
-
질문 & 답변
카테고리
-
세부 분야
데이터 엔지니어링
-
해결 여부
미해결
파이프라인강의에서 크롤링이안됩니다ㅠ.ㅠ
21.04.25 08:14 작성 조회수 156
0
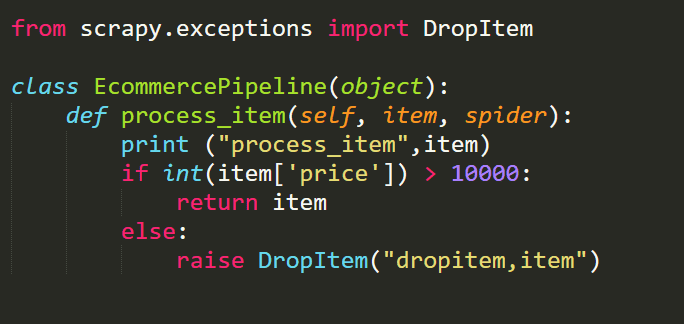
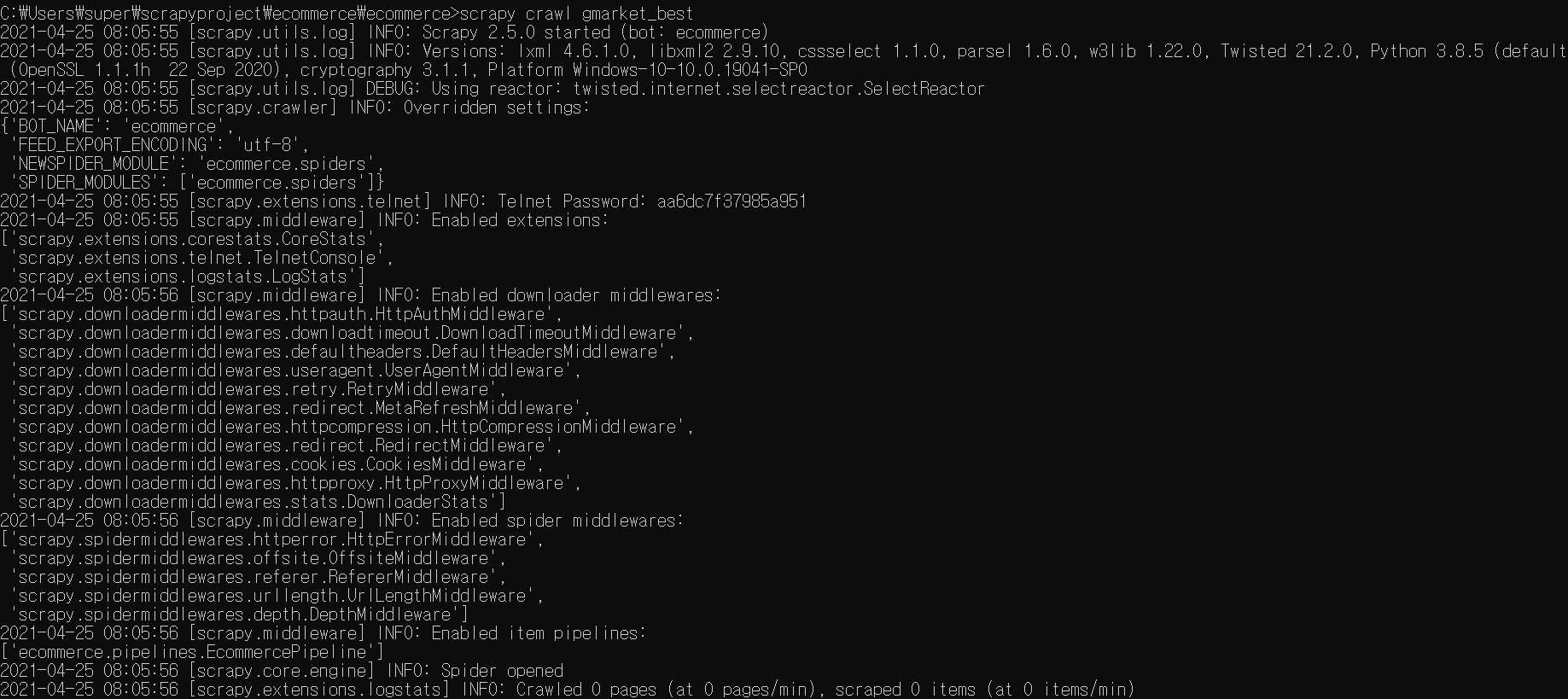
파이프라인 사용법익히기2에서 강사님 코드랑 분명히 똑같이 적었음에도 저렇게 오류가 나면서 크롤링이 실행이안됩니다
왜 안되는걸까요?ㅠㅠ셋팅도 다 수정하였습니다
아래 이미지는 다운받으셔서 보셔야될것같습니다ㅠㅠ 그냥올리니까 글씨가 잘안보이네요
그리고 처음에 파이프라인 통과하는지 확인하는 코드에서도
class EcommercePipline(object): def process_item(self,item,spider): print("process_item",item) return item


답변을 작성해보세요.
0

잔재미코딩 DaveLee
지식공유자2021.04.25
안녕하세요. 사실 이미지를 보며 에러메세지를 보니, 어떤 코드를 실행하신 것인지, 어떤 에러인지는 알기가 어렵네요. 왠지 첫번째 이미지는 에러가 없는 것도 같은데, 그렇다고 웹페이지가 크롤링은 안된 것 같고요. 뭔가 크롤링하는 주소 자체가 잘못된 것도 같고요. 워낙 프로젝트로 실행이 되다보니, 로그 메세지만 보고는 어떤 부분이 의심이 될지 알기가 어렵네요.
또 gmarket_best.py 는 다음과 같은 코드로 확인이 되는데요. 제가 영상에서 제공해드린 코드들이 동작이 안되는 것인지, 또는 위에 언급하신대로, price > 10000 등이 들어있는 자신의 수정한 코드가 안되는 것인지 잘 모르겠습니다. 우선은 모든 관련 폴더를 지우신 후에, crawl gmarket_best 를 하신것이라면, 제가 드린 해당 프로젝트를 그대로 다운로드 받아서, 테스트를 해보시면 좋을 것 같습니다. 그런 다음 해당 코드가 정상 동작하면, 그 때 비로소 개인별 코드를 매우 조금씩 수정 후 테스트를 해보시면 좋을 것 같습니다.
감사합니다.
--------
# -*- coding: utf-8 -*-
import scrapy
from ecommerce.items import EcommerceItem
class GmarketBestSpider(scrapy.Spider):
name = 'gmarket_best'
start_urls = ['http://corners.gmarket.co.kr/Bestsellers/']
def parse(self, response):
titles = response.css('div.best-list > ul > li[id] > a::text').getall(
prices = response.css('div.best-list > ul > li[id] > div.item_price >
for num, title in enumerate(titles):
doc = EcommerceItem()
doc['title'] = title
doc['price'] = prices[num].strip().replace("원", "").replace(",",
yield doc

답변 1