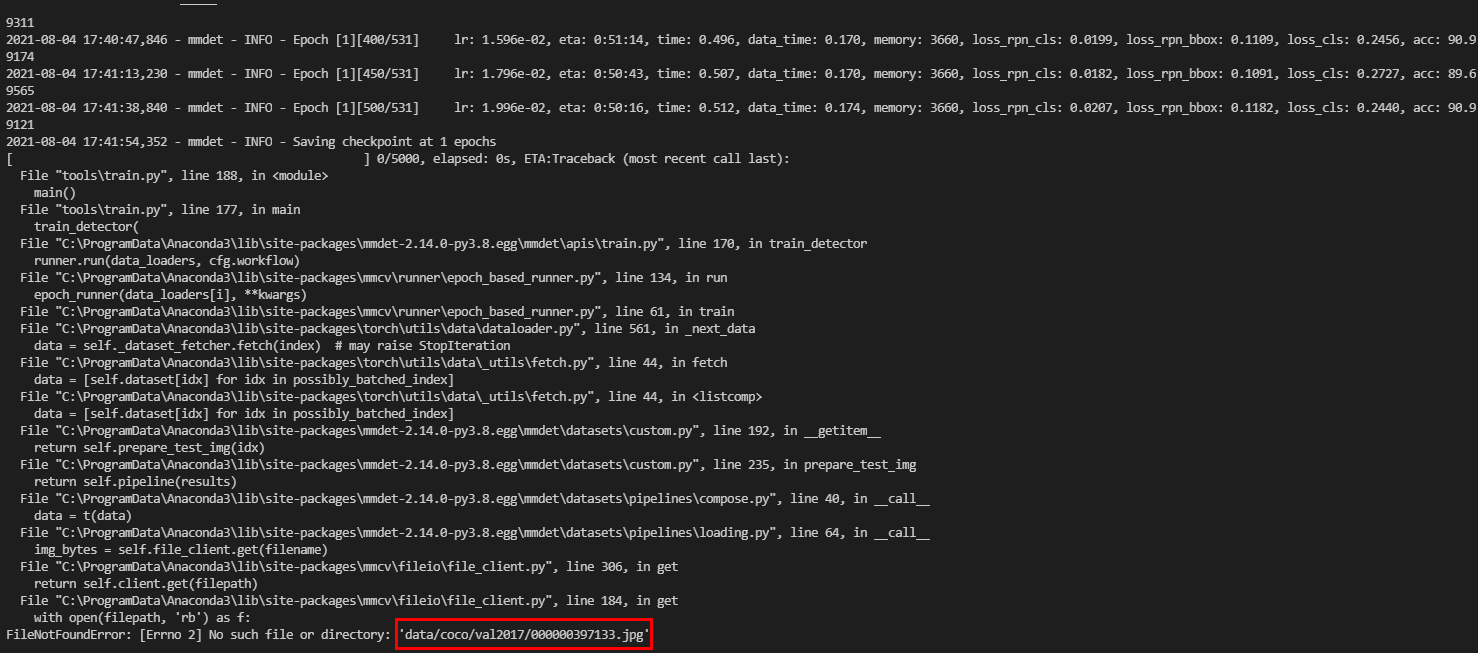
저 이미지를 왜 읽으려고 하는건지 궁금합니다.
위 이미지를 읽고자 하는거라면 정상적으로 학습이 되는 상태인게 맞을까요?
답변감사합니다
0

권 철민
지식공유자2021.08.04
해당 부분을 수정하고 다시 돌려보시겠습니까. 처음 오류가 Boxassigner 관련 같은데 해당 config 내용에 anchor box등의 설정과 관련된 부분이 있는것 같습니다
0
odod
질문자2021.08.04
안녕하십니까 강사님.
답변 감사합니다.
데이터셋 생성 코드와 config 설정 코드는 아래와 같습니다.
1. 데이터셋 생성 코드
import copy
import os.path as osp
import cv2
import mmcv
import numpy as np
from mmdet.datasets.builder import DATASETS
from mmdet.datasets.custom import CustomDataset
# 반드시 아래 Decorator 설정 할것.@DATASETS.register_module() 설정 시 force=True를 입력하지 않으면 Dataset 재등록 불가.
@DATASETS.register_module(force=True)
class KittyTinyDataset(CustomDataset):
CLASSES = ('Car', 'Truck', 'Pedestrian', 'Cyclist')
##### self.data_root: /content/kitti_tiny/ self.ann_file: /content/kitti_tiny/train.txt self.img_prefix: /content/kitti_tiny/training/image_2
#### ann_file: /content/kitti_tiny/train.txt
# annotation에 대한 모든 파일명을 가지고 있는 텍스트 파일을 __init__(self, ann_file)로 입력 받고, 이 self.ann_file이 load_annotations()의 인자로 입력
def load_annotations(self, ann_file):
print('##### self.data_root:', self.data_root, 'self.ann_file:', self.ann_file, 'self.img_prefix:', self.img_prefix)
print('#### ann_file:', ann_file)
cat2label = {k:i for i, k in enumerate(self.CLASSES)}
image_list = mmcv.list_from_file(self.ann_file)
# 포맷 중립 데이터를 담을 list 객체
data_infos = []
for image_id in image_list:
filename = '{0:}/{1:}.jpeg'.format(self.img_prefix, image_id)
# 원본 이미지의 너비, 높이를 image를 직접 로드하여 구함.
image = cv2.imread(filename)
height, width = image.shape[:2]
# 개별 image의 annotation 정보 저장용 Dict 생성. key값 filename 에는 image의 파일명만 들어감(디렉토리는 제외)
data_info = {'filename': str(image_id) + '.jpeg',
'width': width, 'height': height}
# 개별 annotation이 있는 서브 디렉토리의 prefix 변환.
label_prefix = self.img_prefix.replace('image_2', 'label_2')
# 개별 annotation 파일을 1개 line 씩 읽어서 list 로드
lines = mmcv.list_from_file(osp.join(label_prefix, str(image_id)+'.txt'))
# 전체 lines를 개별 line별 공백 레벨로 parsing 하여 다시 list로 저장. content는 list의 list형태임.
# ann 정보는 numpy array로 저장되나 텍스트 처리나 데이터 가공이 list 가 편하므로 일차적으로 list로 변환 수행.
content = [line.strip().split(' ') for line in lines]
# 오브젝트의 클래스명은 bbox_names로 저장.
bbox_names = [x[0] for x in content]
# bbox 좌표를 저장
bboxes = [ [float(info) for info in x[4:8]] for x in content]
# 클래스명이 해당 사항이 없는 대상 Filtering out, 'DontCare'sms ignore로 별도 저장.
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_labels_ignore = []
for bbox_name, bbox in zip(bbox_names, bboxes):
# 만약 bbox_name이 클래스명에 해당 되면, gt_bboxes와 gt_labels에 추가, 그렇지 않으면 gt_bboxes_ignore, gt_labels_ignore에 추가
if bbox_name in cat2label:
gt_bboxes.append(bbox)
# gt_labels에는 class id를 입력
gt_labels.append(cat2label[bbox_name])
else:
gt_bboxes_ignore.append(bbox)
gt_labels_ignore.append(-1)
# 개별 image별 annotation 정보를 가지는 Dict 생성. 해당 Dict의 value값은 모두 np.array임.
data_anno = {
'bboxes': np.array(gt_bboxes, dtype=np.float32).reshape(-1, 4),
'labels': np.array(gt_labels, dtype=np.long),
'bboxes_ignore': np.array(gt_bboxes_ignore, dtype=np.float32).reshape(-1, 4),
'labels_ignore': np.array(gt_labels_ignore, dtype=np.long)
}
# image에 대한 메타 정보를 가지는 data_info Dict에 'ann' key값으로 data_anno를 value로 저장.
data_info.update(ann=data_anno)
# 전체 annotation 파일들에 대한 정보를 가지는 data_infos에 data_info Dict를 추가
data_infos.append(data_info)
return data_infos
2. config 코드는 아래와 같습니다.
### Config 설정하고 Pretrained 모델 다운로드
config_file = './mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = './mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
from mmcv import Config
cfg = Config.fromfile(config_file)
print(cfg.pretty_text)
from mmdet.apis import set_random_seed
# dataset에 대한 환경 파라미터 수정.
cfg.dataset_type = 'KittyTinyDataset'
cfg.data_root = './kitti_tiny/'
# train, val, test dataset에 대한 type, data_root, ann_file, img_prefix 환경 파라미터 수정.
cfg.data.train.type = 'KittyTinyDataset'
cfg.data.train.data_root = './kitti_tiny/'
cfg.data.train.ann_file = 'train.txt'
cfg.data.train.img_prefix = 'training/image_2'
cfg.data.val.type = 'KittyTinyDataset'
cfg.data.val.data_root = './kitti_tiny/'
cfg.data.val.ann_file = 'val.txt'
cfg.data.val.img_prefix = 'training/image_2'
cfg.data.test.type = 'KittyTinyDataset'
cfg.data.test.data_root = './kitti_tiny/'
cfg.data.test.ann_file = 'val.txt'
cfg.data.test.img_prefix = 'training/image_2'
# class의 갯수 수정.
cfg.model.roi_head.bbox_head.num_classes = 4
# pretrained 모델
cfg.load_from = './mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 학습 weight 파일로 로그를 저장하기 위한 디렉토리 설정.
cfg.work_dir = './mmdetection/tutorial_exps'
# 학습율 변경 환경 파라미터 설정.
cfg.optimizer.lr = 0.02 / 8
cfg.lr_config.warmup = None
cfg.log_config.interval = 10
# config 수행 시마다 policy값이 없어지는 bug로 인하여 설정.
cfg.lr_config.policy = 'step'
# Change the evaluation metric since we use customized dataset.
cfg.evaluation.metric = 'mAP'
# We can set the evaluation interval to reduce the evaluation times
cfg.evaluation.interval = 12
# We can set the checkpoint saving interval to reduce the storage cost
cfg.checkpoint_config.interval = 12
# Set seed thus the results are more reproducible
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
#cfg.gpu_ids = 1
# We can initialize the logger for training and have a look
# at the final config used for training
print(f'Config:\n{cfg.pretty_text}')
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.apis import train_detector
# train용 Dataset 생성.
datasets = [build_dataset(cfg.data.train)]
model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
model.CLASSES = datasets[0].CLASSES
#-----------------train code -----------------------------
#mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
#%cd mmdetection
# epochs는 config의 runner 파라미터로 지정됨. 기본 12회
cfg.lr_config.policy = 'step'
train_detector(model, datasets, cfg, distributed=False, validate=True)
말씀해주신대로 config 상에 문제가 있는지 확인해보고 있습니다.
colab에서 정상동작한 경우의 cfg 값과
local에서 돌리는 cfg 값의 차이가 있음을 확인했습니다.
확인된 내용은 아래와 같습니다.
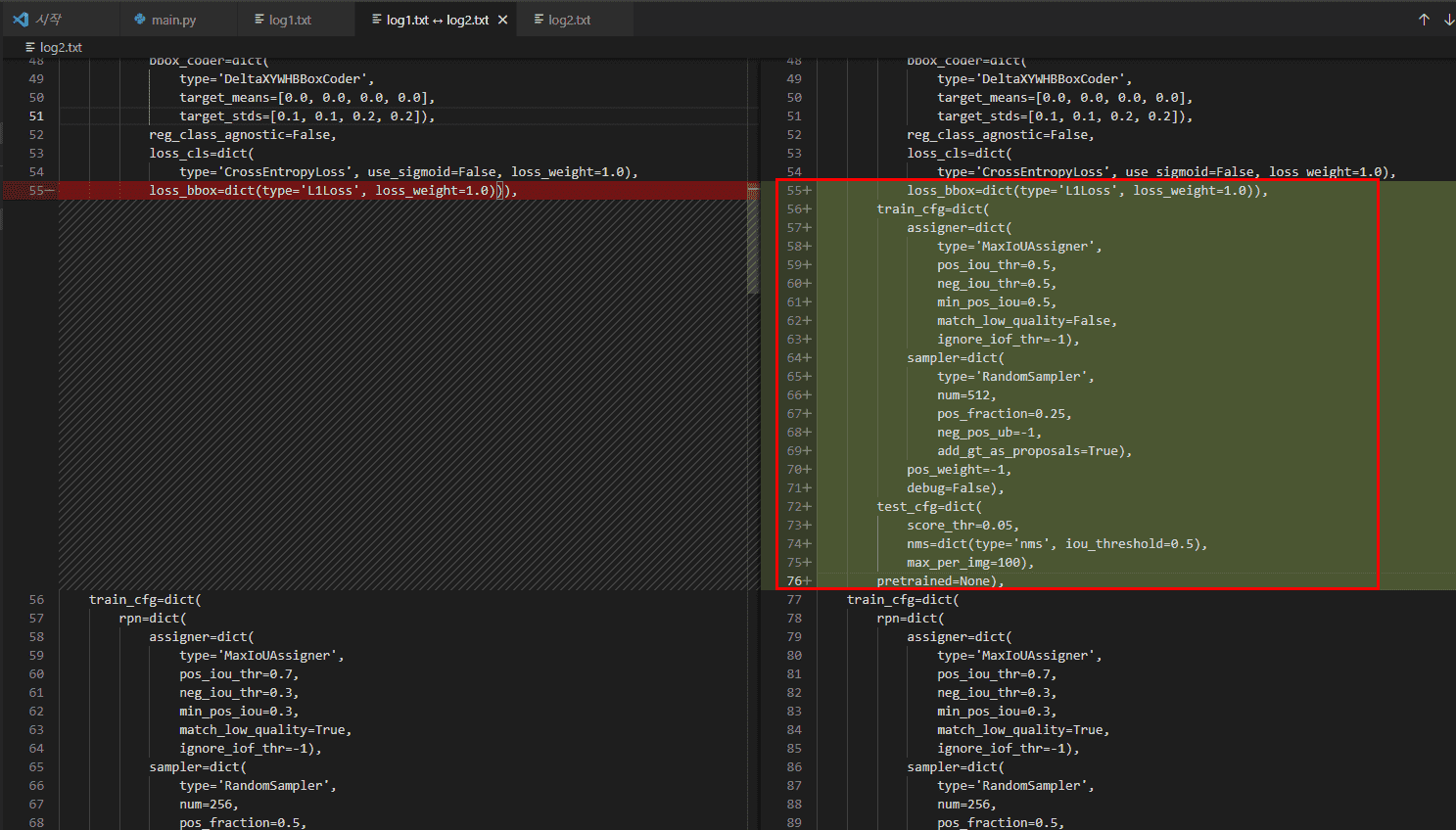
다른 내용은 경로상의 차이정도만 있었고 위 차이는 왜 발생하는지 모르겠습니다.
주신 코드를 거의 그대로 돌렸는데 해당부분만 추가로 들어가 있습니다.
혹시 위 내용이 문제가 될까요?
감사합니다!
0
권 철민
지식공유자2021.08.04
안녕하십니까,
해당 오류로는local setting이 잘못된 건지, 아님 로컬 세팅으로 이전한 코드나 config가 잘못되었는지 확인하기 어렵군요
로컬 세팅 하는 방법은 https://github.com/open-mmlab/mmdetection/blob/master/docs/get_started.md
를 참조하셔서 다시 세팅 시도 부탁드립니다.
작성하신 코드중 datasets 만드는 코드랑 config 설정 코드를 여기에 올려주십시요.
그리고 아래와 datasets[0]의 출력 값도 확인 부탁드립니다
datasets[0].data_infos
datasets[0].img_prefix, datasets[0].data_root, datasets[0].ann_file
제가 지금 GPU 환경이 없습니다. 로컬 세팅하기에는 시간이 너무 걸립니다. 일단은 colab 환경에서 수업을 진행해 주십시요.
그리고 다시 한번 dataset 설정 코드와 config 코드가 local 이행 과정에서 문제가 없는지 확인해 주십시요.
그래도 여전히 문제가 생기면, 제가 지금 휴가 중이라, 다음주 중에 로컬 세팅을 해보겠습니다.

답변 7