




Java의 실행원리 Deep Dive
Java는 다양한 운영체제에서 동일한 소스코드를 실행할 수 있는 "write once, run anywhere"의 철학을 지닌 프로그래밍 언어입니다. 국내에서 가장 활발히 사용되는 언어이며 제가 현업에서도 주로 사용하는 언어입니다. 이번 포스팅을 통해서 자바가 실행되는 원리에 대해 살펴보겠습니다.
블로그 원본 링크: https://code-run.tistory.com/61
프로그래밍 언어가 특정 운영체제 위에서 실행되기 위해서는 해당 운영체제가 이해할 수 있도록 코드가 작성돼야 합니다. 하지만 자바 개발을 하신 분들은 동일한. java 파일을 맥 OS, 윈도우 또는 Linux에서 실행한 경험이 있으실 겁니다. 정확히는 javac(자바 컴파일러)에 의해 컴파일된 .class 코드가 동일하더라도 해당 코드는 서로 다른 운영체제 위에서 실행될 수 있습니다. 이는 JVM 내부의 interpreter가 운영체제가 이해할 수 있는 코드로 변환해 주기 때문입니다. 즉 java는 운영체제가 이해할 수 있는 코드를 작성하는 책임을 프로그래머로부터 JVM으로 전이한 것으로 볼 수 있습니다.
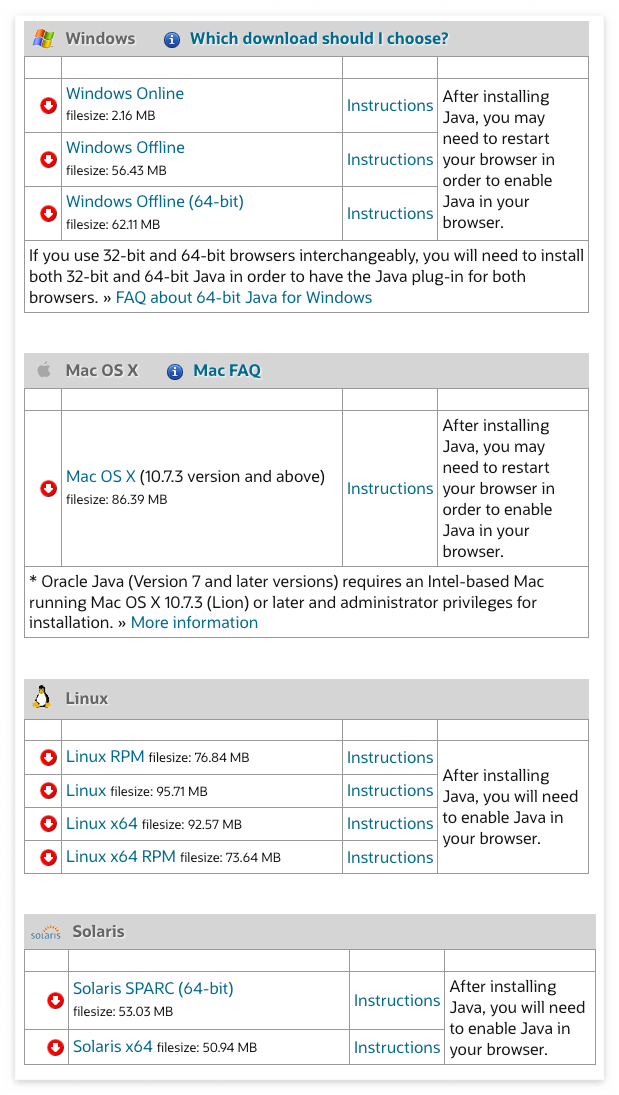 운영체제별로 다운로드 받을 Java가 구분됨
운영체제별로 다운로드 받을 Java가 구분됨
JDK, JRE, JVM
Java 프로그램을 실행하기 위해서는 보통 JDK를 다운로드합니다. JDK와 항상 함께 등장하는 JRE 그리고 위에서 소개한 JVM에 대해 알아보겠습니다.
JVM은 Java의 .class 파일이 실행될 수 있는 환경입니다. .class 파일의 bytecode를 host 운영체제 위에서 실행될 수 있는 환경을 제공합니다.
JRE는 Java Runtime Environment의 약자로 자바 프로그램이 실행될 수 있는 최소환의 환경입니다. JRE는 JVM뿐 아니라 java 프로그램을 실행시키는데 필요한 라이브러리와 소스를 포함합니다.
JDK는 Java Development Kit의 약자로 JRE를 포함합니다. 즉 JDK는 JRE와 JVM을 모두 포함하는 구조입니다. JDK는 javac, debugger 등 개발을 위한 도구를 포함합니다.
 JRE libraries
JRE libraries
 Jdk 설치와 함께 javac 등 설치
Jdk 설치와 함께 javac 등 설치
Java의 실행 원리
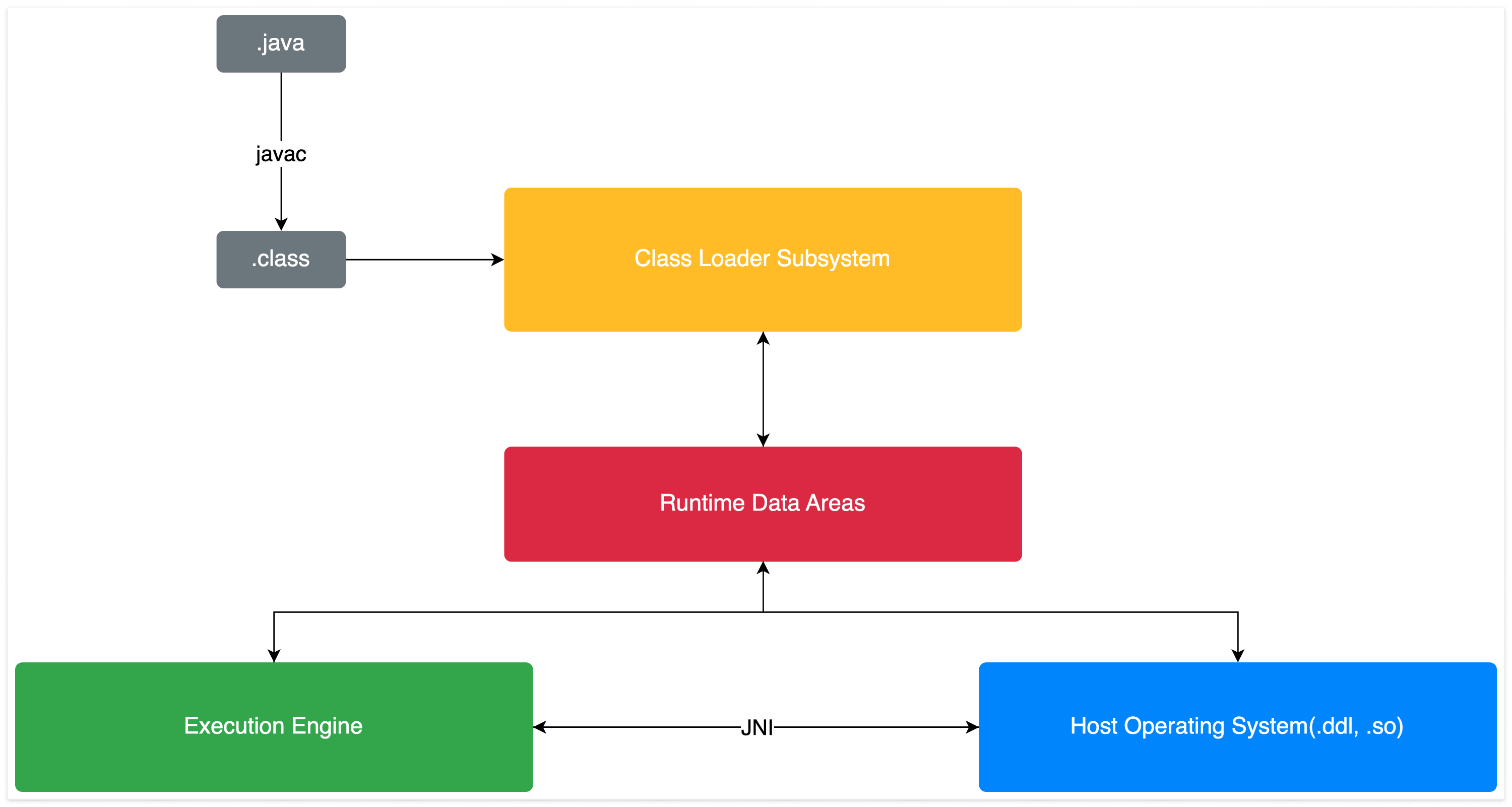 .java 파일의 실행 흐름
.java 파일의 실행 흐름
다음으로는 우리가 작성한 .java 파일이 어떻게 동작하는지 살펴보겠습니다. 우리가 작성한 .java 파일은 javac에 의해 .class 파일로 컴파일됩니다. 컴파일된 .class 파일은 JVM의 class loader에 의해 JVM의 메모리 영역에 로딩됩니다. JVM 메모리에 로딩된 후 execution engine의 interpreter에 의해 코드가 운영체제가 이해할 수 있는 기계어로 변환되고 이는 운영체제의 적절한 함수를 호출하여 필요한 로직을 수행합니다. 그럼 컴파일된 .class 파일이 어떻게 JVM 메모리에 로드되는지 상세히 살펴보겠습니다.
Class Loader Subsystem
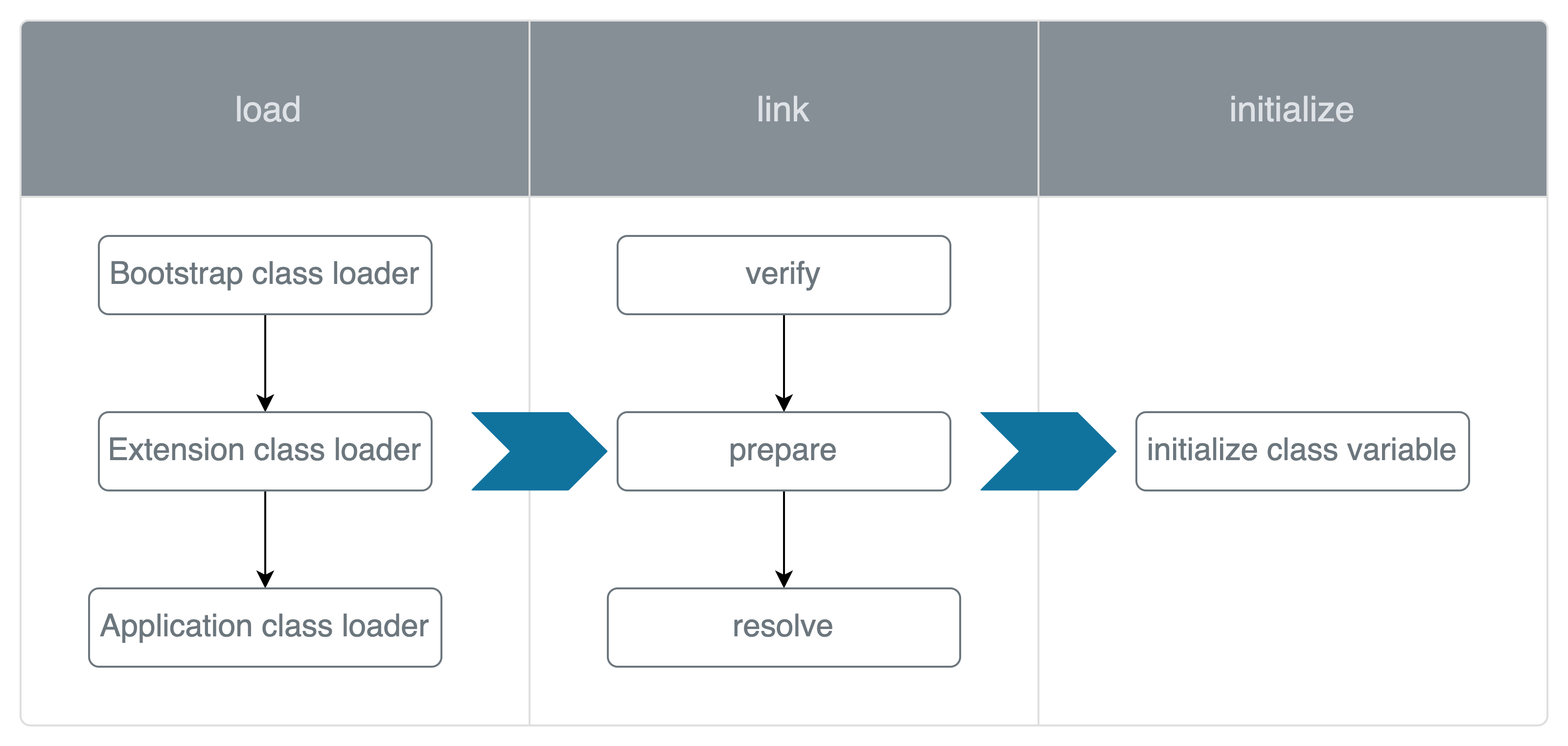
Class loader subsystem의 주목적은 자바 프로그램을 실행시키기 위해 필요한 class를 찾아서 JVM의 메모리에 로드하고 연결(link) 하기 위함입니다. 필요한 class를 로드하고 연결하는 것 이외에 class variable을 초기화하는 역할도 수행합니다.
 Class loader subsystem
Class loader subsystem
Load (Class Loaders)
Java 프로그램 실행에 필요한 class를 jvm에 로드하기 위해서 class loader를 활용합니다. Class loader는 다음과 같이 목적에 맞게 역할이 나뉘어있습니다.
Bootstrap class loader: JVM이 실행될 때 해당 java 프로그램 실행에 필요한 기본적인 class들을 로드합니다(rt.jar 파일 내의 java.lang 등).
Extension class loader: Extension class들을 로드합니다(주로 jre/lib/ext에 위치). Extension class는 JDK가 추가적으로 제공하는 라이브러리입니다.
Application class loader: classpath에 설정된 class를 로드합니다. 프로그래머는 실행시키고자 하는 java 프로그램의 classpath를 명시할 수 있습니다.
// classpath를 직접 명시하는 방법
java -cp /path/to/classes:/path/to/jarfile MyMainClass
java -classpath /path/to/classes:/path/to/jarfile MyMainClass
// environment variable를 설정해서 classpath를 명시하는 방법
export CLASSPATH=/path/to/classes:/path/to/jarfile
// system variable을 설정해서 classpath를 명시하는 방법
java -Djava.class.path=/path/to/classes:/path/to/jarfile MyMainClassLink
Link 단계에서는 .class 파일 내의 symbolic references를 실제 메모리 주소로 변환하는 작업을 수행합니다. 단계별로 다음과 같은 작업을 수행합니다.
Verify: .class 파일이 java 스펙에 맞는지 검증합니다. Bytecode format, version number 등을 확인하는 단계입니다.
Prepare: 클래스와 static variable을 위한 메모리를 할당합니다. 중요한 점은 static variable이 default 값으로 초기화된다는 점입니다. 예를 들어 boolean 타입의 static 변수를 true로 설정하더라도 prepare 단계에서는 해당 변수는 false로 초기화됩니다.
Resolve: symbolic reference를 실제 메모리 주소로 변환합니다.
Symbolic reference란 우리가 코드를 작성하면서 사용한 class, field, method의 이름을 지칭합니다. Resolve 단계는 class, field, method 그리고 constant pool의 symbolic references를 실제 메모리 주소로 변환합니다.
Initialize
Static initializer block을 실행합니다. 위 link의 prepare 단계에서는 static 변수가 default 값으로만 초기화됐지만 initialize 단계에서는 프로그래머가 지정한 값으로 static 변수가 설정됩니다. Initialize가 완료된 이후 main 메서드가 실행됩니다.
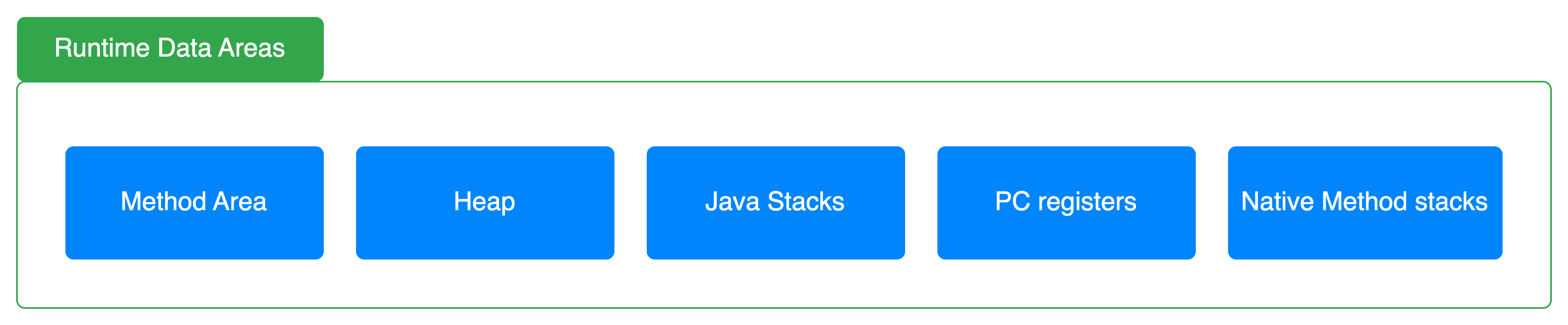
Runtime Data Areas
다음으로는 JVM 메모리 구조에 대해 살펴보겠습니다.
 JVM runtime data area의 구조
JVM runtime data area의 구조
Method Area (Metaspace)
Class level 정보를 저장하는 영역입니다. Class 정보, method 정보, static variable과 constant pool 정보를 저장합니다. Java 8부터는 기존의 method area의 한계를 극복하기 위해 method area가 제거되고 metaspace가 도입됐습니다. 기존의 method area의 경우 실행하고자 하는 java 프로그램에 클래스의 수가 너무 많을 때 "java.lang.OutOfMemoryError: PermGenspace" 에러를 발생할 확률이 컸습니다. 이는 method area가 heap의 일부 영역이었고 JVM에 할당된 메모리에 의해 최대 크기가 제한됐기 때문입니다. Metaspace는 JVM에 할당된 메모리가 아닌 system의 native 메모리를 활용하기 때문에 system의 가용 메모리에 제한을 받습니다. 따라서 method area를 활용하는 것보다 OutOfMemoryError가 발생할 확률이 낮아졌습니다.
Heap
Runtime에 생성된 object 또는 array를 저장하는 메모리 영역입니다. 모든 스레드에 의해 공유되는 영역으로 JVM 생성 시 할당됩니다. 자바 프로그램을 개발하면서 가장 많이 신경 쓰는 메모리 영역이기도 합니다. Managed 언어인 java이지만 memory leak이 발생할 수 있기 때문에 개발자는 사용하지 않는 객체의 참조가 정상적으로 해제되는지 신경 써야 합니다. 중요한 만큼 heap의 구조에 대해 상세히 살펴보겠습니다.
 VisualVM을 활용한 heap 분석
VisualVM을 활용한 heap 분석
Java의 heap 영역은 young과 old 영역으로 구분됩니다. Young은 말 그대로 최근에 생성된 객체들이 위치하는 영역이고 old 영역은 특정 threshold 이상의 기간 동안 살아남은 객체가 위치하는 영역입니다. Young 영역은 또다시 eden, s0과 s1으로 구분됩니다. s0과 s1은 survivor의 약자입니다. 객체가 새로 생성될 때 해당 객체는 eden 영역에 할당됩니다. 그리고 eden 영역이 더 이상 객체를 저장할 수 없는 경우 minor gc(garbage collection)을 거쳐 s0 또는 s1의 영역으로 살아남은 객체를 이동시킵니다. 위 사진에서 보시면 s1에 저장된 객체가 없는 것을 확인할 수 있습니다. 다음 minor gc 때 eden과 s0 영역에서 살아남은 객체가 s1으로 이동하는데 이와 같은 플로우를 지니게 된 이유는 데이터 파편화(fragmentation)를 압축(compaction) 없이 해결하기 위해서입니다. 만약 s0과 s1이 동시에 사용된다면 gc에 의해 객체가 제거되면서 메모리 영역 중간중간이 비어 파편화 현상이 발생합니다. 이를 해결하기 위해서는 일정한 간격으로 압축이 필요하지만 JVM의 경우 s0 또는 s1 중 단 하나의 영역만 사용하기 때문에 별도의 압축과정이 필요하지 않습니다.
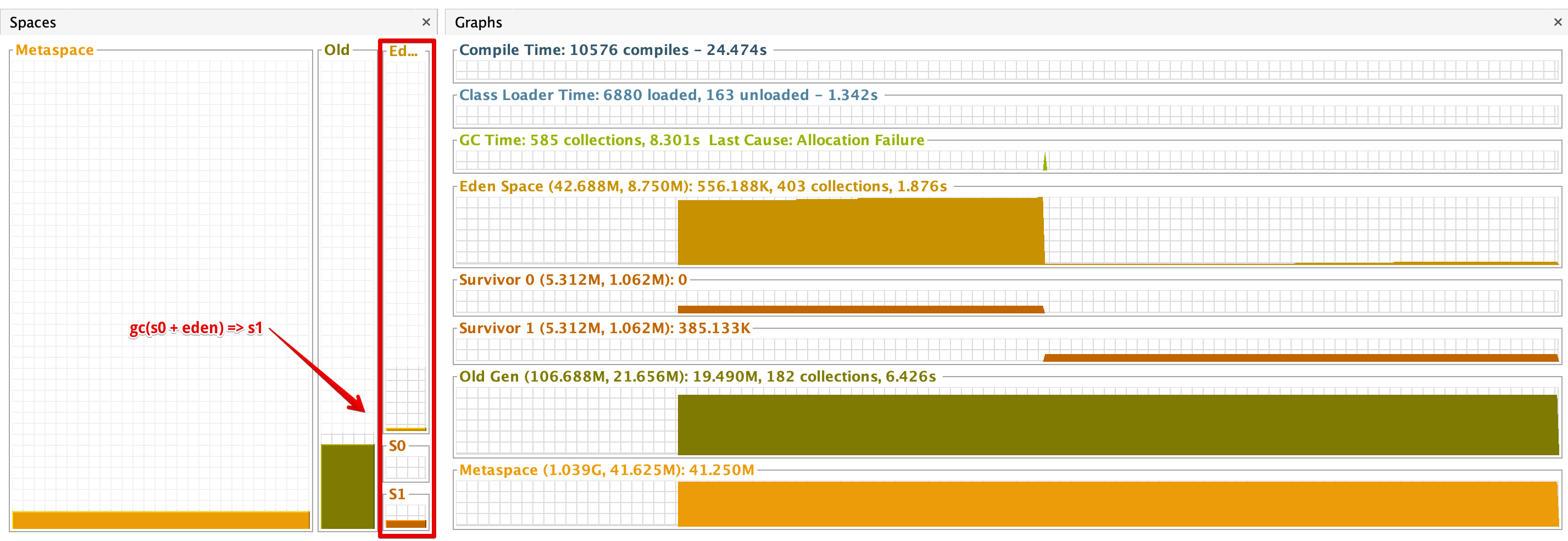 Minor gc로 인해 s0과 eden에서 살아남은 객체가 s1으로 이동
Minor gc로 인해 s0과 eden에서 살아남은 객체가 s1으로 이동
Young 영역에서 일정기간 이상 생존한 객체는 old 영역으로 승진(promote)됩니다. 만약 old 영역에 더 이상의 객체가 저장될 수 없는 경우 major gc(garbage collection) 수행합니다. 이때 application이 순간적으로 정지하는 stop the world 현상이 발생합니다. 사용하는 garbage collector의 특성에 따라 stop the world 현상이 상이할 수 있습니다.
Heap과 관련돼서 중요한 설정으로는 -Xmx와 -Xms가 있습니다. Xmx 설정을 통해 heap의 최대 크기를 제한할 수 있고 Xms 설정을 통해 heap의 초기(최소) 크기를 설정할 수 있습니다. Xmx 값을 시스템 메모리보다 크게 설정하면 swap이 발생하여 시스템 전체적인 성능이 악화되거나 시스템이 다운될 수 있습니다. 따라서 Xmx값을 시스템 메모리보다 작게 설정하는 게 권고됩니다. 두 번째 권고 사항으로는 Xmx와 Xms 값을 동일하게 설정하는 것인데 이는 만약 두 설정값이 다른 경우 힙의 크기가 Xms에 도달했을 때 운영체제에게 추가 메모리를 요청함으로써 발생하는 오버헤드를 줄이기 위함입니다. 프로덕션 환경에서 운영해 보면 결국 JVM이 사용하는 메모리는 Xms를 넘어 Xmx를 향해 증가하기 때문에 Xms와 Xmx를 동일한 값으로 설정하는 것은 성능적인 관점에서 효율적일 수 있습니다.
https://developer.jboss.org/thread/149559
Why to set -Xms and -Xmx to the same value?| JBoss.org Content Archive (Read Only)
Java Stacks
메서드 실행 시 생성되는 function call frame을 저장하기 위해 사용됩니다. Function call frame에는 해당 메서드에서 생성된 지역 변수 등이 저장됩니다. Thread별로 stack 영역이 할당됩니다. 만약 이 영역에 너무 많은 데이터가 저장되는 경우 stack overflow error가 발생할 수 있습니다. 또한 JVM의 -Xss 옵션을 활용해서 stack의 최대 깊이를 제한할 수 있습니다.
PC Registers
Program counter을 저장하기 위해 사용되는 영역입니다. 특정 thread의 실행 위치를 표시하므로 각각의 thread별로 pc register가 생성됩니다.
Native Method Stacks
Thread에서 native method를 호출하는 경우, 즉 java 이외의 언어로 작성된 코드를 호출하는 경우 사용됩니다. Thread별로 생성됩니다.
Execution Engine
Execution engine은 JNI를 활용해 운영체제의 함수를 호출합니다. 이 과정에서 사용되는 각각의 컴포넌트에 대해 살펴보겠습니다.
JNI(Java Native Interface)는 JVM에서 실행 중인 java 코드에서 다른 언어(C/C++)로 작성된 코드를 호출할 수 있도록 도와주는 프레임워크입니다. 자바의 기능만으로 수행할 수 없는 로직 또는 성능적인 측면에서 다른 언어를 사용하는 게 효율적일 때 사용됩니다.
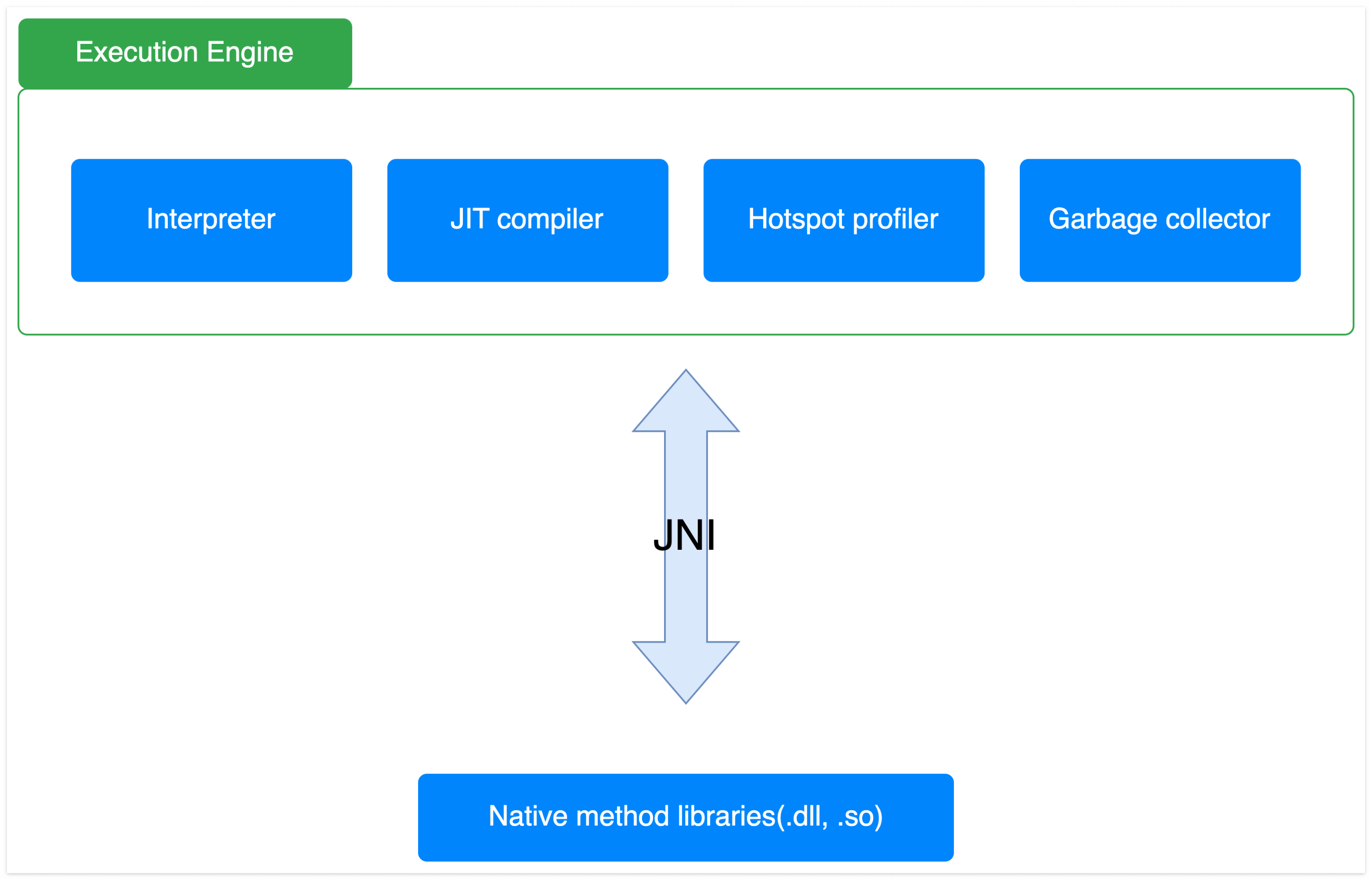 Execution engine
Execution engine
Interpreter
Bytecode를 읽어 native code(machin code)로 변환하는 역할을 담당합니다. 자주 실행되는 코드가 실행될 때마다 매번 interpreter에 의해 변환되면 비효율적입니다. 이러한 단점을 극복하기 위해 JVM은 JIT compiler을 활용합니다.
JIT Compiler
JIT은 just-in-time의 약자입니다. 즉 적절한 시기에 bytecode를 캐싱하고 최적화함으로써 자주 호출되는 코드가 interpreter에 의해 여러 번 변환되는 작업의 수를 줄일 수 있습니다. JIT compiler는 tiered compilation을 활용함으로써 단계별로 최적화하는 정도가 다릅니다. 현업에서 발생할 수 있는 문제 중 하나는 java 애플리케이션이 시작한 지 얼마 되지 않았을 때 코드가 충분히 캐싱 또는 최적화되지 않아 응답지연이 발생하는 점입니다. 이는 JVM warmup을 통해 해결할 수 있습니다. 카카오에서 JVM warmup을 통해 응답지연 현상을 어떻게 해결했는지 좋은 영상이 있어 공유드립니다.
https://www.youtube.com/watch?v=CQi3SS2YspY&t=1s
Profiler
Interpreter에 의해 자주 변환되는 코드를 파악하는 데 사용됩니다.
Garbage Collector
사용되지 않는 객체에 할당한 메모리를 해제하지 않으면 언젠가는 OutOfMemoryError에 의해 프로세스가 종료될 수 있습니다. 자바의 경우 참조되지 않는 객체에 할당된 메모리를 garbage collector을 활용해 해제합니다. 그럼 garbage collector은 어떻게 동작하는지 살펴보겠습니다.
"Mark and Sweep"은 다양한 garbage collector들의 동작원리입니다. Mark 단계에서는 live 스레드에서 참조하는 객체들을 표시하고 sweep 단계에서 참조되지 않는 객체의 메모리를 해제합니다. Garbage collector의 특성에 따라 garbage collection 중에 애플리케이션이 동작하는 방식이 달라집니다. 다음으로는 어떤 garbage collector가 존재하는지 살펴보겠습니다.
Serial GC
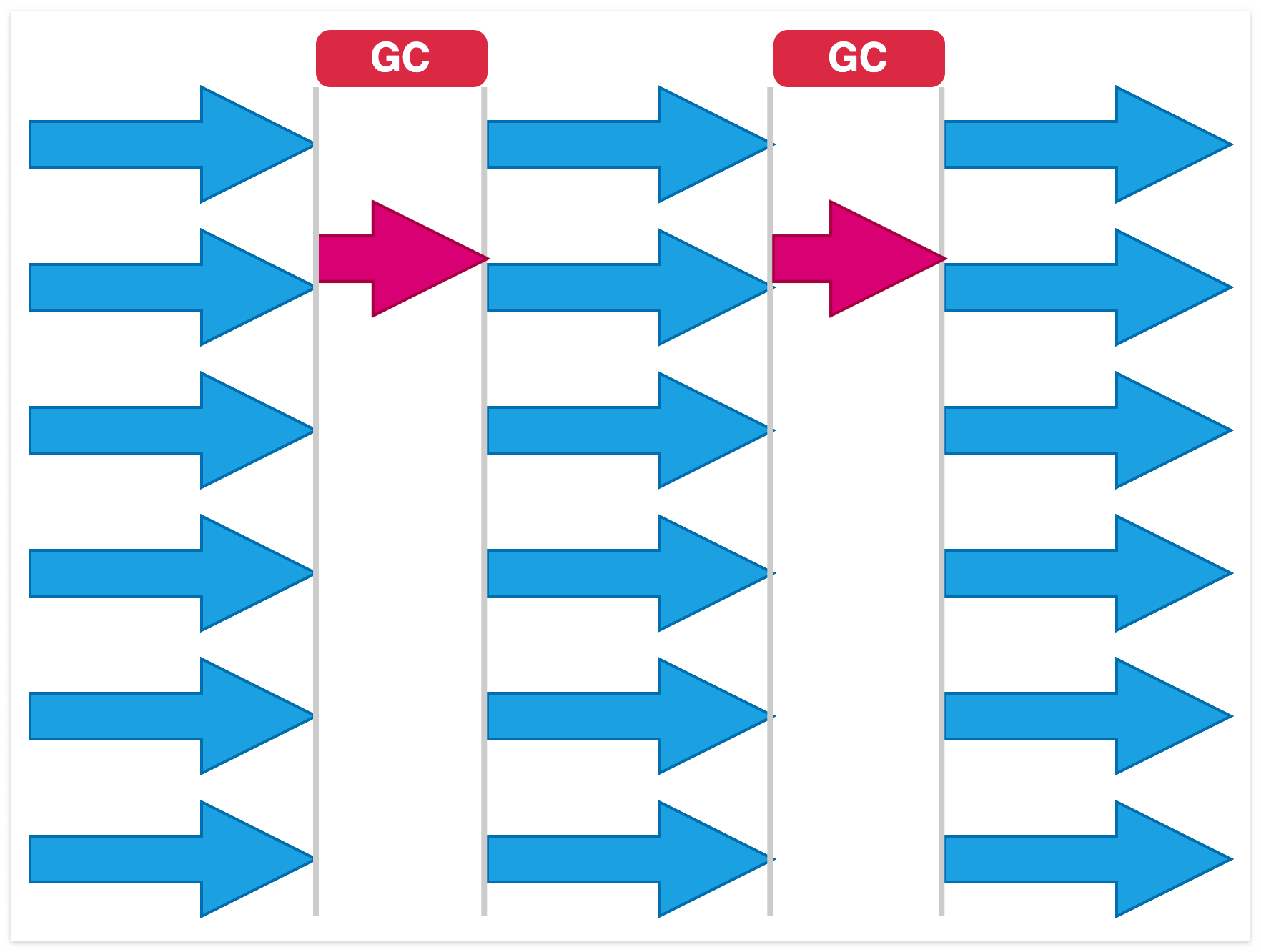 Serial GC
Serial GC
단일 스레드로 mark and sweep을 통해 garbage collection을 수행합니다.
Parallel GC
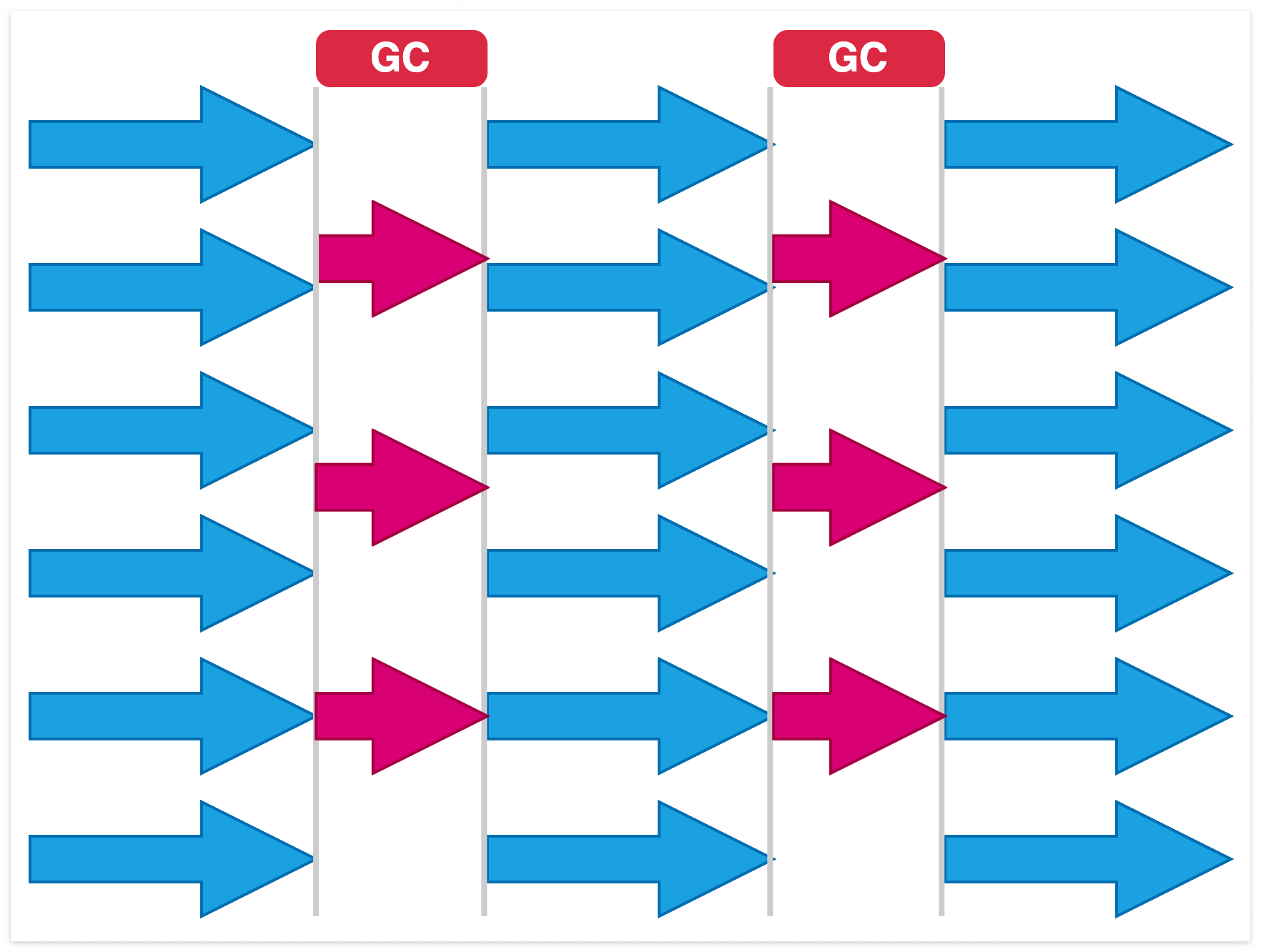 Parallel GC
Parallel GC
Serial collector와 동작원리는 유사하지만 여러 스레드를 활용해서 mark and sweep을 수행합니다.
CMS(Concurrent Mark and Sweep) GC
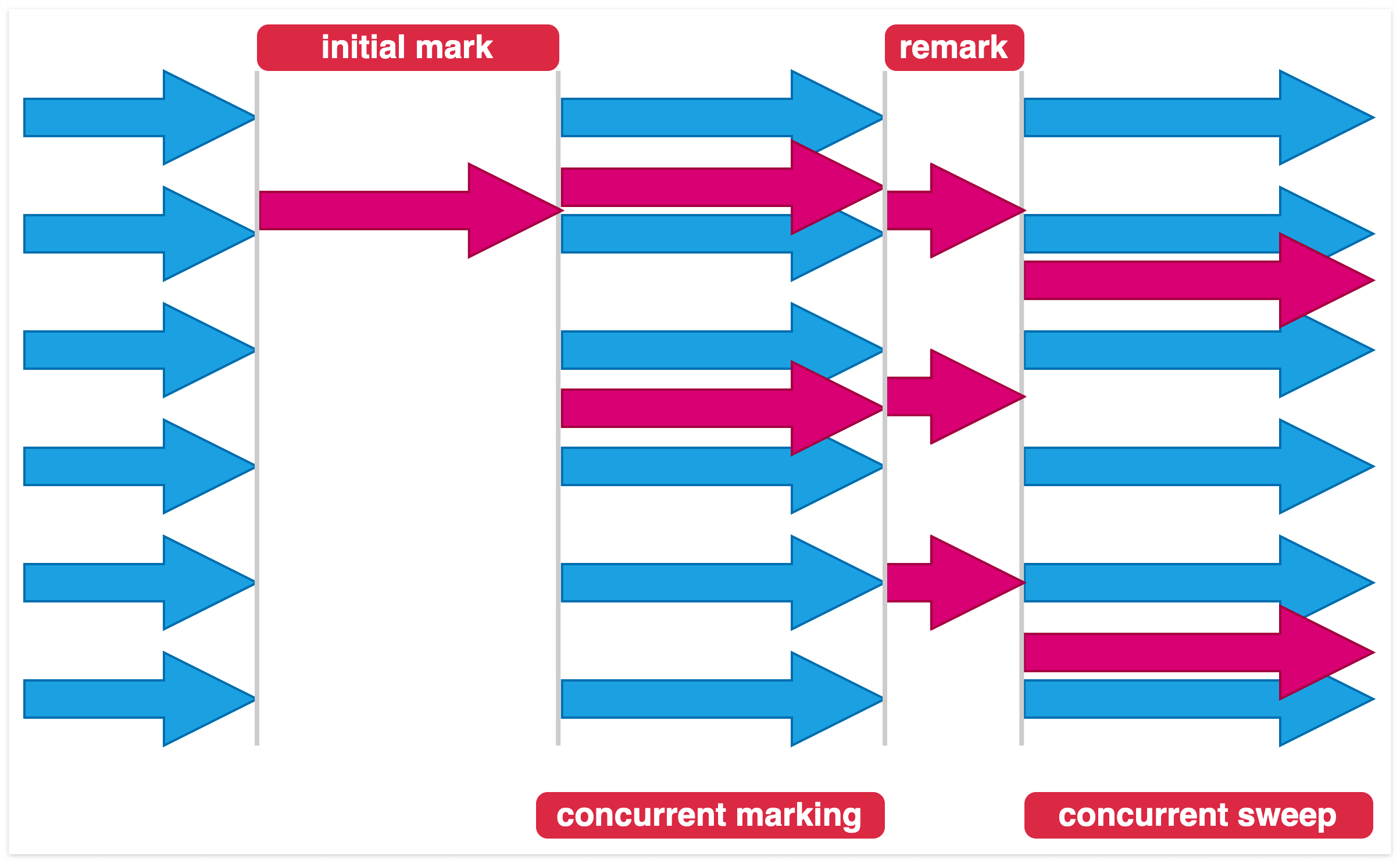
애플리케이션의 중단 없이 mark and sweep이 가능한 garbage collector입니다. 애플리케이션 중단을 최소화하기 위해 사용됩니다. 물론 CMS라고 stop the world 현상이 없지는 않습니다. Initial mark 단계와 remark 단계에서는 stop the world 현상이 발생합니다.
CMS는 다음 순서로 동작합니다.
1. Initial mark: Old 영역의 참조되고 있는 객체를 표시합니다. 짧게나마 stop the world 현상이 발생할 수 있습니다.
2. Concurrent marking: 자바 애플리케이션 중단 없이 참조되는 객체들을 표시합니다.
3. Remark: concurrent marking 단계에서 놓친 참조되는 객체들을 표시합니다. Stop the world 현상이 발생할 수 있습니다.
4. Concurrent sweep: 참조되지 않는 객체의 메모리를 해제합니다.
G1(Garbage First) GC
 G1 GC
G1 GC
Java 9 이상부터는 기본 설정되는 GC로 큰 heap에서도 garbage collection에 소요되는 시간을 최소화하기 위해 개발된 garbage collector입니다. G1 GC는 heap을 작은 영역으로 나눠 각 영역에 대해 독립적인 garbage collection을 수행합니다. 여러 영역 중 garbage가 가장 많은 영역을 골라 우선적으로 garbage collection을 수행합니다. 추가로 G1 GC는 "Garbage-First Virtual Space"라는 자료구조를 활용해서 heap의 어떤 영역이 가장 많은 garbage를 가졌는지 추적합니다.
G1 GC는 다음 순서로 동작합니다.
1. Initial mark: 애플리케이션 중단 없이 현재 스레드에서 참조되고 있는 객체를 표시합니다.
2. Concurrent marking: Live 스레드로부터 참조되는 객체를 추가로 찾아 marking 하는 단계입니다.
3. Remark: 짧은 stop the world 현상이 발생할 수 있습니다. 이는 remark 단계에서 live 스레드로부터 참조되는 객체를 정확히 표시하기 위함입니다.
4. Garbage collection: Heap에서 가장 많은 garbage를 가진 영역들에 대해 우선적으로 garbage collection을 수행합니다. 애플리케이션 중단 없이 수행됩니다.
5. Clean up: 파편화를 제거하기 위한 압축 등 garbage collection 이후 수행돼야 하는 작업을 수행합니다.
마무리
이번 포스팅을 통해 우리가 작성한 java가 어떻게 실행되고 java를 실행하는데 필요한 다양한 소프트웨어에 대해 살펴봤습니다. JVM은 자바뿐 아니라 Kotlin, Scala 등 다양한 언어의 실행환경이기 때문에 그 내부원리를 잘 이해하는 게 중요하다고 생각합니다.
답변 0