
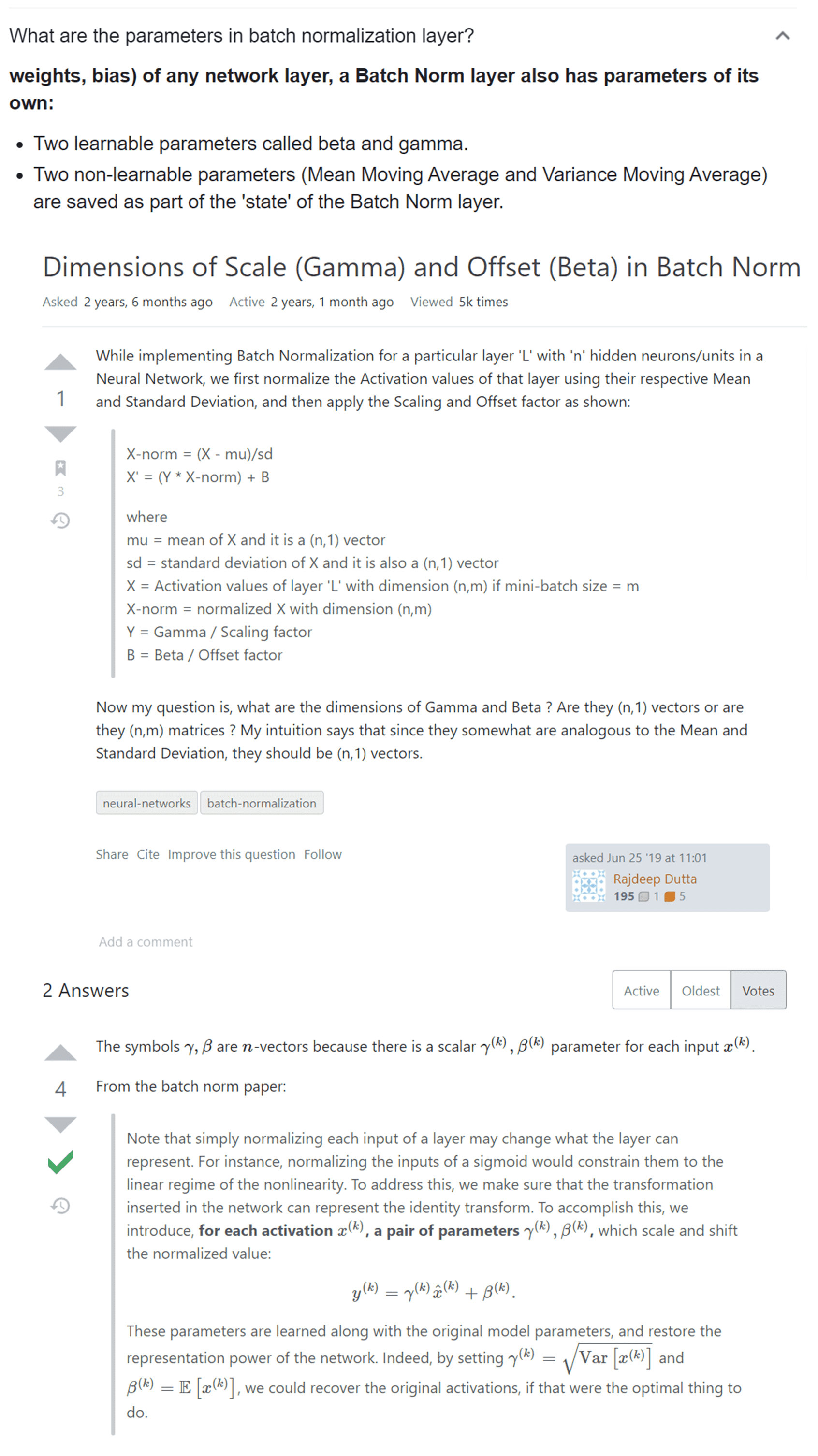
Batch Normalization Layer 의 Training parameter 이해 관련 질문
안녕하세요? 머신러닝 완벽가이드 수강하고 CNN 으로 넘어왔네요~ 요 강의 마치고 컴퓨터 vision 쪽 강의도 수강하려고 미리미리 구매해 놓았습니다. ㅎㅎ 항상 좋은 강의 감사드립니다!
Batch normalization 강의를 듣고 실습을 해 보다가 세 가지 궁금한 점이 생겨서 질문 드립니다. (아래 내용 중에서 제가 잘못이해하고 있는 부분 지적해 주시면 감사드리겠습니다. ^^;;)
아래 그림과 같이 Batch Normalization 을 포함시켜서 Model Creation 했을 때 Model Summary 를 보면 Batch Normalization layer 에도 Training paramter 가 할당되는 것을 볼 수 있는데요,
1) Batch normalization layer 의 training paramter 의 갯수는 어떤 수식(?) 에 의해서 결정되는지.. 궁금합니다. 수식을 알 수 있다면 layer 에 대한 이해를 조금 더 높일 수 있을 듯 해서 질문드리고 있습니다.
2) BN 방법이 Batch 별로 Z = (X - Xbar)/S 수식을 적용해서 얻은 평균이 0이고 표준편차가 1로 scaling 이 된 데이터들을 activation function 에 input 하는 방식인 것으로 이해가 되는데요, 각 node 나 feature point 들 중 신호가 약한 부위를 끄거나 (off), 신호가 분명한 부위를 켜는 (on) 역할을 데이터 평준화를 통해 좀 더 일관성 있게 해 주는 거라고 이해하면 될지요? (강의 중 설명에서는 오히려 noise 개념으로 어려운 학습을 하게 해서 overfit을 줄이는 역할을 한다고 해서.... 사실 일반적인 ML 에서의 표준화 개념과는 상충되는 듯 해서 이해하기 쉽지 않습니다.)
요약 드리면 Batch normalization layer 가 전 후 layer 들에게 영향 주는 물리적인 역할이 무엇인지.. 에 대한 질문입니다. Conv 와 Activation 사이에 위치한다면 Conv layer 에는 영향을 주지 않을 것이고, Activation 을 통과하는 결과에만 영향을 줄 것 같아서요.
3. '표준화' 라는 개념으로 BN layer 를 이해해 보면 왠지... 각 배치별 평균 벡터와 표준편차 벡터값 (혹은 분산-공분산 행렬) 들을 저장해 놓았다가, test data 예측시 활용할 것도 같은데요.. (마치 sklearn 의 preprocessing 모듈의 StandardScaler 클래스의 fit 메소드 처럼)
다만 매 batch 별로 표본 평균 벡터와 표본 분산공분산 행렬이 계속 달라질 것일텐데, batch 가 진행되면서 해당 통계량들을 업데이트 했다가 최종적으로 업데이트 된 통계량을 test data 예측할 때 사용하게 되는 것인지요..? 요 개념이 맞다면 대략 어떤 방식으로 weight 들을 업데이트하며 학습하게 되는지.. 개념적으로라도 이해하고 싶습니다.
다른 weight 들과 마찬가지로 결국 loss 를 줄이는 방향으로 최적화 되는 weight 들인 것인지도 궁금하구요~~ (아니면 BN 의 training parameter 들은 일종의 noise 처럼 임시로 저장은 하지만 예측 시 활용이 안되는 weight 들인 것인지요? )
감사합니다!

Answer 2
2
안녕하십니까,
1. batch normalization의 스케일링 파라미터와 쉬프트 파라미터는 동적으로 딥러닝 모델에서 계산되는데, 이때 weight가 적용됩니다. 정확한 수식은 저도 모릅니다만, 아마도 선형식이 그대로 적용되는 걸로 알고 있습니다. 따라서 위 모델에서는 스케일링 시에 32개의 w와 32개의 bias, 쉬프트 시에 32개의 w와 32개의 bias가 적용되어서 128이 되는 것 같습니다.
2. 각 node 나 feature point 들 중 신호가 약한 부위를 끄거나 (off), 신호가 분명한 부위를 켜는 (on) 역할을 데이터 평준화를 통해 좀 더 일관성 있게 해 주는 거라고 이해하면 될지요?
=> 그것 보다는 초기의 입력 데이터 분포도가 딥러닝 모델 Layer를 통과 시킬 때마다 계속 데이터 분포도가 달라지므로, 이를 어느정도 일관성있는 데이터 분포도를 유지하기 위해서 적용하는 방식으로 이해하시면 좋을 것 같습니다.
그리고
요약 드리면 Batch normalization layer 가 전 후 layer 들에게 영향 주는 물리적인 역할이 무엇인지.. 에 대한 질문입니다. Conv 와 Activation 사이에 위치한다면 Conv layer 에는 영향을 주지 않을 것이고, Activation 을 통과하는 결과에만 영향을 줄 것 같아서요.
=> 질문을 제대로 이해했는지 모르겠지만 당연히 BN을 Conv 다음에 적용하기 때문에 conv에 영향을 미치지 않고, activation을 통과하는 결과에만 영향을 미칩니다. 어쩧든 Layer들을 통과 시마다 입력/출력 데이터의 데이터 분포도가 크게 달라지는 현상을 완화 시켜 줍니다. 원하시는 답변이 아니면 다시 말씀해 주십시요.
3. '표준화' 라는 개념으로 BN layer 를 이해해 보면 왠지... 각 배치별 평균 벡터와 표준편차 벡터값 (혹은 분산-공분산 행렬) 들을 저장해 놓았다가, test data 예측시 활용할 것도 같은데요.. (마치 sklearn 의 preprocessing 모듈의 StandardScaler 클래스의 fit 메소드 처럼)
=> 네 맞습니다. 테스트 데이터에서는 다시 BN을 적용하지 않고, 학습 데이터에서 사용된 BN을 테스트 데이터에 적용합니다.
테스트 시, 즉 Inference 시에는 학습시에 layer별로 만들어진 개별 평균과 표준 편차를 기반으로 지수 가중 이동 평균을 일괄적으로 적용해서 평균과 표준 편차를 구해서 적용하며, 스케일링과 쉬프트 파라미터는 학습시에 최적으로 결정된 값을 이용합니다.
0
많은 질문을 한꺼번에 드렸는데 각 질문별로 상세하고 명확한 답변 감사드립니다. 이해하는데 도움이 많이 되었습니다!
1번 질문 관련해서 추가적으로 규칙성을 찾으려 노력해 보니, BN layer 의 경우 # of training paramter = feature map (직전 conv layer 의 filter 개수) * 4 개 의 수식을 가지는 것도 같습니다. 구글링을 좀더 해보니 gamma (표준편차의 개념), Beta (평균의 기대값 개념) 과 같은 두 개의 learnable paramter 와, 말씀 주신 바와 같은 평균/분산의 이동평균값인 두 개의 non-learnable parapeter 합쳐서 총 4개의 training paramter 로 구성되는 것도 같습니다.
resize 질문
0
60
1
20251212 Kaggle 런타임에 scikit-learn 설치 실패 트러블 슈팅
0
86
1
Loss와 매트릭 관계
0
77
2
Boston 코랩 실습
0
171
2
배치 정규화의 이해와 적용 2 강의 질문
0
144
2
Augmentation원본에 적용해서 데이터 갯수 자체를 늘리는 행위는 의미가있나요?
0
151
2
Conv함수 안에 activation 을 넣지 않는 이유가 뭔지 궁금합니다.
0
213
2
소프트맥스 관련 질문입니다
0
215
1
강의 관련 질문입니다
0
162
2
residual block과 identity block의 차이
0
200
2
옵티마이저와 경사하강법의 차이가 궁금합니다.
1
251
1
실습 환경
0
171
2
입력 이미지 크기
0
256
2
데이터 증강
0
203
2
albumentations ShiftScaleRotate
0
211
1
Model Input Size 관련
0
294
1
마지막에 bird -> frog 말고도 deer -> frog 도 잘못된것 아닌가요??
0
206
1
일반적인 질문 (kaggle notebook사용)
0
276
2
실무에서 Augmentation 적용 시
0
347
2
안녕하세요 교수님
0
235
1
가중치 초기화(Weight Initialization) 질문입니다.
0
332
1
테스트 데이터셋 predict의 'NoneType' object has no attribute 'shape' 오류
0
412
1
학습이 이상하게 됩니다.
2
1041
2
boston import가 안됩니다
0
230
1