
PCA 의 적용 방안 - 전체 feature vs. 일부 feature
강사님, 안녕하세요? 좋은 강의 항상 감사드립니다.
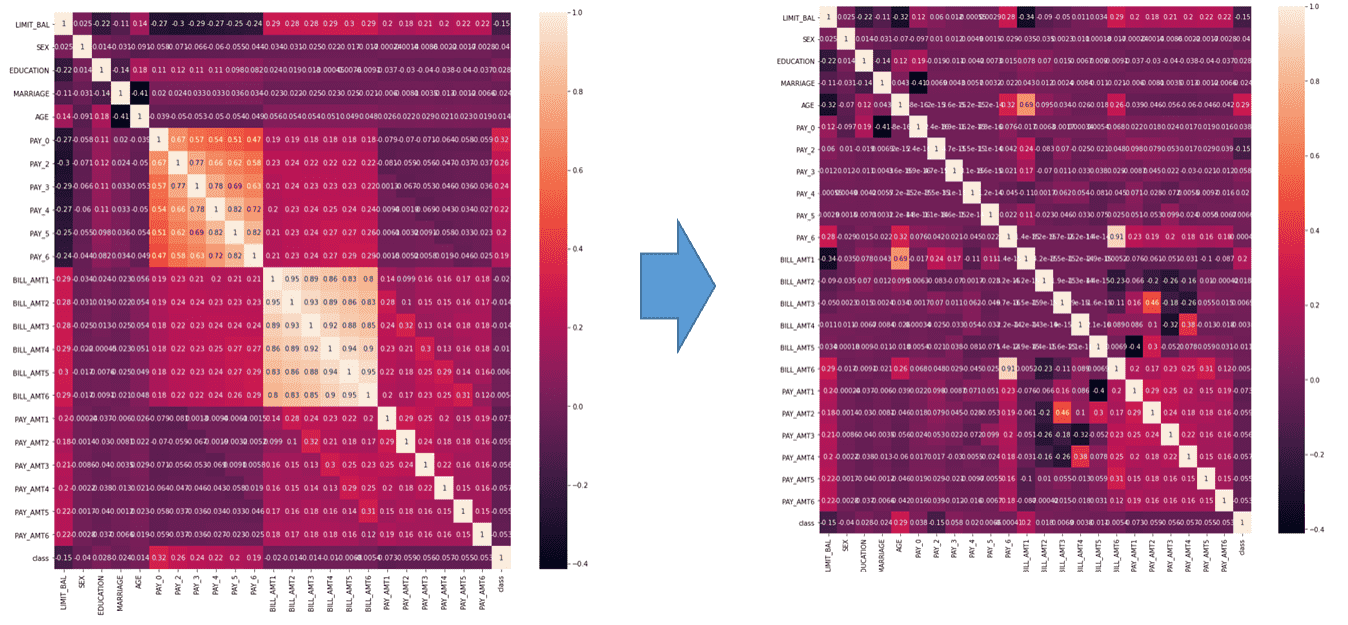
PCA 적용 실습 사례를 보다가 궁금한 점이 있어 질문을 드립니다. 본 단원 신용카드 실습 예제에서 전체 feature 에 대해서 PCA 를 진행하여 차원축소를 시도했을 때 변수를 줄여 효율성을 높이되 모델 성능에서는 약간의 손실이 발생하였는데요,
전체 feature 에 대한 PCA 적용이 아닌, 물리적인 의미에 유사성이 있으면서도 서로 상관도가 높은 feature 들끼리만그룹을 만들어서 feature 그룹 별 PCA 를 진행하는 경우, 변환된 PC score 중 변동성이 높은 상위 feature 일부만 선택하더라도 모델의 예측성능이 향상될 가능성이 있지는 않을지 문의드립니다.
예를 들어 PAY0~PAY6 끼리 묶어서 첫번째 PCA 를 돌리고, BILL_AMT1~BILL_AMT6끼리만 묶어서 두번째 PCA 를 돌려서 전체 데이터셋의 feature 간 다중공선성을 없애는 방식으로 PCA 를 활용하는 방법을 문의드리는 것이구요,
본 예제에서 사용된 신용카드 데이터셋을 가지고 이렇게 변환해서 feature 재정의를 한 경우와 하지 않은 경우에 대한 모델 예측성능을 비교해 보면 train / test set 분류 상황에 따라서 유사하거나 약간 좋아지는 경향도 보이는 것도 같은데... 예제를 가지고 해 본 것이다보니 .. 현업 데이터분석에 활용시 이렇게 접근하는 것이 실제로 의미가 있는 접근 방법일 수 있는 것인지, 혹은 방법론 상 문제는 없을지요..? (전체 feature가 아닌 부분적인 feature 집합에 한정한 PCA 적용 방안)
감사합니다.
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
credit_ds = pd.read_csv('pca_credit_card.csv', header=1) # 1은 연체, 0은 연체 아님
SS_pay = StandardScaler()
SS_bill = StandardScaler()
pca_pay = PCA()
pca_bill = PCA()
SS_pay.fit(credit_ds.iloc[:,5:11])
pay = SS_pay.transform(credit_ds.iloc[:,5:11])
pca_pay.fit(pay)
pay_transformed = pd.DataFrame(pca_pay.transform(pay), columns=['pay_PC1','pay_PC2','pay_PC3','pay_PC4','pay_PC5','pay_PC6'])
credit_ds.iloc[:,5:11] = pay_transformed
SS_bill.fit(credit_ds.iloc[:,11:17])
bill = SS_bill.transform(credit_ds.iloc[:,11:17])
pca_bill.fit(bill)
bill_transformed = pd.DataFrame(pca_bill.transform(bill), columns=['bill_PC1','bill_PC2','bill_PC3','bill_PC4','bill_PC5','bill_PC6'])
credit_ds.iloc[:,11:17] = bill_transformed
credit_ds['class'] = credit_ds['default payment next month']
credit_ds = credit_ds.drop(['ID', 'default payment next month'], axis=1)
plt.figure(figsize=(15,15))
sns.heatmap(credit_ds.corr(), annot = True)
Answer 2
1
안녕하십니까,
좋은 아이디어시군요. 충분히 추진해 볼만한 생각입니다.
근데 제가 비슷한 적용을 과거에 한번 해당 데이터세트에 적용 해본적이 있습니다. 그런데 성능이 개선되지는 않았습니다. 아쿠아라이드 님께서 해당 방법을 적용해 보셨을 때 성능이 약간 개선되었다면 이 역시 좋은 feature engineering 방법입니다.
당시 좀 아이러니 했던것은 기존 feature를 그대로 유지하고, PAY0~PAY6 기반으로 pca를 돌려서 새로운 feature를 하나 만들고 마찬가지로 BILL0~BILL6 기반으로 또 feature를 만들었을 때, 그러니까 기존 feature에 새로운 feature 2개를 추가했을때 약간 성능이 증가하였습니다. 사실 다중 공선성을 염려한다면, 성능이 좋아질 이유는 없었지만, 해당 feature를 제거하고 PCA 변환된 feature를 추가하는 것 보다 이 방식이 약간 성능이 좋았습니다.(기억이 오래되서...)
요약하자만 해당 방식은 2개의 feature를 추가하는 feature engineering 기법이고, 다중 공선성의 영향력을 크지 않았던것 같습니다.
0
답변 감사드립니다. 그리고 경험 공유해 주셔서 감사합니다.
업무 중에 규제없는 선형회귀분석은 많이 사용하고 있었는데 일부 feature 에 PCA 를 적용한 경우 설명율이 유의미한 수준으로 올라가는 경우도 있었고, 어떤 경우에는 동일하거나 오히려 떨어졌던 경우도 있었던 것 같아서.. 왜 케바케 다를까.. 혹은 과연 이렇게 해도 되는 것인가... 하는 의문점을 마음속에 항시 가지고 있었습니다만, 요번 기회에 feature engineering 에 대해 좀 더 명확한 이해를 가질 수 있게 된 듯 합니다. 진심 감사드립니다 :)
말씀 주신 것 처럼 이것저것 많이 시도해 봐야겠네요 ~~ㅎㅎ
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
52
2
안녕하세요 열심히 수강중인 학생입니다
0
90
2
정수 인덱싱
0
86
2
넘파이 오류
0
109
2
11강 numpy의 axis 축 질문 드립니다.
0
107
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
94
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
77
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
83
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
74
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
81
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
76
3
파이썬 다운그레이 후 사이킷런 재설치
0
129
2
좋은 강의 감사합니다.
0
80
2
scoring 함수 음수값
0
72
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
108
2
분류 평가 정확도 예측
0
87
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
114
1
카카오톡 채널 있나요
0
118
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
193
2
pca 스케일링 관련하여 질문드립니다.
0
109
2
주피터 대신 구글 코랩
0
184
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
156
2
실루엣 스코어..
0
91
2