
-
질문 & 답변
카테고리
-
세부 분야
데브옵스 · 인프라
-
해결 여부
해결됨
안녕하세요! 강의 4.3중에 질문이 있습니다.
21.06.03 01:14 작성 조회수 313
4
안녕하세요!
저같은 경우에는 master node의 컨테이너 런타임을 stop해도 worker node의 nginx에
curl 진행시 정상적으로 응답을 보여주는데요.
혹시 쿠버네티스가 cache를 참고해서 이전에 접속을 시도했던 내용에 대해서는 정상적으로 보여지는 기능이 있나요??
제가 컨테이너 런타임을 stop하기전에 한번이라도 접속했던 nginx에 대해서는 응답이 보이는데
한번도 접속하지 않은 nginx 컨테이너에 대해서는 강의처럼 접속이 안되어서요.
저의 추측이 맞다면 cache 사용 유무와 사용에 대한 설정 및 cache 내용 저장 위치에 대해 궁금합니다!

답변을 작성해보세요.
1

조훈(Hoon Jo)
지식공유자2021.06.03
강의에서는 이정도까지는 안 들어가지만...(로 깔면 혼나려나..)
문제가 되는 상황에서도 (마스터 노드에 docker 굿바이) 각 워커노드에서 curl로 넣으시면 통신이 됩니다.
[root@w1-k8s ~]# curl 172.16.221.134
request_method : GET | ip_dest: 172.16.221.134
지정노드의 ip route를 보면 아래와 같고 이것이 통신이 된다는 얘기는 내부 통신에는 iptable로 netfilter 되지 않기 때문일 것입니다.
[root@w1-k8s ~]# ip route
default via 10.0.2.2 dev eth0 proto dhcp metric 100
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 100
172.16.103.128/26 via 192.168.1.102 dev tunl0 proto bird onlink
172.16.132.0/26 via 192.168.1.103 dev tunl0 proto bird onlink
blackhole 172.16.221.128/26 proto bird
172.16.221.131 dev cali36bdab2d6e2 scope link
172.16.221.132 dev cali1902c1d06cc scope link
172.16.221.133 dev cali3f23f1b953f scope link
172.16.221.134 dev cali0b3ab0d95c5 scope link
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.101 metric 101
그래서 노드들의 로그를 살펴봤더니...
[ From 마스터 노드]
[root@m-k8s ~]# tail /var/log/calico/cni/cni.log
<snipped>
2021-06-03 09:58:44.857 [INFO][29507] ipam.go 1325: Releasing all IPs with handle 'kube-system.calico-kube-controllers-744cfdf676-d2p76'
2021-06-03 09:58:44.863 [INFO][29491] k8s.go 571: Teardown processing complete. ContainerID="db9e52ba0e2e37fcb4e652694cf6b351b14ff83a051cc45500d9f2d430db83bc"
[ From 워커 노드]
[root@w1-k8s ~]# tail /var/log/calico/cni/cni.log
<snipped>
2021-06-03 09:54:08.014 [INFO][14005] k8s.go 474: Wrote updated endpoint to datastore ContainerID="3b1be8a49de9708e507a3df75be349b40d371715198bc12ba0084b07f62e2320" Namespace="default" Pod="chk-ip-9d8d7b778-tgv6x" WorkloadEndpoint="w1--k8s-k8s-chk--ip--9d8d7b778--tgv6x-eth0"
[root@w2-k8s ~]# tail /var/log/calico/cni/cni.log
<snipped>
2021-06-03 09:54:04.831 [INFO][11137] k8s.go 474: Wrote updated endpoint to datastore ContainerID="ac2355ba42a65da1340a800ee291da4ed8e25ab02ecbdf368917f34664cd6164" Namespace="default" Pod="chk-ip-9d8d7b778-7x628" WorkloadEndpoint="w2--k8s-k8s-chk--ip--9d8d7b778--7x628-eth0"
[root@w3-k8s ~]# tail /var/log/calico/cni/cni.log
<snipped>
2021-06-03 09:54:04.772 [INFO][7193] k8s.go 474: Wrote updated endpoint to datastore ContainerID="2050d38e74053ed9c944bc95e4df7f3647fc1edb4bb8219701e3330f911077e2" Namespace="default" Pod="chk-ip-9d8d7b778-pt99g" WorkloadEndpoint="w3--k8s-k8s-chk--ip--9d8d7b778--pt99g-eth0"
현재 시간 아래와 같은데 말이죠..
[root@w3-k8s ~]# date
Thu Jun 3 11:17:42 KST 2021
그래서 결론적으로 calico 의 업데이트가 정상적으로 이루어지지 않아 통신이 안된다로 보는 것이 제일 무난할 것 같습니다. 그리고 calico controller에 이슈가 생겨도 calico daemonset을 일정 시간동안 동작한다고 봐도 무방할 것 같습니다. 다만 업데이트를 받지 못하면 forwarding 하지 못하도록 설계된 것으로 보여지는데 이는 설계적인 관점이라 현재 크게 중요하진 않을 것 같습니다.
감사합니다.
조훈 드림.
0

wjddudgh01
질문자2021.06.03
오우.. 상세한 답변 잘읽어보았습니다. 아직 제가 초급단계라 처음보는 부분들도 있어서
100% 이해하지는 못했지만 어떠한 흐름에 의해 일어나는 현상인지는 답변해주신 덕분에
알수있게 되었습니다. 전체적으로 좀더 보고 다시 돌아와서 답변을 읽어보면
확실히 이해할 수 있을거같습니다. 감사합니다:)
wjddudgh01
질문자2021.06.04
말씀주신 내용을 간략하게 제가 이해한대로 요약하자면
1. master 노드에서 컨테이너 런타임을 stop했을 때 이전에 접속한 내용에 대해서 curl을 해도
결과가 정상적으로 나오는 이유는 첫째적으로 런타임stop을 하더라도 라우팅 정보가 남아있기에 통신 경로상은 문제가 없다.
2. 경로는 확인했으니 cache와의 관련을 확인하기 위해 kube-proxy 영역을 보았고 calico 관련 내용을 확인. calico는 cni 와 관련이 있으며 cni에 대한 정보, 경로확인 중 cni cache 관련 내용 확인, /var/log/에서 해당 로그 확인가능
3. CNI Cache관련 각 노드들의 로그의 시간을 살펴본 결과, master node의 컨테이너 런타임 stop 에 대해서 calico의 정보가 바로 업데이트가 되지 않게되는 경우, calico daemon이 컨타이너 런타임 stop 이전의 내용에 대해 일정시간동안 기존의 정상 응답에 대한 내용을 동작한다고 볼 수 있다.
[추가]master 컨테이너 런타임을 stop했을 때 master node에서는 curl이 안되더라도
worker노드에서는 접속이 가능하다 => 그 이유는 내부통신은 iptables로 netfilter하지 않기때문이다.
라고 이해했습니다..ㅎㅎ 정확하게 이해한건지는 모르겠습니다.
조훈(Hoon Jo)
지식공유자2021.06.04
일단 위의 내용을 이해하려면 L2, L3 그리고 overlay 네트워크에 대한 기본적인 이해가 필요합니다. 그리고 이 내용도 알고 있으면 이해에 참고가 됩니다.
https://www.slideshare.net/InfraEngineer/ss-186475759
https://ikcoo.tistory.com/164?category=416817
1. master 노드에서 컨테이너 런타임을 stop했을 때 이전에 접속한 내용에 대해서 curl을 해도
결과가 정상적으로 나오는 이유는 첫째적으로 런타임stop을 하더라도 라우팅 정보가 남아있기에 통신 경로상은 문제가 없다.
> 아닙니다. 컨테이너 런타임과 라우팅 정보는 관계가 없습니다. (정확히 말하자면 도커에서 overlay 제공하는 docker0는 관계가 있긴 합니다만....tul0 interface랑요)
> 라우팅 정보를 본 것은 경로를 보려고 한 것이고, 테스트 procedure를 curl로 선택했을 뿐입니다.
2. 경로는 확인했으니 cache와의 관련을 확인하기 위해 kube-proxy 영역을 보았고 calico 관련 내용을 확인. calico는 cni 와 관련이 있으며 cni에 대한 정보, 경로확인 중 cni cache 관련 내용 확인, /var/log/에서 해당 로그 확인가능
> 캐시를 확인하려고 한게 아니라..kube-proxy가 iptable 또는 ipvs를 기반으로 동작하기 때문에 본겁니다. calico는 cni와 관련이 아니라 calico < cni 입니다. (cni 중에 하나가 calico입니다. 아마 강의때 설명을..)
> cni cache를 그리고 확인했고 관계성이 조금 떨어지는거 같은데 구현체를 직접 본게 아니라서 불확실하다고 적었습니다. 네 로그 확인은 맞고요.
3. CNI Cache관련 각 노드들의 로그의 시간을 살펴본 결과, master node의 컨테이너 런타임 stop 에 대해서 calico의 정보가 바로 업데이트가 되지 않게되는 경우, calico daemon이 컨타이너 런타임 stop 이전의 내용에 대해 일정시간동안 기존의 정상 응답에 대한 내용을 동작한다고 볼 수 있다.
> 바로 업데이트는 아니고 주기적인 업데이트일꺼고 (metallb vs porter 영상 참고요) calico의 정보가 아니라 calico ctrl와 calico daemonset 입니다.
> 뒤에 내용은 어떤걸 쓰신건지 모르겠네요..
> 제가 쓴건 cni에 관련한 로그 업데이트가 멈췄다고 쓴건데요..
만약 이 부분을 모두 이해하기를 원하신다면 네트워크쪽 공부가 필요할 것 같습니다.
단순하게는 calico ctrl가 (마스터 노드에 있음) docker가 멈춰서 동작하지 못하였고 calico 전체적으로 영향을 받아서 일정 시간 이후에 동작(보통 Forwarding이라고 표현하기도 함)을 멈춘것으로 보인다. 정도입니다. 일정 시간은 calico에서 따로 캐시를 interface에 할당해서 사용해서 그러는 것인지는 내부 매카니즘에 따라서 다릅니다.
참고로 멈추는 구간은 다음과 같습니다.
보내는 곳

마스터 노드 tcpdump -i tunl0
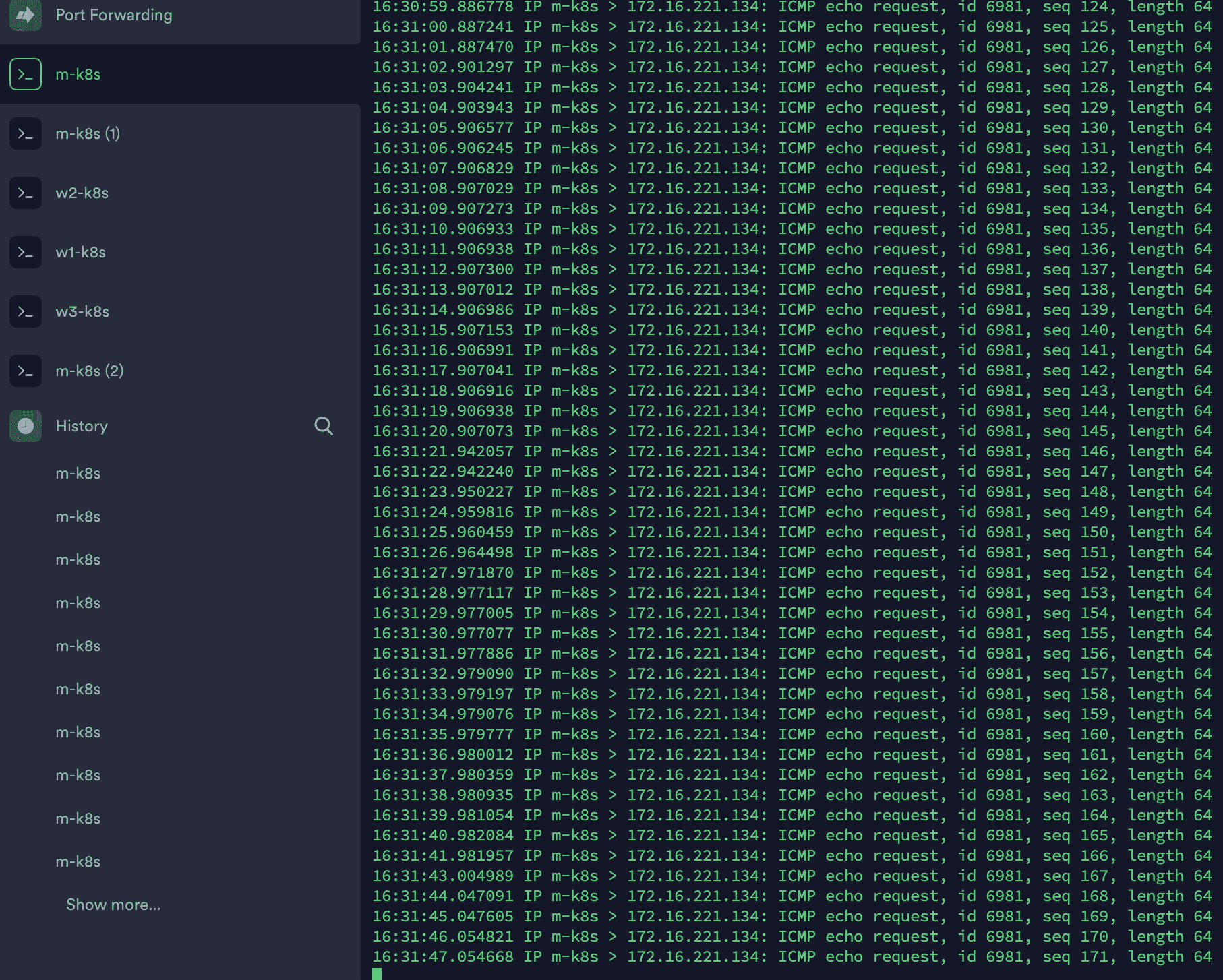
워커 노드 1번의 route -n 과 위쪽은 tunl0 아래쪽은 cali 입니다.
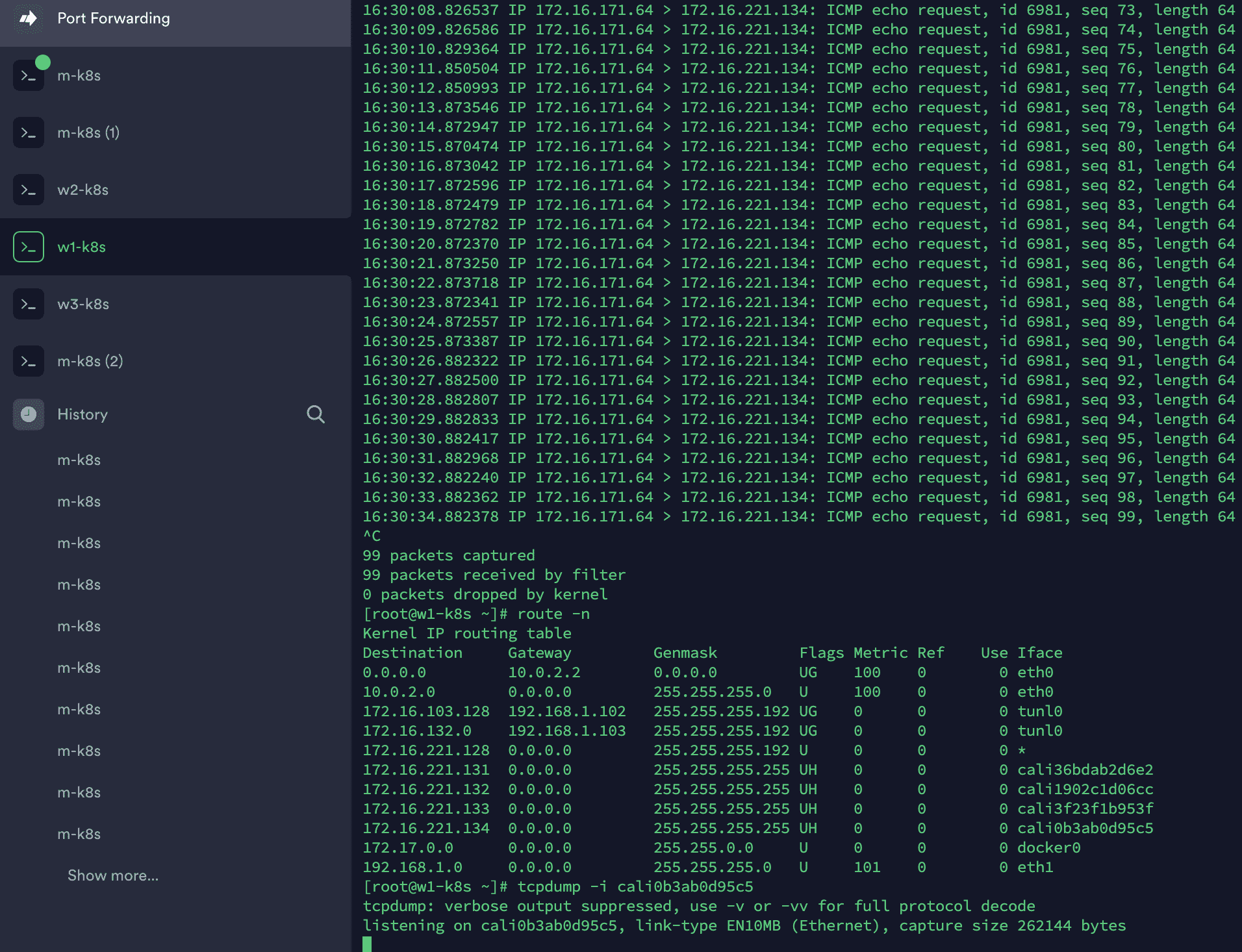
즉 cali interface in/out에서 icmp echo reply가 되지 않는 상태이며, 좀 더 자세하게는 파드 레벨에서 더 해봐야겠지만, 현재 목적에 맞지 않아서 여기까지 한 상태입니다.
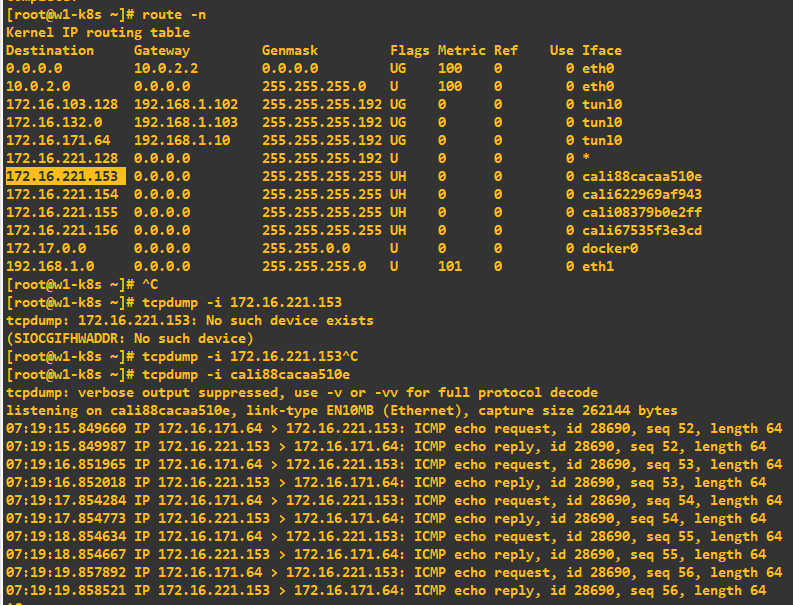
0
0
조훈(Hoon Jo)
지식공유자2021.06.03
안녕하세요
테스트를 좀 해 봤는데 아래와 같은 추정 결론에 도달하였습니다. (추정이라고 하는 이유는 정확하게 알기 위해서는 CNI를 교체하고 Calico의 cache 메카니즘도 함께 봐야 하기 때문입니다.)
근데 바로 끝을 보셔도 될꺼 같긴 합니다...
(네트워크 Deep-Dive 과정에서 다뤄줄수 있는지 부탁도 드려보겠습니다.)
질문: 혹시 쿠버네티스가 cache를 참고해서 이전에 접속을 시도했던 내용에 대해서는 정상적으로 보여지는 기능이 있나요?? 저의 추측이 맞다면 cache 사용 유무와 사용에 대한 설정 및 cache 내용 저장 위치에 대해 궁금합니다!
분석:
- 네 그래서 확인을 좀 해 봤는데 도커가 종료된 상태임에도기존에 접속한 pod에서 정상적으로 응답을 가져오는 것을 확인하였습니다.
- 일단 DNS는 Cache하지만 일반적으로 IP자체는 캐시하지 않습니다. 정확히 말하면 다음과 같이 IP table을 캐시하긴 합니다.
[root@m-k8s ~]# ip route get 172.16.103.160
172.16.103.160 via 192.168.1.102 dev tunl0 src 172.16.171.64
cache
[root@m-k8s ~]# ip route get 172.16.103.161
172.16.103.161 via 192.168.1.102 dev tunl0 src 172.16.171.64
cache
그리고 이와 같이 ip route 자체에도 기록이 되어 있습니다.
[root@m-k8s ~]# ip route
default via 10.0.2.2 dev eth0 proto dhcp metric 100
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 100
172.16.103.128/26 via 192.168.1.102 dev tunl0 proto bird onlink
172.16.132.0/26 via 192.168.1.103 dev tunl0 proto bird onlink
blackhole 172.16.171.64/26 proto bird
172.16.221.128/26 via 192.168.1.101 dev tunl0 proto bird onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.10 metric 101
하지만 이 역시도 경로에 대한 정보를 제공하는 부분입니다.
따라서 캐시와 연관을 위해서 kube-proxy 영역을 살펴봅니다.
[root@m-k8s ~]# iptables -t raw -nvL
Chain PREROUTING (policy ACCEPT 12M packets, 2211M bytes)
pkts bytes target prot opt in out source destination
12M 2211M cali-PREROUTING all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:6gwbT8clXdHdC1b1 */
Chain OUTPUT (policy ACCEPT 12M packets, 2562M bytes)
pkts bytes target prot opt in out source destination
12M 2562M cali-OUTPUT all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:tVnHkvAo15HuiPy0 */
Chain cali-OUTPUT (1 references)
pkts bytes target prot opt in out source destination
12M 2562M MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:njdnLwYeGqBJyMxW */ MARK and 0xfff0ffff
12M 2562M cali-to-host-endpoint all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:rz86uTUcEZAfFsh7 */
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:pN0F5zD0b8yf9W1Z */ mark match 0x10000/0x10000
Chain cali-PREROUTING (1 references)
pkts bytes target prot opt in out source destination
12M 2211M MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:XFX5xbM8B9qR10JG */ MARK and 0xfff0ffff
227K 17M MARK all -- cali+ * 0.0.0.0/0 0.0.0.0/0 /* cali:EWMPb0zVROM-woQp */ MARK or 0x40000
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:V6ooGP15glg7wm91 */ mark match 0x40000/0x40000 rpfilter invert
11M 2193M cali-from-host-endpoint all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:RMTzKqp0j735XfY4 */ mark match 0x0/0x40000
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:T8-Zfumo2dKygI73 */ mark match 0x10000/0x10000
Chain cali-from-host-endpoint (1 references)
pkts bytes target prot opt in out source destination
Chain cali-to-host-endpoint (1 references)
pkts bytes target prot opt in out source destination
이 내용을 살펴보면 대부분이 cali(칼리코 약자)와 연관되어 있음을 알 수 있습니다.
그래서 CNI쪽을 살펴 보면 다음과 같이 CNI cache의 영역이 있기는 한 것을 알 수 있습니다.
(이 부분은 실행 시점에 따라 결과가 다를 수 있습니다.)
[root@m-k8s ~]# ls /var/lib/cni/cache/results/
cni-loopback-61aa3d39e74aa8b218dc7b3612d52c5d151125c4be1c2caf7c920be03565273f-eth0 k8s-pod-network-61aa3d39e74aa8b218dc7b3612d52c5d151125c4be1c2caf7c920be03565273f-eth0
cni-loopback-864e9236e5936f1f092d08838480018882931e2ecf9f24683205865631aa7ea6-eth0 k8s-pod-network-864e9236e5936f1f092d08838480018882931e2ecf9f24683205865631aa7ea6-eth0
cni-loopback-9c71a662421a1b2f4bb943b0e8d6b88175fb6abf2b08240ab2e849b28a2ee17e-eth0 k8s-pod-network-9c71a662421a1b2f4bb943b0e8d6b88175fb6abf2b08240ab2e849b28a2ee17e-eth0
하지만 이 영역이 문제가 생겨도(rm -rf로 디렉터리를 지워봄) 캐시에 가깝게 동작하는 것이 확인되었습니다. (근데 지우는거 추천하지 않습니다.)
그래서 cni log(/var/log/calico/cni/cni.log)쪽을 봤는데 이러한 세세한 내용은 기록되지 않습니다. 하지만 calico-kubec-controller에서 EndPoint 업데이트가 더이상 이루어지지 않으면 각 노드에 있는 calico 데몬셋이 정상동작하지 못할 것으로 예상됩니다.
2021-06-03 08:15:31.484 [INFO][5874] k8s.go 474: Wrote updated endpoint to datastore ContainerID="09d4c993946260bec85a3457c5a8f28ffd8b80c2e248985e8792e10ff8b5d29c" Namespace="kube-system" Pod="calico-kube-controllers-57c5b6487c-qjmhp" WorkloadEndpoint="m--k8s-k8s-calico--kube--controllers--57c5b6487c--qjmhp-eth0"
결론: CNI의 캐시 또는 calico 데몬셋이 비정상 상태로 빠지기 전까지 일정 시간 동안은 IP통신이 가능한 것으로 추정됩니다.
네트워크 쪽에서는 cache는 매우 빈번하게 사용되는 기능입니다. 일반적으로 캐시의 사용유무는 조정하지 않습니다. (캐시 용량을 QoS 관점에서 조정하기는 하지만요). 그래서 Caclico의 문서를 좀 봤는데 cache 조정은 나와 있지 않습니다. 그리고 저장 위치는 저기로 추정되나, 저건 기록을 위한 Manifest에 가깝고...실 저장 위치는 알 수 없습니다. 그리고 캐시는 일반적으로 빠른 속도가 필요하기 때문에 프로세서로 띄우고 빠르게 엑세스할 수 있는 임시성(어짜피 휘발성이라) 메모리 공간을 할당해서 씁니다.
wjddudgh01
질문자2021.06.03
안녕하세요:)
답변중에 아래의 내용이 어떤 의미로 하신말씀인지 알 수 있을까요??
(네트워크 Deep-Dive 과정에서 다뤄줄수 있는지 부탁도 드려보겠습니다.)
조훈(Hoon Jo)
지식공유자2021.06.04
향후에 예정되어 있는 강의들이 있는데, 거기에 포함이 가능할지 부탁드려 보겠다는 의미입니다. 제가 모두 다 진행하는건 아니라서요 디렉팅만 할 예정입니다. 제가 하는 것도 있고요..
이 질문에 대한 답변을 참고하시면 좋을꺼 같습니다.
https://www.inflearn.com/questions/172272

답변 4