
네이버 쇼핑 핫딜 크롤링 문제
412
1 asked
네이버 쇼핑 핫딜 데이터를 크롤링하는 과정에서
강의에서는 핫딜 버튼의 ClassName이 '_productSet_hotdeal'로 되어있어
driver.find_element_by_class_name("_productSet_hotdeal").click() 코드를 사용하여 버튼을 클릭했지만,
현재는 네이버 쇼핑 소스가 변경되어 모든 버튼의 ClassName이 'subFilter_filter__3Y-uy'로 되어있어
driver.find_element_by_css_selector("#__next > div > div.container > div.style_inner__18zZX > div.style_content_wrap__1PzEo > div.style_content__2T20F > div.seller_filter_area > ul > li:nth-child(5) > button").click() 코드를 사용하여 버튼을 클릭하였습니다.
문제는, 버튼 클릭까지는 문제 없이 진행 되었지만
핫딜 페이지의 데이터를 출력하는 과정에서
핫딜 데이터를 출력하는 것이 아닌 기존의 데이터를 출력합니다.
어떻게 해결해야 될까요?
- app.py
from flask import Flask, render_template, request
app = Flask(__name__)
# crawling module import
import requests
from bs4 import BeautifulSoup
# excel module import
from openpyxl import Workbook
write_wb = Workbook()
write_ws = write_wb.active
# 셀리니움 사용 전 크롬 웹드라이버 설치
# Web automation module import
from selenium import webdriver
@app.route("/")
def hello_world():
return render_template("index.html")
@app.route("/result", methods=["POST"])
def result():
keyword = request.form['input1']
page = request.form['input2']
daum_list = []
# crawling
for i in range(1, int(page) + 1):
req = requests.get("https://search.daum.net/search?nil_suggest=btn&w=news&DA=PGD&cluster=y&q=" + keyword + "&p=" + str(i))
soup = BeautifulSoup(req.text, "html.parser")
for i in soup.find_all("a", class_="f_link_b"):
daum_list.append(i.text)
# excel
for i in range(1, len(daum_list) + 1):
write_ws.cell(i, 1, daum_list[i-1])
write_wb.save("static/result.xlsx")
return render_template("result.html", daum_list = daum_list)
@app.route('/naver_shopping')
def naver_shopping():
driver = webdriver.Chrome('./chromedriver.exe')
driver.implicitly_wait(3)
driver.get("https://search.shopping.naver.com/search/all?query=%EA%B3%B5%EA%B8%B0%EC%B2%AD%EC%A0%95%EA%B8%B0&frm=NVSHATC&prevQuery=%EA%B3%B5%EA%B8%B0%EC%B2%AD%EC%A0%95%EA%B8%B0")
soup = BeautifulSoup(driver.page_source, "html.parser")
for i in soup.select("#__next > div > div.container > div.style_inner__18zZX > div.style_content_wrap__1PzEo > div.style_content__2T20F > ul > div > div > li"):
print(i.find("a", class_="basicList_link__1MaTN").text)
print("---------------------------")
driver.find_element_by_css_selector("#__next > div > div.container > div.style_inner__18zZX > div.style_content_wrap__1PzEo > div.style_content__2T20F > div.seller_filter_area > ul > li:nth-child(5) > button").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.select("#__next > div > div.container > div.style_inner__18zZX > div.style_content_wrap__1PzEo > div.style_content__2T20F > ul > div > div > li"):
# 핫딜 페이지로 정상적으로 이동되어 있지만 기존의 페이지의 데이터를 출력함
print(i.find("a", class_="basicList_link__1MaTN").text)
return render_template("shopping.html")
if __name__ == "__main__":
app.run()- 실행결과
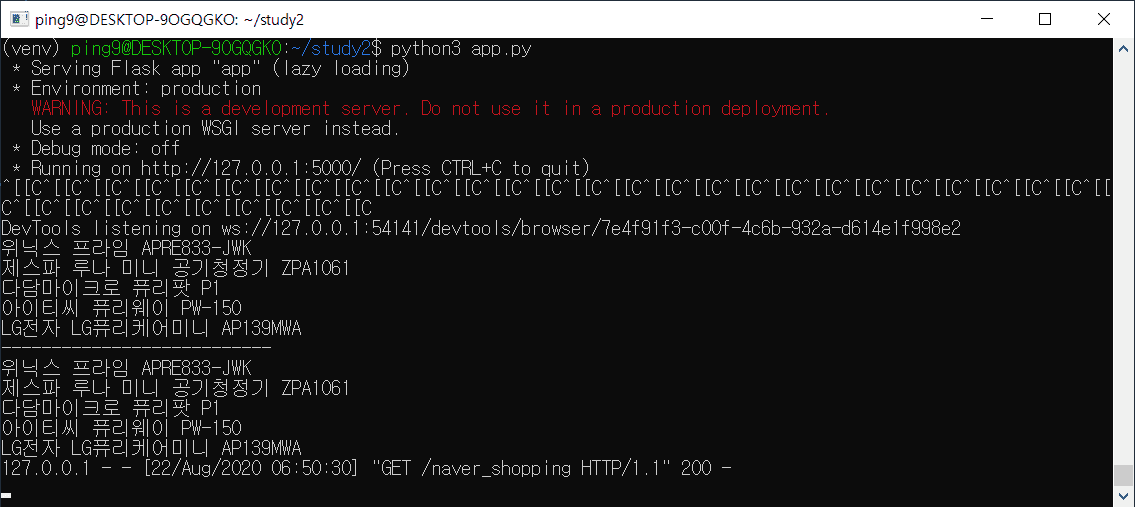
Answer 3
0
앗 얼핏 보기에는 잘 하신 것 같은데
마지막 강의인 "셀레니움 이미지 크롤링, 스크롤 다운" 까지 보시고, 스크롤 다운해도 잘 안되시면 질문 남겨주시면
제가 프로그램 다시 한번 돌려보겠습니다.
수강해주셔서 감사합니다~
교육 자료나 프로그램 소스 위치 알려주세요.
0
172
2
강의 교육자료 변경됨?
0
162
1
[셀레니움 사용해보기]웹 드라이버 경로관련
0
1654
1
[page숫자설정]int(page) 관련문의드립니다.
0
230
1
안녕하세요 강의 정말 잘봤습니다 ㅎㅎ
0
278
1
혹시 외부에서도 웹을 볼 수 있게 작동 하려면 어떻게 해야할까요?
0
258
1
print(soup.select("") 에서 "GET / HTTP/1.1" 500 - 에러 나네요.
0
433
3
엑셀 파일 생성이 안됩니다. ㅠㅠ
0
448
2
소스 올려봅니다
0
321
2
크롤링 관련해서 문의좀 드릴께요~
0
237
1
다른 editor 사용해도 되나요?
0
211
1
flask에서 html 연결이 안됩니다ㅠㅜ
0
519
1
index.html 부분을 인식을 못하네요
0
493
5
저는 네이버 인기 검색어를 가져올려고하는데 못뽑아 오네요 혹시 네이버 보안 문제일까요???
1
213
1
Flask 실행하면 웹사이트 127.0.0.1:5000 포트 부분에서 404에러가 뜨네요 어떻게 해야되나요??
0
6335
6
저는 이렇게 venv부분이 다른 색으로 뜨는데 무슨 차이인가요??
0
412
1
윈도우 PyCharm 환경 설정들 처음부터 알려주세요
0
314
1
실시간
0
300
1
아톰에서 실행
0
344
1
실행결과가 이상합니다 실시간 순위 1위만 뜨네요
0
426
6
코드가 잘안보이는건 wifi환경이라 그런건가요
0
178
1
크롤링 결과를 html 페이지에서 출력할 수 없습니다.
0
292
2
크롤링 결과가 다른 페이지가 아닌 현재 페이지에 나타나게 하려면 어떻게 해야 하나요?
0
337
2
크롤링 오류입니다;
1
434
2